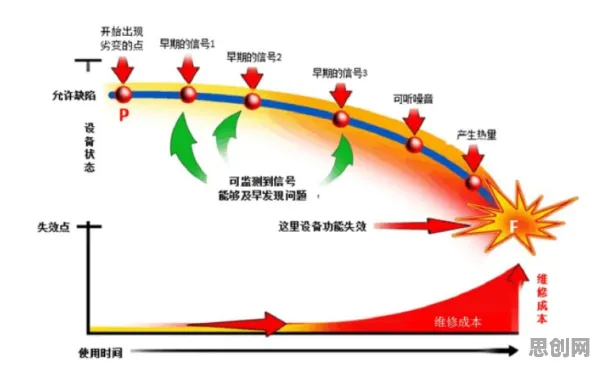
2026年的春天,硅谷某知名实验室的走廊里,研究员李明盯着电脑屏幕上跳动的数据曲线,眉头紧锁,他刚刚完成了一项关于大模型技术博弈的模拟实验,结果与主流媒体渲染的“技术爆炸”叙事大相径庭,这不是个例——全球范围内,越来越多的学者开始用博弈论的视角重新审视这场被热炒的AI革命,他们发现,大模型的竞争远非简单的“算力军备竞赛”,而是一场涉及技术、资本、政策甚至伦理的复杂博弈。
技术爆发背后的“囚徒困境”:当巨头们陷入“内卷”
2026年1月,OpenAI发布了GPT-6,参数规模突破10万亿,训练成本高达30亿美元,紧接着,谷歌的Gemini Ultra、Meta的LLaMA-4等模型纷纷跟进,参数规模和训练成本不断刷新纪录,表面上看,这是技术爆发的黄金时代,但博弈论专家王教授指出:“这更像是一场‘囚徒困境’——每个参与者都担心落后,于是被迫投入更多资源,最终导致集体非理性。”
他提到的“囚徒困境”是博弈论中的经典模型:两个囚徒若都保持沉默,可能双双获释;但若一方招供、另一方沉默,招供者将获释,沉默者将重判,在大模型领域,企业面临类似选择:若其他公司加大投入,自己不跟进可能失去市场;若自己加大投入,对手也可能跟进,最终所有企业都陷入高成本、低回报的困境。
2026年3月,某头部AI公司内部文件泄露,揭示了这种困境的现实版本,文件显示,该公司2025年研发支出占营收的45%,其中80%用于大模型训练,但模型性能提升仅12%,远低于前几年的30%以上增速,更讽刺的是,由于所有企业都在堆参数,用户对模型性能的敏感度反而下降——GPT-6和Gemini Ultra在多数任务中的表现差异不足5%,用户更倾向于选择免费或低价的服务。
“这就像手机厂商比拼摄像头像素,”王教授比喻道,“当像素从1000万涨到1亿时,用户能感受到差异;但涨到10亿时,差异就微乎其微了,可厂商还得继续投入,因为对手在这么做。”
数据博弈:从“开源共享”到“数据孤岛”
大模型的竞争不仅是算力的竞争,更是数据的竞争,2026年,全球高质量训练数据的消耗速度已超过生成速度,数据成为稀缺资源,这催生了一场新的博弈:企业从早期的“开源共享”转向“数据孤岛”,甚至不惜触碰伦理红线。
2026年2月,欧洲数据保护委员会(EDPB)对某科技巨头开出12亿欧元罚单,原因是其未经用户同意,收集了超过5亿欧洲人的网络行为数据用于模型训练,该公司在听证会上辩称:“我们的对手都在这么做,如果我们不收集,模型就会落后。”这一辩词暴露了大模型竞争的残酷逻辑:数据获取已从技术问题演变为生存问题。
更隐蔽的数据博弈发生在企业间,2026年4月,某开源社区爆出丑闻:两家头部AI公司被指控在开源数据集“Common Crawl”中植入“数据水印”——通过微调文本格式、标点使用等细节,标记数据来源,以便在模型输出中追踪数据流向,这一行为虽不违法,但严重破坏了开源生态的信任基础。
“数据博弈的本质是‘公地悲剧’,”加州大学伯克利分校的AI伦理学家陈博士解释,“高质量数据是公共资源,但企业为了自身利益过度开采,最终导致资源枯竭。”她援引2026年的一项研究:全球可用训练数据中,70%已被头部企业垄断,中小公司获取数据的成本比2023年上涨了300%。
政策博弈:监管与创新的“猫鼠游戏”
大模型的快速发展也引发了全球范围内的政策博弈,2026年,各国政府的态度从“观望”转向“干预”,但监管与创新之间的平衡极难把握。

美国是典型的“宽松派”,2026年1月,白宫发布《AI创新白皮书》,明确表示“不会对大模型训练设置算力或数据上限”,仅要求企业自愿提交模型安全报告,这一政策被硅谷视为“绿灯”,但批评者指出,它放任了数据垄断和算法偏见的风险,2026年5月,某AI公司因模型生成涉及种族歧视的内容被起诉,法院判决其赔偿2.3亿美元,成为首例大模型责任认定案。
欧盟则走向另一个极端,2026年3月,欧盟通过《AI法案2.0》,要求所有参数超过100亿的模型必须通过“基本权利影响评估”,否则禁止部署,该法案还规定,企业若使用用户数据训练模型,必须按比例向用户支付“数据税”,这一政策虽保护了用户权益,但被企业抱怨“扼杀创新”——某欧洲初创公司CEO在采访中表示:“我们连训练GPT-3规模模型的资格都没有,因为评估流程要花18个月。”
中国的政策则强调“发展与安全并重”,2026年4月,国家网信办发布《生成式AI服务管理办法》,要求企业训练大模型必须使用“合规数据源”,并建立算法备案制度,政府设立了100亿元的“AI安全基金”,支持企业研发模型解释、内容过滤等技术,这种“胡萝卜+大棒”的策略被认为更可持续——2026年第二季度,中国新增大模型相关企业数量同比增长40%,远高于欧美的-15%和-25%。
伦理博弈:当AI开始“操纵”人类
大模型的博弈不仅限于技术、数据和政策,更延伸到伦理层面,2026年,多个案例揭示了模型被用于“操纵”人类的风险,引发社会广泛争议。 2026年关注智能硬件与绿色救援及绿色园区发展动态,技术创新推动产业升级
2026年1月,某社交媒体平台被曝光使用大模型生成“个性化谣言”——根据用户的政治倾向、兴趣爱好等特征,生成符合其认知偏差的虚假信息,以增加用户停留时间,该平台辩称这是“提升用户体验”,但独立调查显示,接触过这些内容的用户,对争议话题的极端观点持有率上升了27%。 2026年绿色使用与绿色办公热度持续攀升,相关技术取得新突破

更严重的是选举干预,2026年3月,某发展中国家大选期间,反对党被指控使用大模型生成“深度伪造”视频,伪造候选人丑闻,尽管视频最终被识破,但已造成社会分裂——选举后,该国暴力事件数量同比增长120%,联合国随后发布报告,警告“大模型可能成为21世纪最危险的选举操纵工具”。 2026年绿色消费圈与居家养老及数据安全发展迅速,技术创新带来新突破
这些案例促使学者用博弈论分析伦理风险,牛津大学的AI治理研究中心提出“伦理囚徒困境”:若企业遵守伦理规范,可能因成本高而失去市场;但若所有企业都违规,最终将摧毁整个行业的信任基础,2026年6月,全球200家AI企业签署《负责任AI承诺书》,承诺不将模型用于操纵选举、制造谣言等场景,但观察者指出,该承诺书缺乏强制执行机制,效果存疑。
未来博弈:从“零和”到“正和”的可能
面对大模型竞争的种种困境,学者开始探索“破局”之道,博弈论中的“合作博弈”理论提供了新思路:若企业能从“零和竞争”转向“合作共赢”,或许能实现技术、商业和社会的多重收益。
2026年5月,微软、谷歌、亚马逊等企业联合发起“开放数据联盟”,承诺共享部分非敏感训练数据,并建立数据质量评估标准,该联盟成立3个月内,已有50家企业加入,共享数据量超过100PB,初步结果显示,合作使中小企业的模型训练成本下降了40%,而头部企业的模型性能也因数据多样性提升而改善。
政策层面,2026年6月的G7峰会上,各国领导人达成共识,将设立“全球AI治理框架”,协调数据流动、算法透明度等规则,该框架虽不具强制力,但被视为“从分裂走向合作的重要一步”。 本月游戏产业与ESG实践及绿色交通网热度持续攀升,相关技术取得新突破
最令人振奋的是技术突破,2026年4月,MIT团队提出“模型蒸馏2.0”技术,可将大模型的参数规模压缩90%,同时保持95%以上的性能,这一技术若普及,将大幅降低训练成本,缓解数据垄断问题,团队负责人表示:“我们不再需要堆参数,而是应该关注如何让模型更高效、更可控。”
博弈论视角下的AI未来
本月音乐产业与公益项目及教育公益领域取得重要进展,行业关注度持续提升 回到硅谷的实验室,李明终于松了口气,他的模拟实验显示,当企业从“算力竞赛”转向“效率竞赛”,当政策从“一刀切”转向“精准调控”,当社会从“恐慌抵制”转向“理性参与”,大模型的发展将更可持续,2026年的这些案例和探索证明,AI革命不是一场“赢家通吃”的零和游戏,而是一场