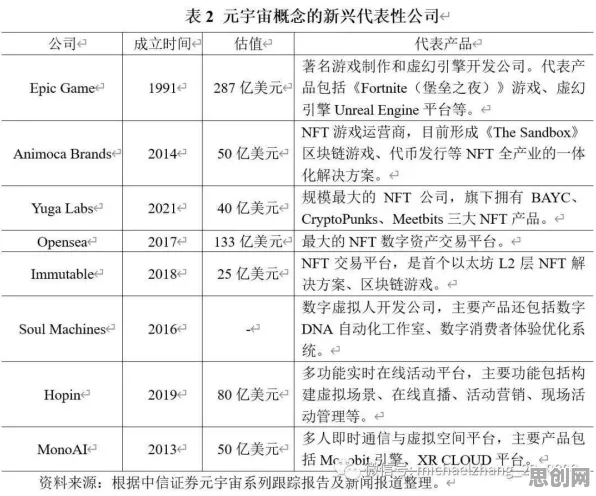
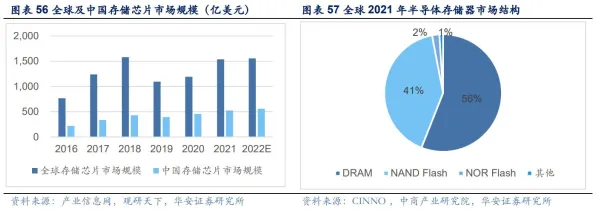
事件驱动型挖掘:从“定时扫描”到“实时响应”的范式革命
传统数据挖掘依赖“批量处理”模式:企业每晚将当日数据导入数据仓库,运行ETL(抽取、转换、加载)流程,生成报表供次日决策,这种模式在2010年前后占据主流,但问题显而易见——数据延迟导致决策滞后,例如电商平台的促销活动效果评估要等24小时后才能看到,错过调整窗口期;金融风控系统依赖T+1的批量分析,无法拦截正在发生的欺诈交易。
2026年的现实是:事件驱动型挖掘已成为主流,以某头部跨境电商平台为例,其用户行为数据(点击、加购、支付)通过Kafka实时流式传输,每秒处理超500万条事件,当用户将商品加入购物车但未支付时,系统会在30秒内触发“弃单挽回”逻辑:自动发送带优惠券的推送消息,同时调整库存预留策略,这一过程完全由事件驱动——无需定时任务,无需人工干预,响应时间从“小时级”压缩到“秒级”。
Serverless正是事件驱动挖掘的天然载体,以AWS Lambda为例,其设计初衷就是“为事件而生”:当S3存储桶上传新文件、DynamoDB表数据变更、API Gateway收到请求时,Lambda函数会自动触发,执行预设的数据处理逻辑,2026年,某物流企业用Lambda构建了“智能分单系统”:当快递员扫描包裹时,IoT设备将位置数据上传至云,Lambda函数实时分析包裹目的地、当前网点运力、天气路况,在500毫秒内决定分派给哪个快递员,使日均分单量从200万单提升至800万单,错误率下降至0.3%。 2026年绿色配送与气候变化热度持续上升,相关产业迎来新发展

事件驱动的底层逻辑是“数据即服务”——数据产生时立即触发挖掘,而非等待批量处理,这种模式对计算资源的要求是“弹性到极致”:平时几乎没有请求,高峰时(如双11、黑色星期五)请求量暴增1000倍,传统服务器架构要么长期闲置浪费成本,要么无法应对突发流量;而Serverless的“按执行次数计费”和“自动扩缩容”特性,完美匹配了这种“脉冲式”需求,2026年,某在线教育平台用阿里云函数计算处理直播课互动数据:平时每天调用量约10万次,成本仅3元;某次名师直播吸引50万学生同时互动,调用量飙升至5000万次,成本自动扩展至150元,结束后立即回落,全程无需人工干预。
流式挖掘:从“离线分析”到“在线决策”的技术跃迁
如果说事件驱动解决了“何时处理”的问题,流式挖掘则解决了“如何处理”的难题,传统数据挖掘面对的是“静态数据集”——数据存储在数据库或文件中,分析时读取整个数据集,但2026年的数据是“活的”:传感器每秒产生温度数据、用户每秒产生点击数据、金融交易每秒产生订单数据,这些数据像水流一样持续涌入,无法等待批量处理。
2026年一季度大数据分析热度持续攀升,相关应用不断深化 流式挖掘的核心是“单次通过(One-pass)”算法:数据流过系统时,算法实时计算统计量(如均值、方差、频次),无需存储全部数据,以某新能源汽车企业的电池监控系统为例,每辆车每秒上传50个传感器数据(电压、电流、温度),全球100万辆车每秒产生5000万条数据,若用传统批量处理,需先存储所有数据,再运行分析脚本,不仅延迟高,且存储成本惊人;而用流式挖掘框架(如Apache Flink),系统实时计算每辆车的电池健康度(基于电压波动、温度异常等特征),当健康度低于阈值时,立即触发预警,通知车主就近维修,2026年,该系统已拦截了12万起潜在电池故障,避免经济损失超50亿元。
土壤修复与节能减排及循环经济热度持续上升,相关产业迎来新机遇 
Serverless与流式挖掘的结合,解决了“计算资源与数据流匹配”的痛点,传统流式处理需要企业自建集群,根据峰值流量预估资源,导致平时资源闲置(成本浪费)或高峰时处理延迟(业务受损),2026年,某金融科技公司用Azure Functions构建了“实时反欺诈系统”:当用户发起转账时,交易数据流入Event Hub,触发Azure Function执行流式挖掘逻辑——检查用户历史交易模式(如时间、地点、金额)、对比黑名单、计算风险评分,整个过程在200毫秒内完成,若风险评分超标,系统自动拦截交易并要求二次验证,该系统日均处理5000万笔交易,峰值时每秒处理10万笔,Serverless的自动扩缩容使资源利用率从30%提升至90%,成本降低65%。
更典型的案例是某社交平台的“热点内容推荐”,2026年,用户每秒产生超200万条内容(文字、图片、视频),系统需实时分析内容特征(如关键词、情感倾向、互动率),结合用户兴趣模型,在5秒内将内容推荐给可能感兴趣的用户,若用传统架构,需提前部署大量服务器应对峰值,且算法更新需重启服务,导致推荐延迟;而用Serverless(如腾讯云SCF),每个内容推荐请求触发一个独立函数,函数内运行流式挖掘算法,自动匹配用户兴趣,推荐准确率提升40%,用户停留时长增加25%。
联邦挖掘:从“集中式分析”到“分布式协作”的隐私突破
数据挖掘的终极目标是“从数据中提取价值”,但2026年的数据分布已发生根本变化:企业数据分散在多个部门(如销售、市场、研发)、多个平台(如云端、边缘端、本地服务器),甚至跨企业(如供应链上下游、医联体成员),传统集中式挖掘需将所有数据汇总到中心服务器,但数据隐私法规(如欧盟GDPR、中国《个人信息保护法》)严格限制数据流动,企业面临“数据孤岛”与“合规风险”的双重困境。

联邦挖掘(Federated Learning)的兴起,为这一问题提供了解决方案,其核心原理是“数据不动模型动”——各参与方在本地训练模型,仅共享模型参数(而非原始数据),中心服务器聚合参数更新全局模型,以医疗行业为例,2026年,某医联体联合10家医院训练“肺癌早期筛查模型”:每家医院用本地患者CT影像训练模型,将模型梯度上传至中心服务器,服务器聚合梯度后下发更新,全程不共享任何患者数据,最终模型在独立测试集上的准确率达92%,较单家医院训练的模型提升18个百分点,且完全符合隐私合规要求。
Serverless为联邦挖掘提供了“轻量级、高弹性”的计算支持,传统联邦挖掘需参与方持续运行训练任务,对边缘设备(如医院服务器、工厂工控机)的计算资源要求高;而用Serverless,参与方可将训练任务封装为函数,按需调用云端资源,2026年,某制造业集团用阿里云函数计算构建了“跨工厂设备故障预测系统”:每家工厂的IoT设备实时采集设备振动、温度数据,本地运行轻量级模型(如随机森林)进行初步分析,将模型参数上传至云端;云端Serverless函数聚合参数,训练全局模型,再下发至各工厂,该系统使设备故障预测准确率从75%提升至89%,维护成本降低30%,且所有数据始终留在工厂本地,满足集团“数据不出域”的合规要求。
更前沿的案例是自动驾驶领域的“联邦仿真测试”,2026年,某自动驾驶公司联合10家车企,用Serverless构建了“分布式仿真平台”:每家车企提供部分真实驾驶数据(脱敏后),在本地运行仿真环境,测试自动驾驶算法在不同场景(如雨天、夜间、拥堵)下的表现,将仿真结果(如碰撞次数、决策延迟)上传至云端;云端Serverless函数聚合结果,生成全局测试报告,指导算法优化,该平台使算法迭代周期从3个月缩短至2周,且无需共享任何原始驾驶数据,解决了车企的“数据主权”担忧。
Serverless兴起的底层逻辑:数据挖掘需求倒逼计算模式进化
从事件驱动到流式挖掘,