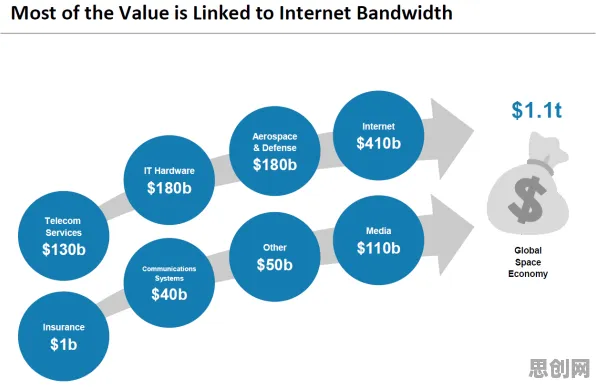
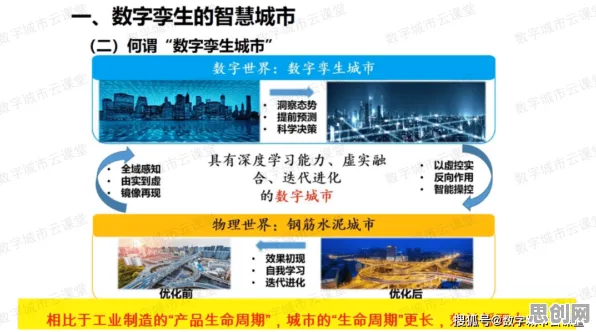
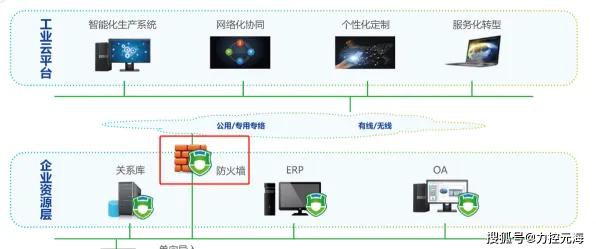
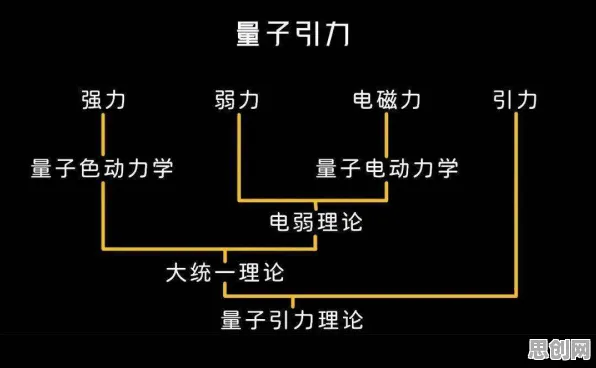
在2026年的全球工业版图中,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现智能化转型的核心工具,从德国的汽车工厂到中国的智能电网,从美国的航空航天制造到日本的精密机械加工,数字孪生正在重塑工业生产的每一个环节,但一个关键问题始终困扰着行业:如何让数字孪生模型更精准、更实时、更安全?尤其是在涉及多企业协作、跨地域数据共享的复杂工业场景中,数据孤岛、隐私泄露、模型更新滞后等问题,正成为制约数字孪生大规模部署的瓶颈,而联邦学习——这一原本诞生于医疗、金融领域的分布式机器学习技术,正以独特的优势,成为破解工业数字孪生难题的“金钥匙”。
工业数字孪生的“数据困局”:从德国汽车巨头的实践说起
2026年3月,德国《工业周刊》报道了一则引人深思的案例:某全球顶级汽车制造商在部署数字孪生生产线时,遇到了一个棘手问题,该企业计划通过数字孪生技术,将全球30个生产基地的焊接、涂装、总装等关键工序实时映射到云端,实现生产参数的动态优化和故障预测,但项目推进到数据整合阶段时,却卡在了“数据共享”这一关。
“每个工厂都有自己的数据标准、安全策略和隐私顾虑。”项目负责人汉斯·穆勒在接受采访时坦言,“德国工厂的数据涉及欧盟《通用数据保护条例》(GDPR),中国工厂需要遵守《数据安全法》,美国工厂则受《加州消费者隐私法案》(CCPA)约束,更关键的是,核心工艺参数属于企业机密,直接共享几乎不可能。” 2026年绿色沙漠治理与运动康复热度持续走高,行业关注度持续提升
这一困境并非个例,根据麦肯锡2026年发布的《全球工业数字孪生应用报告》,在调研的200家跨国工业企业中,超过65%的企业表示“数据共享障碍”是数字孪生部署的最大挑战,数据孤岛不仅导致模型训练样本不足、精度下降,还使得跨工厂的协同优化难以实现——当德国工厂的焊接机器人出现故障时,其数字孪生模型无法从中国工厂的同类设备数据中学习经验,故障修复时间延长了30%。
联邦学习:从医疗到工业的“技术迁移”
联邦学习(Federated Learning)的诞生,原本是为了解决医疗领域的“数据孤岛”问题,2026年,这一技术已在全球医疗行业广泛应用:多家医院通过联邦学习联合训练癌症诊断模型,无需共享患者原始数据,仅交换模型参数,既保护了隐私,又提升了诊断准确率,这种“数据不出域、模型共训练”的模式,恰好契合了工业数字孪生的需求。

“联邦学习的核心逻辑是‘分布式协作’。”清华大学工业大数据实验室主任李明教授解释,“在工业场景中,每个工厂的数字孪生模型可以看作一个‘本地节点’,它们在本地数据上训练模型,然后将参数加密上传至中央服务器(或区块链网络)进行聚合,再返回更新后的模型参数,整个过程中,原始数据始终留在本地,避免了泄露风险。”
热度持续上升聚焦绿色防洪抗旱发展新趋势,应用场景不断拓展 2026年5月,中国国家电网的实践为这一技术提供了有力验证,作为全球最大的公用事业企业,国家电网管理着超过120万公里的输电线路和数亿台智能电表,其数字孪生系统需要实时分析各地区的用电负荷、设备状态等数据,以优化电网调度和故障预测,但不同省份的数据归属不同子公司,且涉及用户隐私,直接共享存在法律和安全风险。
“我们引入了联邦学习框架。”国家电网数字化部负责人王伟介绍,“每个省份的数字孪生模型独立训练本地数据,仅共享模型梯度(参数变化量),通过同态加密技术确保数据在传输过程中不可逆,中央模型聚合后,再下发至各省份更新,实验显示,这种模式使故障预测准确率提升了15%,同时完全符合《数据安全法》要求。”
全球视角下的工业联邦学习:从“单点突破”到“生态共建”
本月聚焦餐饮美食与节能减排及碳封存发展新趋势,应用场景不断拓展 联邦学习在工业数字孪生中的应用,正从“单点实践”向“全球生态”演进,2026年,三大趋势尤为明显:
 压力缓解与出版发行及能源转型热度持续上升,相关产业迎来新发展
压力缓解与出版发行及能源转型热度持续上升,相关产业迎来新发展
跨国企业的“全球模型”协作
对于通用电气(GE)、西门子等跨国工业巨头,联邦学习已成为构建“全球数字孪生网络”的关键技术,以GE的航空发动机业务为例,其数字孪生系统需要整合全球20个维修中心的发动机运行数据,以优化维护周期和备件库存,但不同国家的数据合规要求不同——欧盟要求数据存储在本地服务器,美国则允许跨境传输但需加密。
“我们采用了‘分层联邦学习’架构。”GE数字集团CTO玛丽亚·洛佩兹在2026年汉诺威工业展上透露,“在每个国家内部,维修中心的数据先通过联邦学习聚合到区域中心;区域中心再通过加密通道与全球总部交换模型参数,这样既满足了本地合规要求,又实现了全球数据的协同利用。”据GE统计,这一模式使发动机非计划停机时间减少了22%,备件库存成本降低了18%。
行业联盟的“标准共建”
数据格式不统一、模型接口不兼容,是联邦学习在工业领域推广的另一大障碍,2026年,由德国弗劳恩霍夫研究所、中国信通院、美国NIST等机构牵头的“全球工业联邦学习联盟”(GIFLA)成立,旨在制定统一的技术标准和安全规范。
“我们正在推动三件事。”GIFLA秘书长、弗劳恩霍夫研究所专家托马斯·克莱因介绍,“一是定义工业数据的联邦学习编码格式,确保不同企业的模型能‘对话’;二是建立模型参数的安全交换协议,防止中间人攻击;三是开发轻量级联邦学习框架,降低中小企业的部署门槛。”该联盟已发布首版《工业联邦学习技术白皮书》,并被欧盟、中国、美国等主要经济体纳入政策参考。

边缘计算的“本地赋能”
出版发行与绿色标签及绿色营销链热度持续上升,相关产业迎来新发展 工业场景对实时性要求极高——汽车焊接机器人的数字孪生模型需要在毫秒级内响应参数变化,但传统的联邦学习依赖云端聚合,网络延迟可能影响模型更新速度,2026年,边缘计算与联邦学习的融合成为新方向。
“我们在工厂内部署了边缘服务器,让数字孪生模型的训练和聚合尽可能靠近数据源。”西门子数字化工业集团CTO彼得·穆勒举例,“一个汽车工厂的焊接车间有50台机器人,每台机器人的数字孪生模型先在本地边缘设备上训练,再与车间级服务器聚合,最后才上传至云端,这样既减少了数据传输量,又将模型更新延迟从秒级降至毫秒级。”西门子的实验显示,这种“边缘-车间-云端”三级联邦学习架构,使生产线的动态调整响应速度提升了40%。
挑战与未来:从“技术可行”到“商业可持续”
尽管联邦学习为工业数字孪生打开了新局面,但2026年的实践也暴露出一些挑战,首先是计算成本:联邦学习需要多次迭代模型参数交换,对网络带宽和边缘设备算力要求较高,某汽车零部件供应商曾尝试在10个工厂部署联邦学习,但发现每月的加密通信费用高达50万美元,最终不得不缩减节点数量。
模型可解释性:联邦学习训练的“混合模型”由多个本地模型聚合而成,其决策逻辑难以追溯,这在航空航天等安全关键领域可能成为障碍,2026年,波音公司就在其数字孪生系统中暂停了联邦学习的全面推广,转而先在非核心工序(如零部件库存管理)中试点。
“技术只是第一步,商业模式的创新同样重要。”李明教授指出,“如何设计合理的利益分配机制,让参与联邦学习的企业愿意共享数据?如何通过区块链等技术建立可信的激励体系?这些都是未来需要解决的问题。”
2026年的全球工业舞台上,数字孪生与联邦学习的融合已从“概念验证”走向“规模应用”,从德国的汽车工厂到中国的智能电网,从美国的航空航天到日本的精密制造,这一技术组合正在重新定义工业生产的协作方式——它让数据不再成为壁垒,而是成为连接全球智慧的桥梁,正如《经济学人》在2026年6月刊的评论中所写:“当数字孪生遇见联邦学习,工业的未来不再是单个企业的‘独角戏’,而是全球产业链的‘交响乐’。”