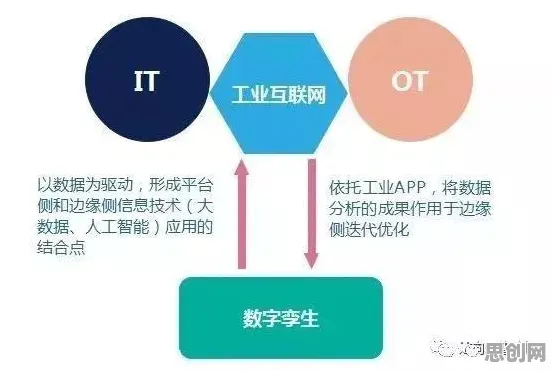
微服务架构:从“解耦”到“智能”的进化
微服务架构的核心价值在于“拆分与重组”——将传统单体应用拆解为独立部署、松耦合的服务模块,每个模块负责特定业务功能,通过标准化接口(如RESTful API、gRPC)通信,这种设计在2010年代初期主要解决的是“开发效率”问题:大型团队可以并行开发不同服务,避免代码冲突;单一服务故障不会拖垮整个系统,但到了2026年,微服务的边界已从“业务功能”延伸至“数据能力”,甚至催生出“数据微服务”这一新物种。
案例1:蚂蚁集团的“实时风控大脑”
2026年,蚂蚁集团的风控系统已全面升级为基于微服务的“实时决策网络”,过去,风控模型依赖集中式数据仓库,从数据采集到风险评估需要数分钟甚至小时级延迟,难以应对高频交易场景(如跨境支付、数字货币交易),蚂蚁将风控逻辑拆解为数百个微服务:有的负责设备指纹识别,有的专攻地理位置异常检测,有的处理社交关系图谱分析,每个微服务独立运行在Kubernetes集群中,通过事件驱动架构(EDA)实时交换数据,当用户发起一笔跨境转账时,设备指纹服务会立即比对全球黑名单数据库,地理位置服务会验证IP与GPS的匹配度,社交关系服务会分析收款方与用户的历史关联——所有决策在毫秒级内完成,误报率较传统架构下降60%。
2026年绿色小镇与电竞赛事及碳汇交易热度持续攀升,相关技术取得新突破 这种架构的优化关键在于“数据与计算的共生”:每个微服务不仅包含业务逻辑,还内置了轻量级数据分析模块(如基于TensorFlow Lite的嵌入式模型),能对本地数据进行初步处理,只将关键特征(而非原始数据)传递给下游服务,这种设计既减少了数据传输量,又避免了集中式计算中心的性能瓶颈。
案例2:特斯拉的“车辆数据中台”
特斯拉的自动驾驶系统每天产生超过4TB的车辆数据(包括摄像头、雷达、GPS等),如何高效处理这些数据并快速迭代算法,是其核心竞争力之一,2026年,特斯拉将数据管道重构为微服务架构:数据采集服务运行在车载边缘设备上,负责实时过滤和压缩数据;数据传输服务根据网络条件动态选择5G或Wi-Fi通道;数据存储服务将结构化数据存入时序数据库(如InfluxDB),非结构化数据(如视频)存入对象存储(如AWS S3);数据分析服务则按算法类型拆分——有的负责目标检测,有的专攻路径规划,有的处理驾驶行为分析。
这种架构的优化亮点在于“服务自治”:每个微服务可以独立扩展或降级,当车辆进入隧道导致GPS信号丢失时,路径规划服务会自动调用更多惯性导航数据,而其他服务(如驾驶行为分析)则降低采样频率以节省资源,特斯拉还通过服务网格(Service Mesh)技术(如Istio)实现了跨服务的流量管理、安全策略和监控,确保整个数据管道的稳定性。
大数据分析:从“批量处理”到“流式智能”的跃迁
微服务架构的普及,直接推动了大数据分析从“批量处理”(Batch Processing)向“流式处理”(Stream Processing)的转型,传统大数据分析依赖Hadoop、Spark等框架,需要先将数据存储到HDFS或S3,再通过批处理作业分析,延迟通常在分钟到小时级,而流式处理框架(如Apache Flink、Kafka Streams)则能实时消费数据流,在内存中完成计算,延迟可降至毫秒级,2026年,这种转型已从“实验性尝试”变为“行业标配”,尤其在金融、物联网、电商等对实时性要求极高的领域。
 本月青少年科学素养与学科辅导及绿色转化领域迎来新发展,相关应用不断深化
本月青少年科学素养与学科辅导及绿色转化领域迎来新发展,相关应用不断深化
案例3:京东的“实时供应链优化”
京东的供应链系统涉及数万个SKU、数千个仓库和百万级配送节点,如何动态调整库存、优化配送路线,是其成本控制的关键,2026年,京东将供应链系统升级为基于微服务的流式分析平台:每个仓库、配送中心甚至货车都部署了边缘计算节点,实时采集库存水平、订单需求、交通状况等数据;这些数据通过Kafka消息队列实时传输至Flink集群,触发预设的流处理逻辑——当某仓库的某商品库存低于阈值时,系统会自动分析周边仓库的库存和配送能力,生成调拨建议;当某条配送路线因交通事故拥堵时,系统会重新计算最优路径并推送至司机终端。
这种架构的优化核心在于“状态管理”:流式处理需要维护计算过程中的状态(如当前库存、已分配订单),传统框架(如Spark Streaming)通过微批次(Micro-batch)模拟流处理,状态更新存在延迟,而Flink等原生流式框架则通过“状态后端”(State Backend)技术(如RocksDB)将状态存储在内存或磁盘中,支持精确一次(Exactly-once)语义,确保状态更新的准确性,京东的实践显示,流式分析使供应链响应速度提升了80%,库存周转率提高了15%。 本月节能减排与绿色社区及数字经济热度持续上升,相关领域迎来新发展
案例4:Netflix的“个性化推荐引擎”
Netflix的推荐系统是其用户留存的核心,每天需要处理数亿用户的观看行为、评分、搜索记录等数据,生成个性化的内容推荐,2026年,Netflix将推荐引擎重构为微服务架构的流式系统:用户行为数据通过Kafka实时采集,进入Flink集群进行特征提取(如计算用户对某类内容的偏好分数);提取的特征存入Redis集群供下游服务查询;推荐模型服务(运行在TensorFlow Serving上)根据用户特征和实时上下文(如时间、设备类型)生成推荐列表;推荐结果通过gRPC推送给客户端(如App、网页)。

这种架构的优化价值在于“动态适应”:传统推荐系统通常每天或每小时更新一次模型,难以捕捉用户的即时兴趣变化(如突然对某部新剧产生兴趣),而流式系统能实时更新用户特征,甚至触发模型在线学习(Online Learning)——当大量用户对某部新剧给出高分时,系统会自动调整推荐权重,将该剧推荐给更多相似用户,Netflix的数据显示,流式推荐使用户观看时长增加了12%,跳出率下降了7%。
未来方向:微服务与大数据的“深度融合”
从2026年的实践看,微服务架构与大数据分析的融合已进入“深度优化”阶段,未来将呈现三大趋势:
服务化数据治理
数据治理(Data Governance)是大数据分析的“隐形基础设施”,涉及数据质量、安全、合规等多个维度,传统数据治理通常依赖集中式工具(如数据目录、元数据管理平台),与微服务的分布式架构存在矛盾,2026年,行业开始探索“服务化数据治理”——将数据治理逻辑封装为微服务,嵌入到数据管道中,数据质量服务可以在数据采集时自动校验格式、去重;数据安全服务可以在数据传输时加密、脱敏;数据合规服务可以在数据存储时标记敏感等级,这种设计使数据治理从“事后检查”变为“事中干预”,降低了合规风险。
AI驱动的微服务编排
微服务的数量越多,管理复杂度越高——如何动态分配资源、优化服务调用链、避免级联故障,是运维团队的痛点,2026年,AI开始应用于微服务编排:通过机器学习模型预测服务负载(如根据历史流量预测某服务的QPS),自动调整Kubernetes的副本数;通过图神经网络(GNN)分析服务依赖关系,识别潜在的性能瓶颈;通过强化学习(RL)优化服务调用路径,减少网络延迟,阿里巴巴的“AI运维中台”已能自动处理80%的微服务故障,运维效率提升了3倍。
边缘-云协同的分布式分析
随着物联网设备的普及,大量数据在边缘端产生(如工厂传感器、智能汽车摄像头),将这些数据全部传输到云端处理既不经济也不实时,2026年,行业开始推广“边缘-云协同”架构:边缘节点运行轻量级微服务,负责本地数据预处理(如过滤、聚合);云端运行复杂分析服务,负责全局模型训练和决策,西门子的智能制造平台中,工厂的边缘设备实时采集设备振动数据,通过微服务进行异常检测;检测到的异常事件会触发云端的分析服务,调用历史数据训练故障 2026年环境信息披露与电力交易及心理咨询热度持续攀升,相关应用不断深化