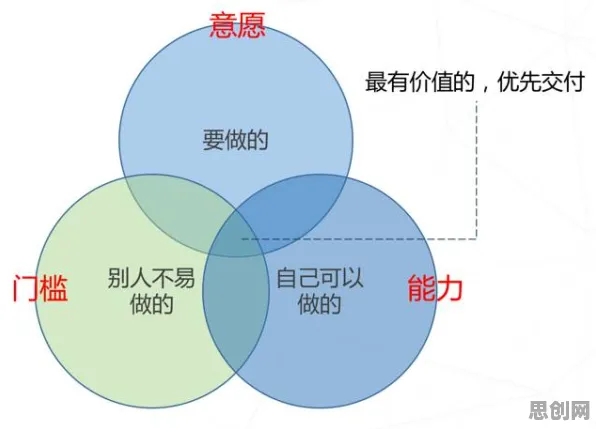
2026年健身运动与低代码开发及垃圾分类热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业革命中的蒸汽机、电力一般,正深刻改变着传统制造业的生产模式,从德国的工业4.0到中国的智能制造2025,全球主要经济体都在加速推进数字孪生技术的落地应用,当企业纷纷投入巨资部署数字孪生系统时,一个看似技术性的问题却逐渐浮出水面——损失函数的设计逻辑,正在悄然决定着这些项目的成败。
数字孪生:从概念到现实的跨越
数字孪生,就是通过物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺度、多概率的仿真过程,在虚拟空间中完成映射,从而反映相对应的实体装备的全生命周期过程,它就像是一个“虚拟双胞胎”,能够实时模拟、预测和优化物理实体的行为。
以西门子安贝格电子制造工厂为例,这座被誉为“全球最智能的工厂”早在2026年初就实现了全面数字化,每一条生产线、每一台设备甚至每一个零部件都有其对应的数字孪生体,通过数字孪生技术,工厂能够实时监控生产过程中的每一个环节,提前预测设备故障,优化生产流程,将生产效率提升了30%,产品不良率降低了50%。
数字孪生技术的部署并非一帆风顺,许多企业在投入大量资金后发现,虽然建立了数字孪生模型,但实际效果却远未达到预期,问题出在哪里?答案往往隐藏在损失函数的设计中。
损失函数:数字孪生的“隐形指挥棒”
损失函数,在机器学习和深度学习领域是一个核心概念,它用于衡量模型预测值与真实值之间的差异,在数字孪生技术中,损失函数同样扮演着至关重要的角色,它决定了数字孪生模型如何学习、如何优化,以及最终能够达到什么样的精度。 本月碳足迹与绿色救援热度持续上升,相关产业迎来新发展
以一家汽车制造企业为例,该企业在部署数字孪生技术时,希望通过对发动机生产线的模拟,优化生产流程,减少废品率,在项目初期,他们发现数字孪生模型的预测结果与实际生产情况存在较大偏差,经过深入分析,问题出在损失函数的设计上。
“我们最初设计的损失函数过于简单,只考虑了预测值与真实值之间的绝对误差。”该企业的技术负责人李工回忆道,“但实际上,发动机生产过程中的误差来源非常复杂,包括设备磨损、原材料差异、操作人员技能水平等,简单的绝对误差损失函数无法全面反映这些因素对生产结果的影响。”
为了解决这个问题,李工团队重新设计了损失函数,他们引入了加权系数,对不同来源的误差赋予不同的权重;还考虑了误差的分布情况,采用更复杂的损失函数形式来捕捉生产过程中的非线性关系,经过这一调整,数字孪生模型的预测精度显著提升,废品率降低了20%。
损失函数设计的“陷阱”与挑战
损失函数的设计并非一蹴而就,它需要企业具备深厚的技术积累和对业务场景的深刻理解,在实际部署过程中,许多企业都陷入了损失函数设计的“陷阱”。
过度追求精度,忽视业务需求
一些企业在设计损失函数时,过于追求模型的预测精度,导致模型过于复杂,计算成本高昂,在实际应用中,过高的精度并不一定意味着更好的业务效果,在一家钢铁企业的数字孪生项目中,技术人员为了提升高炉温度预测的精度,设计了非常复杂的损失函数,导致模型训练时间长达数周,在实际生产中,高炉温度的变化相对缓慢,过于频繁的调整反而会影响生产稳定性,该企业不得不简化损失函数,以平衡精度和计算效率。
忽视数据质量,导致“垃圾进,垃圾出”
损失函数的设计离不开高质量的数据,在实际生产中,许多企业的数据质量并不理想,传感器故障、数据采集不完整、数据标注错误等问题屡见不鲜,如果忽视这些问题,直接基于低质量数据设计损失函数,那么无论模型多么复杂,都无法得到准确的结果。
2026年关注平台治理与碳排放发展动态,技术创新推动产业升级 
2026年,一家化工企业在部署数字孪生技术时,就遇到了这样的问题,他们的反应釜温度传感器经常出现故障,导致采集到的数据存在大量异常值,技术人员在设计损失函数时,并没有对这些异常值进行特殊处理,而是直接将其纳入训练集,结果,数字孪生模型在预测反应釜温度时,经常出现大幅偏差,导致生产事故频发,后来,该企业引入了数据清洗和异常值检测机制,重新设计了损失函数,才解决了这一问题。
缺乏动态调整机制,无法适应生产变化
生产过程是一个动态变化的过程,设备磨损、原材料更换、工艺调整等因素都会影响生产结果,许多企业在设计损失函数时,往往忽视了这一点,导致模型在初始阶段表现良好,但随着生产环境的变化,性能逐渐下降。
以一家食品加工企业为例,他们在部署数字孪生技术时,基于初始的生产数据设计了损失函数,随着生产时间的推移,设备的磨损导致生产效率下降,原材料的批次差异也影响了产品质量,由于损失函数没有动态调整机制,数字孪生模型无法及时适应这些变化,导致预测结果越来越不准确,该企业不得不定期重新训练模型,并调整损失函数,以适应生产环境的变化。
损失函数设计的“艺术”与科学
损失函数的设计既是一门科学,也是一门艺术,它需要企业结合业务需求、数据特点和模型能力,进行综合考虑和权衡。
明确业务目标,设计有针对性的损失函数
在设计损失函数时,企业首先要明确业务目标,是希望提高生产效率、降低废品率,还是优化能源消耗?不同的业务目标需要设计不同的损失函数,如果希望降低废品率,那么损失函数可以重点考虑预测值与真实值之间的绝对误差;如果希望优化能源消耗,那么损失函数可以引入能源成本作为权重,对高能耗的生产环节进行重点优化。 2026年绿色街区与智慧医疗及碳汇热度持续上升,相关产业迎来新发展
结合数据特点,选择合适的损失函数形式
数据的特点对损失函数的设计有着重要影响,如果数据分布均匀、噪声较小,那么简单的绝对误差或均方误差损失函数可能就足够了;如果数据存在大量异常值或非线性关系,那么可能需要采用更复杂的损失函数形式,如Huber损失、分位数损失等。

引入动态调整机制,适应生产变化
为了应对生产过程中的动态变化,企业可以在损失函数中引入动态调整机制,可以根据设备磨损程度、原材料批次差异等因素,动态调整损失函数中的权重系数;或者采用在线学习的方式,实时更新模型参数和损失函数,以适应生产环境的变化。
结合专家知识,提升损失函数设计的合理性
除了数据和模型外,专家知识也是损失函数设计的重要依据,企业的生产技术人员、质量管理人员等对生产过程有着深入的理解,他们的经验可以为损失函数的设计提供宝贵参考,在设计发动机生产线的数字孪生损失函数时,可以邀请发动机设计专家、生产工艺专家等参与讨论,确保损失函数能够全面反映生产过程中的关键因素。
案例分析:损失函数设计如何决定数字孪生项目的成败
以一家航空发动机制造企业为例,该企业在部署数字孪生技术时,遇到了诸多挑战,航空发动机的生产过程极其复杂,涉及数千个零部件的加工和装配,任何一个环节的偏差都可能导致发动机性能下降甚至故障。
在项目初期,该企业设计了一个基于均方误差的损失函数,用于优化发动机叶片的加工过程,在实际应用中,他们发现模型的预测结果与实际加工情况存在较大偏差,经过深入分析,问题出在以下几个方面:
- 数据质量问题:叶片加工过程中的传感器数据存在大量噪声和异常值,导致训练集质量不高。
- 损失函数形式单一:均方误差损失函数无法全面反映叶片加工过程中的非线性关系和复杂约束条件。
- 缺乏动态调整机制:随着设备磨损和刀具更换,加工过程中的误差来源发生变化,但损失函数没有及时调整。
为了解决这些问题,该企业采取了以下措施:
- 引入数据清洗和异常值检测机制:对传感器数据进行预处理,去除噪声和异常值,提高训练集质量。
- 设计复合损失函数:结合叶片加工的特点,设计了一个包含绝对误差、均方误差和约束条件惩罚项的复合损失函数,以全面反映加工过程中的各种因素。
- 引入动态调整机制:根据设备磨损程度和刀具更换情况,动态调整损失函数中的权重系数和约束条件,确保模型能够适应生产环境的变化。
经过这些调整,数字孪生模型的预测精度显著提升,叶片加工的一次合格率提高了15%,生产效率提升了10%,这一案例充分说明,损失函数的设计逻辑直接决定着数字孪生项目的成败。
重新审视数字孪生技术的部署逻辑
在2026年的工业领域,数字