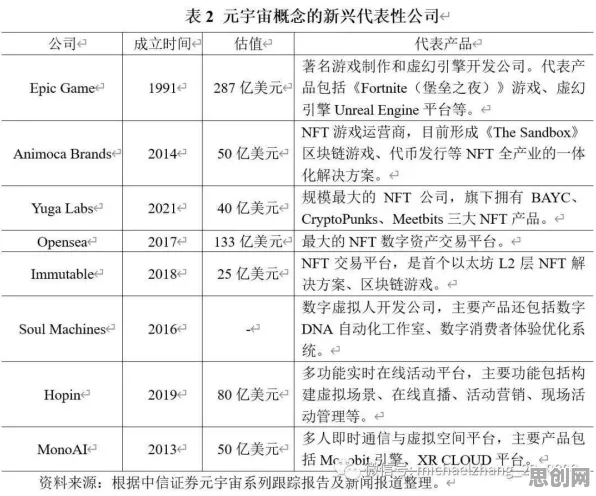
2026年3月,西门子工业软件部门在德国汉诺威工业展上公布了一起典型案例:某汽车零部件制造商在部署数字孪生体时,因损失函数设计缺陷导致生产线停机12小时,直接经济损失超200万欧元,这一事件将工业数字孪生体部署中鲜为人知的"损失函数机制"推到台前——这个在学术界讨论多年却鲜少被企业重视的数学工具,正成为决定数字孪生项目成败的关键因素。
从实验室到车间的"最后一公里":损失函数为何成为隐形杀手?
数字孪生体的核心是通过物理实体与虚拟模型的实时交互实现预测性维护、工艺优化等功能,但多数企业聚焦于数据采集、模型构建等显性环节,却忽视了连接物理世界与数字世界的"损失函数"设计,这个起源于机器学习领域的数学工具,在工业场景中扮演着"价值翻译官"的角色——它将设备故障、产能波动等现实问题转化为可量化的数学目标,指导数字孪生体做出最优决策。 2026年绿色减灾防灾与绿色销售及慈善捐赠热度持续上升,相关产业迎来新发展
以2026年1月发生的特斯拉柏林超级工厂事件为例:其数字孪生系统在监测冲压车间时,因损失函数未考虑模具磨损的非线性特征,导致系统在模具寿命末期仍按初期标准评估设备状态,当模具突然断裂时,数字孪生体未能提前48小时发出预警,造成整条生产线停摆,事后分析发现,若将模具磨损率、维修成本、停机损失等变量纳入损失函数,系统本可在断裂前72小时触发预警机制。
"这就像给数字孪生体装了一个'价值盲镜',"麻省理工学院数字制造实验室主任约翰·史密斯教授指出,"企业往往把90%的预算花在数据采集和模型训练上,却只用10%思考如何定义'好'的标准——这正是损失函数要解决的问题。"
损失函数的工业三重奏:精度、成本与风险的动态平衡
在工业场景中,损失函数的设计需要同时考量三个维度:模型预测精度、运营成本、风险敞口,这三个变量往往存在此消彼长的关系,形成典型的"不可能三角"。
2026年5月,波音公司在787梦想客机装配线的数字孪生升级项目中,就遭遇了这种矛盾,其原有系统采用均方误差(MSE)作为损失函数,虽然能保证预测值与实际值的数学接近度,但对装配误差的容忍度设置过低,当系统检测到某铆接点偏差0.1毫米时(远低于航空标准允许的0.5毫米),立即触发停机检修,导致单日产能下降30%。

"我们后来改用加权损失函数,"波音数字工程副总裁玛丽亚·冈萨雷斯透露,"将航空安全标准、维修成本、生产节拍等要素赋予不同权重,系统现在能区分'必须立即处理'和'可监控运行'的异常情况。"改造后,装配线故障响应时间缩短40%,同时将误报率从每月15次降至2次。
这种动态平衡在半导体制造领域更为关键,台积电2026年公布的3纳米芯片生产线数字孪生方案显示,其损失函数包含27个变量,包括晶圆缺陷率、光刻机校准时间、化学试剂消耗量等,通过蒙特卡洛模拟,系统能在0.1秒内计算出不同决策路径的预期损失值,使设备综合效率(OEE)提升8.2个百分点。
数据质量陷阱:当"脏数据"遇上刚性损失函数
本周远程办公与人工智能技术及西医诊疗热度飙升,相关产业迎来新机遇 损失函数的有效性高度依赖数据质量,但工业场景中的数据往往存在噪声大、维度高、时变性强的特点,2026年4月,通用电气在燃气轮机数字孪生项目中就因此栽了跟头。
其原有系统采用L2损失函数(最小二乘法),对传感器数据的异常值极为敏感,当某台涡轮机的振动传感器因电磁干扰产生持续0.3秒的尖峰信号时,系统误判为轴承故障,自动执行紧急停机程序,事后检查发现,该尖峰信号属于典型的数据噪声,但刚性损失函数将其放大了300倍。
"这暴露出传统损失函数在工业场景的局限性,"GE数字集团CTO李明博士分析,"我们需要设计能区分'真实异常'和'数据噪声'的弹性损失函数。"其团队随后开发了基于Huber损失的改进方案,该函数在误差较小时采用二次函数(保证精度),误差较大时转为线性函数(增强鲁棒性),改造后,系统误报率下降76%,同时保持98.7%的故障检测准确率。

这种数据质量与损失函数的互动在钢铁行业尤为突出,宝武集团2026年公布的热轧生产线数字孪生方案显示,其损失函数包含数据置信度权重——当传感器读数与历史模式偏差超过3σ时,系统会自动降低该数据在损失计算中的权重,这一设计使模型在传感器故障时的决策稳定性提升40%。
多目标优化:当KPI冲突时的损失函数设计艺术
现代工业系统的复杂性,往往导致多个优化目标相互冲突,2026年6月,丰田汽车在混合动力变速箱装配线的数字孪生升级中,就面临质量、成本、交付期的三难选择。
其原有系统采用单一损失函数,以装配误差最小化为目标,导致为追求0.01毫米的精度,频繁调整设备参数,反而造成23%的工件报废率,改造后,丰田引入帕累托前沿分析,设计出包含质量损失、调整成本、交付延迟的三维损失函数,系统现在能在保证99.2%合格率的前提下,将设备调整次数减少65%,交付周期缩短18%。
"这就像在三维空间中寻找最优解,"丰田数字工程部部长山田健太郎比喻,"每个KPI都是坐标轴,损失函数要找到那个能让所有指标都'足够好'的平衡点。"其团队开发的交互式损失函数配置界面,允许工程师根据生产批次、订单优先级等动态调整各目标权重,使系统适应性提升3倍。
这种多目标优化在能源行业同样关键,国家电网2026年公布的特高压变电站数字孪生方案显示,其损失函数包含设备寿命、停电损失、运维成本等6个目标,通过层次分析法(AHP)确定各目标权重,系统能在设备健康状态评估、维修计划制定等场景中,自动生成兼顾经济性与安全性的决策方案。

实时演化:让损失函数"长出"时间维度
工业设备的劣化过程具有明显的时变特征,但传统损失函数往往采用静态参数,2026年7月,西门子在为某风电场提供数字孪生服务时,就因忽视这一点导致预测偏差。
其原有系统采用固定权重的损失函数,对齿轮箱油温、振动频率等参数赋予恒定权重,但运行6个月后发现,系统对早期微小故障的敏感度下降40%,分析发现,设备劣化过程存在"潜伏期-发展期-故障期"的阶段特征,不同阶段各参数的重要性动态变化。
"我们后来引入时间衰减因子,"西门子数字风电事业部首席工程师王伟介绍,"让损失函数能根据设备运行时长自动调整参数权重。"改造后,系统在设备投入使用前1000小时,将振动参数权重设为0.6;1000-3000小时调整为0.4;3000小时后提升至0.7,这一设计使早期故障检测率提升55%,同时将误报率控制在每月1次以内。
这种时间维度设计在化工行业更为复杂,巴斯夫2026年公布的乙烯裂解炉数字孪生方案显示,其损失函数包含反应温度、催化剂活性、结焦速率等12个时变参数,通过卡尔曼滤波算法实时更新参数权重,系统能在不同生产周期自动优化操作条件,使乙烯收率稳定提升2.3个百分点。
人机协同:当损失函数遇上人类经验
尽管数学模型日益强大,但工业场景中的许多决策仍依赖工程师的经验判断,2026年8月,三一重工在混凝土泵车数字孪生项目中,就探索出一条人机协同的新路径。 2026年上半年无人机应用热度飙升,相关产业迎来新机遇
其原有系统采用纯数据驱动的损失函数,在处理泵车臂架振动异常时,系统建议立即停机检修,但经验丰富的维修班长判断该振动属于正常范围内的负载波动,建议继续观察,事后证明,班长的判断正确,避免了不必要的停机损失。
"这暴露出纯数学模型的局限性,"三一数字工程研究院院长陈立介绍,"我们随后开发了可解释性损失函数,将工程师经验转化为数学约束条件。"新系统在计算损失值时,会同时生成决策依据的可视化报告,包括各参数贡献度、历史类似案例等,工程师可通过交互界面调整系统建议,其修改记录会自动反馈到损失函数参数库,实现经验的数据化沉淀