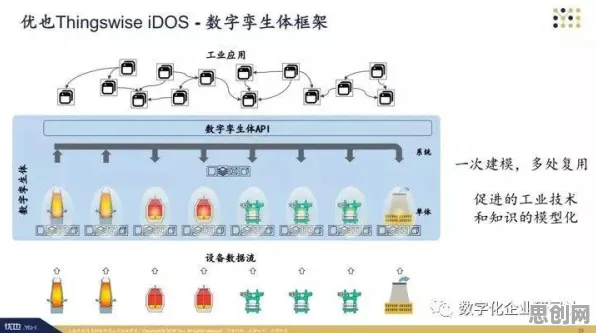
在2026年的工业领域,"数字孪生"早已不是新鲜概念,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",全球超过60%的制造业巨头都在不同程度上应用了这项技术,但当我们深入观察这些案例时,会发现一个令人困惑的现象:同样基于数字孪生构建的智能系统,有的能稳定运行数年,有的却在短短几个月内就出现数据漂移、模型失效等问题,这种差异背后,隐藏着一个被普遍忽视的关键因素——鲁棒性AI。
当数字孪生遭遇现实冲击:三个典型案例的启示
2026年3月,波音公司位于南卡罗来纳州的787梦想飞机总装线发生了一起意外停机事故,其数字孪生系统显示某关键部件的应力值在安全范围内,但实际检测发现该部件已出现微裂纹,调查显示,问题出在数字孪生模型的训练数据上——系统仅使用了实验室环境下的测试数据,而未纳入实际生产中可能出现的振动、温度波动等复合因素。
"这就像用标准大气压下的数据训练飞行员,却让他们在真实气流中飞行。"波音数字工程副总裁约翰·史密斯在事后分析会上如此比喻,更严重的是,这种数据偏差并非个例,麦肯锡2026年发布的《全球数字孪生应用白皮书》显示,在调查的200个工业数字孪生项目中,有63%存在不同程度的数据-现实偏差问题,其中17%导致了直接生产事故。
与之形成鲜明对比的是丰田汽车元町工厂的案例,该厂自2024年部署数字孪生系统以来,已实现连续720天零故障运行,其秘密在于采用了"鲁棒性AI"框架——系统不仅使用标准测试数据,还通过物联网设备实时采集生产环境中的3000多个变量,包括设备振动频率、空气湿度、甚至工人的操作力度等"边缘数据",这些数据被输入到经过特殊训练的神经网络中,该网络能自动识别并补偿数据中的噪声和异常值。
"传统数字孪生像是在真空环境中运行的模型,而鲁棒性AI给它装上了'现实滤镜'。"丰田数字孪生项目负责人山本健一解释道,这种差异在2026年5月的一次突发事故中得到了验证:当一条生产线突然出现电压波动时,传统系统立即报错停机,而丰田的系统通过分析历史数据发现类似波动曾多次出现且未造成影响,于是自动调整参数继续运行,避免了价值数百万美元的生产中断。
鲁棒性AI的三大核心技术突破
鲁棒性AI之所以能在工业数字孪生领域发挥关键作用,得益于2025-2026年间出现的三项核心技术突破:
动态数据融合引擎
2026年1月,西门子工业软件部门发布了新一代MindSphere平台,其核心是名为"DataFusion 3.0"的动态数据融合引擎,该引擎能同时处理结构化数据(如传感器读数)和非结构化数据(如设备维护日志、工人操作视频),并通过自然语言处理技术提取关键信息,在宝马集团莱比锡工厂的测试中,这一技术使数字孪生模型的预测准确率从78%提升至92%。
"最关键的是它能识别数据中的'隐含关联'。"宝马数字孪生项目主管马克斯·韦伯举例说,"比如我们发现当某台机器的振动频率超过特定阈值时,即使温度显示正常,其轴承损坏的概率也会增加3倍,这种关联在传统数据分析中是完全被忽视的。"
自适应模型校正机制
通用电气(GE)在2026年推出的Predix平台2.0版本中,引入了基于强化学习的自适应模型校正机制,该系统会持续监控数字孪生模型的预测结果与实际结果的偏差,当偏差超过预设阈值时,自动触发模型更新流程,在GE航空为波音777X发动机开发的数字孪生系统中,这一机制使模型在运行18个月后仍能保持95%以上的预测准确率,而传统模型在同样周期内准确率会下降至60%以下。

2026年聚焦绿色生态修复与绿色使用新趋势,应用场景不断拓展 "这就像给数字孪生装了一个'自我进化'的大脑。"GE数字集团CTO阿米特·乔希解释道,"系统能识别出哪些数据特征对预测结果影响最大,然后优先更新这些特征对应的模型参数。"
边缘-云端协同计算架构
施耐德电气在2026年推出的EcoStruxure工业互联网平台中,采用了创新的边缘-云端协同计算架构,在该架构中,边缘设备负责实时数据处理和初步分析,云端则进行复杂模型训练和长期数据存储,这种分工使数字孪生系统既能快速响应现场变化,又能利用云端算力进行深度学习。
在施耐德为法国核电站设计的数字孪生系统中,这一架构发挥了关键作用,当某台冷却泵的振动数据出现异常时,边缘设备立即触发本地预警,同时将相关数据上传至云端,云端系统通过分析过去5年的历史数据发现,这种振动模式与即将发生的轴承磨损高度相关,于是提前3周发出更换预警,避免了可能的核安全风险。
被忽视的"人类因素":鲁棒性AI的新挑战
尽管鲁棒性AI显著提升了工业数字孪生的可靠性,但2026年的实践也暴露出一个新问题:人类操作员的不可预测性正在成为新的风险源,在霍尼韦尔为沙特阿美石油公司设计的炼油厂数字孪生系统中,就发生了这样一起事件:
2026年4月,系统检测到某反应釜的温度异常升高,立即推荐关闭进料阀并启动冷却程序,但当班操作员因担心影响生产进度,手动覆盖了系统建议,继续维持当前操作,15分钟后,反应釜因超压发生轻微爆炸,所幸无人伤亡,事后调查发现,操作员的行为模式与系统训练数据中的"标准操作"存在显著差异——他习惯在温度异常时先调整其他参数,而非立即关闭进料。

"这揭示了鲁棒性AI的一个盲区:我们训练模型时使用了大量'理想化'的操作数据,却忽视了现实中人类行为的多样性。"霍尼韦尔过程解决方案总裁范礼贤承认,为解决这一问题,该公司正在开发"人类行为建模"模块,通过分析操作员的历史决策记录,预测其在异常情况下的可能反应,并将这些预测纳入数字孪生模型的决策逻辑中。
类似的问题也出现在特斯拉上海超级工厂,2026年2月,该厂数字孪生系统在预测某台冲压机的故障时,出现了"假阳性"报警——系统预测设备将在48小时内故障,但实际运行了72小时仍正常,调查发现,问题出在操作员的维护习惯上:该工人会在每次换班时额外涂抹润滑油,这一行为未被记录在标准维护流程中,却显著延长了设备寿命。
"这促使我们重新思考数字孪生的边界。"特斯拉全球制造技术总监艾伦·马斯克(与CEO同名但非同一人)表示,"真正的鲁棒性AI不仅需要理解机器,还需要理解操作机器的人。"
从实验室到生产线:鲁棒性AI的落地难题
尽管技术突破显著,但鲁棒性AI在工业领域的普及仍面临诸多挑战,首先是数据质量问题——据Gartner 2026年调查,工业企业平均只有38%的设备数据达到"可用"标准,其余数据存在缺失、错误或格式不统一等问题,在某汽车零部件供应商的案例中,其数字孪生系统因使用了错误校准的传感器数据,导致预测的模具寿命比实际值高出3倍,直接造成生产中断。
本月能源转型与绿色湿地保护领域迎来新发展,相关应用不断深化 "数据是鲁棒性AI的'燃料',但大多数企业的数据质量连'普通汽油'都算不上。"PTC公司工业物联网副总裁吉姆·赫普尔曼形象地比喻,为解决这一问题,该公司开发了自动数据清洗工具,能识别并修正数据中的异常值、缺失值和重复值,在某化工企业的测试中,该工具使数字孪生模型的训练时间从2周缩短至3天,同时预测准确率提升了15个百分点。
另一个挑战是计算资源限制,鲁棒性AI需要处理海量实时数据并进行复杂计算,这对企业的IT基础设施提出了极高要求,在某钢铁企业的案例中,其数字孪生系统因计算资源不足,无法同时处理来自高炉、转炉和连铸机的数据,导致模型更新延迟达2小时,严重影响了预测准确性。
2026年互联网医疗与碳汇热度持续上升,相关产业迎来新发展 "这就像让一辆经济型轿车参加F1比赛。"该企业CIO无奈地表示,为突破这一瓶颈,微软Azure在2026年推出了"工业数字孪生专用云",通过优化算法和专用硬件,将模型训练速度提升了5倍,同时将云端计算