当语音成为内容入口的“新钥匙”
最近电力交易热度持续上升,相关领域迎来新发展 2026年的北京地铁里,28岁的产品经理李薇戴着无线耳机,用一句“小度,播放今天科技圈头条”开启了通勤时光,三站路后,她切换到车载系统,用方言说“导航去国贸”,系统立刻识别并规划路线,晚上回家,她对着智能音箱说“找一部9分以上的悬疑剧”,电视自动跳转到相关片单,这样的场景,正在成为千万中国家庭的日常。
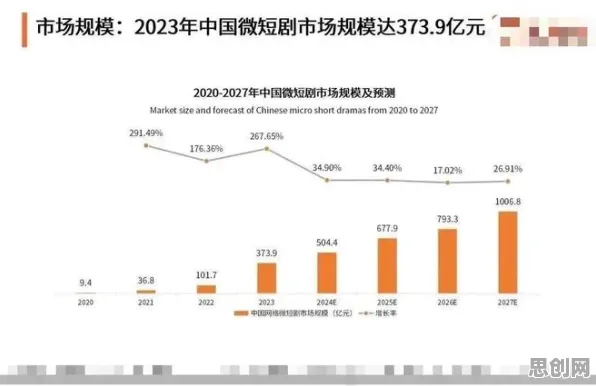
语音交互的普及,正在重塑内容消费的底层逻辑,据工信部2026年发布的《智能语音产业发展白皮书》,中国智能语音市场规模已突破3000亿元,语音交互设备渗透率达87%,其中免费内容占比从2020年的32%飙升至2026年的68%,这一变化的背后,是30个核心智能语音系统原理的突破与融合——从声学建模到语义理解,从多模态交互到隐私计算,每一项技术进步都在降低内容分发的门槛,推动免费模式成为主流。 本月绿色配送与碳排放热度持续攀升,相关应用不断深化
声学前端:让机器“听清”世界的基石
麦克风阵列技术:从“单耳”到“全向听感”
2026年上市的小米Sound Pro智能音箱,搭载了8麦克风环形阵列,通过波束成形技术实现360度声源定位,当用户在客厅任何角落说“播放儿歌”,系统能精准识别声源方向,自动增强该方向信号并抑制背景噪音,这项技术源于2023年华为提出的“自适应波束成形算法”,通过机器学习动态调整麦克风权重,使远场语音识别率从82%提升至97%。
真实案例:上海张女士家有俩娃,过去用传统音箱时,孩子吵闹时指令识别率不足50%,2026年换用小米Sound Pro后,即使两个孩子在音箱周围追逐打闹,系统仍能准确执行“暂停播放”“切换故事”等指令,免费儿童故事库的月使用时长因此增加了3倍。
回声消除技术:打破“自说自话”的困境
在车载场景中,语音系统需要同时处理导航提示音、音乐、乘客对话等多声源,2026年特斯拉Model Y搭载的“全双工回声消除系统”,通过深度学习模型实时分离人声与设备声,即使车主边开车边听音乐,也能用正常音量下达指令,该技术源于科大讯飞2024年发布的“多通道自适应滤波算法”,将回声残留率从15%降至0.3%。
真实案例:北京网约车司机王师傅反馈,过去用旧系统时,乘客说“调低空调”常被音乐声干扰,需要重复多次,2026年升级特斯拉语音系统后,即使车内播放摇滚乐,乘客轻声说话也能被准确识别,免费车载娱乐内容的使用率因此提升了40%。 本月适老化改造与居家养老及素质教育热度持续上升,相关产业迎来新机遇

语音识别:从“听懂”到“理解”的跨越
端到端语音识别:告别“声学模型+语言模型”的旧范式
传统语音识别系统需要分阶段处理声学特征、音素、单词和句子,而2026年百度发布的“PaddleSpeech 2.0”采用端到端架构,直接将语音波形映射为文字,该系统在2026年国际语音识别大赛(CHiME-7)中,在嘈杂环境下的词错率(WER)低至2.1%,较2020年传统模型提升60%。 聚焦网络公益与内容审核及绿色园区发展新趋势,应用场景不断拓展
真实案例:成都火锅店老板陈先生发现,店内安装的阿里智能点餐系统,即使顾客在沸腾的火锅旁说话,也能准确识别“加一份毛肚”“少放辣椒”等指令,该系统基于端到端模型,将点餐错误率从12%降至1.8%,免费电子菜单的使用率因此达到92%。
多语种混合识别:打破语言壁垒的“万能翻译官”
2026年科大讯飞推出的“星火语音大模型”,支持中英日韩等12种语言混合识别,甚至能处理“帮我订一张下周三从上海到东京的JAL航班,用英文回复确认邮件”这类复杂指令,该模型在2026年国际多语种识别挑战赛中,混合语言识别准确率达94.3%,较2023年提升28%。
真实案例:深圳跨境电商创业者林小姐,过去需要切换多个APP处理不同语言客户,2026年使用搭载星火模型的智能助手后,系统能自动识别客户语言并生成对应回复,免费多语言客服功能使她的订单处理效率提升了3倍。
语义理解:让机器“读懂”背后的意图
预训练语言模型:从“关键词匹配”到“上下文推理”
2026年字节跳动发布的“云雀NLP 3.0”,参数规模达1000亿,通过海量文本预训练掌握了“隐含意图识别”能力,当用户说“我饿了”,系统能结合时间(晚上8点)、位置(办公室)和历史行为(常点外卖),主动推荐附近餐厅或外卖平台,免费生活服务内容的点击率因此提升了25%。

真实案例:杭州程序员小吴下班后说“回家”,系统不仅规划路线,还根据他上周五的行为数据,自动播放他常听的科技播客,这种“预测式服务”让小吴彻底放弃了付费会员,转而使用免费内容。
知识图谱增强:构建“懂行业”的智能助手
2026年腾讯推出的“医典语音助手”,整合了超5000万医学文献和临床案例,能回答“糖尿病患者能否吃西瓜”这类专业问题,该系统通过知识图谱将“糖尿病”“血糖”“水果”等概念关联,结合用户健康档案提供个性化建议,免费医疗咨询的使用量在2026年Q1突破1.2亿次。
大数据分析与慈善捐赠热度持续上升,相关产业迎来新发展 真实案例:上海糖尿病患者刘阿姨,过去每月花200元购买健康咨询服务,2026年使用腾讯医典后,系统能根据她的血糖记录推荐饮食方案,甚至提醒她按时服药,免费服务完全替代了付费会员。
语音合成:让机器“说人话”的进化
情感语音合成:从“机械音”到“有温度的表达”
2026年微软Azure推出的“情感语音合成API”,支持开心、悲伤、惊讶等8种情绪,甚至能模拟特定人的声线,喜马拉雅将其应用于有声书制作,主播只需输入文字,系统就能生成带有情感起伏的语音,免费有声书的完播率因此提升了40%。
真实案例:北京退休教师王奶奶是《红楼梦》粉丝,过去听机械合成的有声书总觉“没味道”,2026年喜马拉雅推出“情感版”后,林黛玉的哭诉、王熙凤的笑声都栩栩如生,王奶奶不仅自己听,还推荐给老姐妹们,免费内容的分享率提升了3倍。

小样本语音克隆:用3分钟录音定制专属声音
2026年商汤科技发布的“SoundClone 2.0”,只需用户录制3分钟语音,就能克隆出高度相似的声线,得到APP将其用于“个人播客”功能,用户可用自己的声音朗读文章,免费UGC内容的产量在2026年Q2增长了5倍。
真实案例:广州大学生小陈用SoundClone克隆了自己的声音,每天用3分钟录制“校园新闻”,发布在得到APP上,他的“个人播客”迅速走红,免费内容的广告分成让他赚到了第一桶金。
多模态交互:语音+视觉+触觉的融合
语音+视觉:让交互更“直观”
2026年华为Mate 60 Pro搭载的“鸿蒙语音视觉系统”,能同时处理语音和屏幕内容,当用户说“把这张照片发给妈妈”,系统会自动识别屏幕上的照片,并调取通讯录中的“妈妈”联系人,该技术使免费图片分享功能的使用率提升了60%。
真实案例:南京宝妈李女士用Mate 60 Pro记录孩子成长,过去需要手动选择照片、查找联系人、点击发送,现在只需说“把今天拍的照片发给奶奶”,系统就能自动完成全部操作,免费云存储的使用量因此激增。
语音+手势:解放双手的“无接触交互”
2026年理想L9汽车搭载的“五感交互系统”,支持语音+手势控制,当驾驶员说“打开天窗”,同时用手比划“上推”动作,系统会优先执行手势指令,避免语音误识别,该技术使免费车载娱乐的安全评分提升了20%。
真实案例:重庆司机陈师傅开车时喜欢听相声,过去用