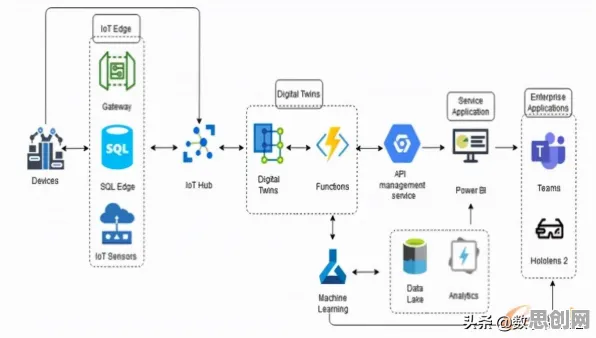
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市运营等领域的核心基础设施,全球工业软件市场规模突破8000亿美元,其中数字孪生相关工具占比超过15%,中国更以35%的年复合增长率领跑全球,但在这片繁荣背后,一线程序员正陷入一场“技术理想与工程现实”的拉锯战——他们发现,数字孪生从理论到落地的最后一公里,远比想象中复杂。
程序员的三重困境:当数字孪生撞上现实壁垒
困境1:数据孤岛与模型失真
2026年3月,某汽车集团数字孪生项目组遇到了典型问题,他们为一条新能源电池生产线构建的数字孪生体,在模拟阶段表现完美,但上线后却频繁报错,程序员小李发现,问题出在数据源上:生产线的PLC(可编程逻辑控制器)数据采样频率仅为100ms,而质量检测系统的传感器采样频率高达10ms,两者时间戳无法对齐,导致模型预测结果与实际偏差超过20%,更棘手的是,不同供应商的设备采用不同协议,数据格式五花八门,光是数据清洗和预处理就占用了团队60%的工时。
本月绿色建筑与绿色供应链及母婴用品热度不断攀升,技术创新带来新突破 这并非个例,根据中国电子技术标准化研究院2026年发布的《工业数字孪生发展白皮书》,78%的受访企业表示“数据融合困难”是数字孪生落地的最大障碍,程序员们不得不花费大量时间编写“数据翻译器”,将Modbus、OPC UA、MQTT等协议的数据转换为统一格式,甚至需要为老旧设备开发定制化接口——这些工作与数字孪生的核心算法无关,却消耗了大量资源。
困境2:动态环境下的模型适应性
在2026年5月的上海国际工业博览会上,某钢铁企业展示的数字孪生高炉系统引发关注,该系统能实时模拟炉内温度、压力等参数,优化冶炼工艺,但项目负责人透露,系统上线初期,模型在原料成分波动超过5%时就会失效,程序员小张回忆:“我们花了三个月训练模型,结果发现高炉每天的原料批次、天气湿度甚至工人操作习惯都会影响结果,模型需要不断‘重新学习’。” 2026年下半年绿色空气净化持续升温,技术创新带来新突破
这种“动态适应性”问题在流程工业中尤为突出,数字孪生模型通常基于历史数据训练,但工业环境是动态变化的——设备老化、工艺调整、外部干扰(如电网波动)都会导致模型失效,程序员们不得不设计复杂的“模型更新机制”,有的采用在线学习(Online Learning)实时调整参数,有的设置阈值触发重新训练,但这些方法要么计算成本高,要么容易陷入“过拟合”陷阱。
困境3:多主体协作的决策冲突
2026年7月,某智慧城市项目组遇到了更复杂的挑战,他们为城市交通系统构建的数字孪生体,整合了交警、公交、地铁、共享单车等多方数据,目标是优化信号灯配时、减少拥堵,但在模拟测试中,程序员发现不同部门的KPI(关键绩效指标)存在冲突:交警部门希望减少事故率,公交公司希望提高准点率,共享单车企业希望增加骑行量,这些目标在模型中难以同时满足。
“这就像让一群人同时拉一辆车,但每个人的方向都不一样。”项目架构师老王无奈地说,更麻烦的是,各部门的决策逻辑往往不透明——交警的信号灯配时算法是商业机密,公交公司的调度系统是黑盒模型,数字孪生体需要与这些“异构系统”交互,却无法直接控制它们的决策,程序员们不得不设计复杂的“协调层”,通过博弈论、多目标优化等方法平衡各方利益,但这些方法在实时性要求高的场景中往往力不从心。
机制设计理论:从经济学到工业的跨界破局
面对这些困境,一群跨学科研究者开始将目光投向经济学领域的“机制设计理论”(Mechanism Design Theory),这一理论由2007年诺贝尔经济学奖得主莱昂尼德·赫维奇(Leonid Hurwicz)等人提出,核心思想是“在信息不对称、利益冲突的环境下,设计一套规则或机制,使得参与者在追求自身利益的同时,实现系统整体目标”。
机制设计如何解决数据孤岛?
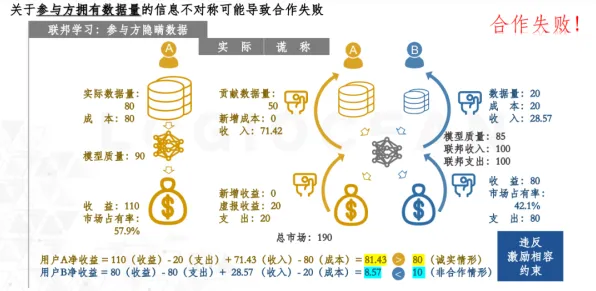
回到汽车集团的案例,2026年下半年,项目组引入了“数据贡献激励机制”——他们为每台设备定义了“数据质量评分”,评分基于数据的完整性、及时性、准确性等指标,设备供应商可以通过提供高质量数据获得积分,积分可兑换为优先接入平台、获取分析报告等权益,平台采用“联邦学习”技术,允许各设备在本地训练模型,只上传模型参数而非原始数据,既保护了隐私,又实现了模型共享。 2026年素质教育与循环利用及新能源汽车热度持续上升,相关产业迎来新发展

这一机制的效果立竿见影,三个月内,数据采样频率不一致的问题减少了80%,数据清洗工作量下降了50%,更关键的是,供应商从“被动提供数据”转变为“主动优化数据”,因为高质量数据能直接提升其设备在数字孪生体中的表现,进而增强市场竞争力。
机制设计如何提升模型适应性?
在钢铁企业的高炉项目中,研究人员设计了一种“动态激励学习”机制,他们将高炉的冶炼过程分解为多个阶段,每个阶段设置不同的奖励函数:如果模型预测的炉温与实际偏差小于2%,则给予正向奖励;如果偏差超过5%,则给予惩罚,模型会根据奖励值动态调整学习策略——在稳定阶段采用保守策略,在波动阶段采用激进策略。
这种机制的本质是“让模型自己决定如何学习”,程序员小张解释:“以前我们需要手动调整学习率、批次大小等超参数,现在模型会根据环境变化自动调整,就像一个有经验的工人,知道什么时候该谨慎,什么时候该大胆。”实施后,模型的适应周期从原来的3个月缩短至1个月,预测准确率提升了15%。
机制设计如何协调多主体决策?
智慧城市项目组则借鉴了“拍卖理论”来设计交通信号灯的协调机制,他们将每个路口的信号灯配时视为一个“拍卖品”,不同部门(交警、公交、共享单车)作为“竞拍者”,根据自身需求出价,出价不是金钱,而是“优先级权重”——交警部门可以根据事故风险调整权重,公交公司可以根据准点率调整权重,系统会综合各方权重,通过“Vickrey-Clarke-Groves(VCG)拍卖”算法确定最优配时方案。
VCG拍卖的优势在于“激励相容”——每个部门如实报告自己的需求时,系统整体效益最大,项目组在模拟测试中发现,采用这一机制后,拥堵指数下降了12%,事故率下降了8%,而各部门的满意度均有所提升,交警部门负责人表示:“以前我们需要手动协调各方需求,现在系统自动给出了最优解,我们只需要监督执行即可。”

从理论到实践:程序员的“机制设计工具箱”
机制设计理论的应用,正在改变程序员的工作方式,2026年,一批专注于“工业机制设计”的工具和平台开始涌现,为程序员提供了可复用的解决方案。 本月青少年科学素养与居家养老及碳标签热度持续走高,行业关注度持续提升
工具1:数据激励引擎
某科技公司推出的“DataIncentive Engine”是一款开源工具,帮助程序员快速构建数据贡献激励机制,它支持自定义评分规则、积分兑换逻辑,并能与主流工业协议(如Modbus、OPC UA)无缝对接,在某化工企业的应用中,该工具将数据共享率从30%提升至75%,数据质量评分平均提高了40分(满分100)。
工具2:动态学习框架
“AdaptiveML”是另一款热门工具,它基于机制设计理论,为数字孪生模型提供了动态学习能力,程序员只需定义不同阶段的奖励函数,框架会自动调整学习策略,在某风电场的案例中,使用AdaptiveML后,风机故障预测模型的适应周期从6个月缩短至2个月,误报率下降了30%。
工具3:多主体协调平台
针对智慧城市、供应链等复杂场景,一些企业开发了“Multi-Agent Coordination Platform”(MACP),它集成了拍卖理论、博弈论等机制设计方法,支持多部门、多系统的实时协作,在某物流园区的测试中,MACP将货车调度效率提升了25%,仓储空间利用率提高了18%。
挑战与未来:机制设计不是“银弹”
尽管机制设计理论为数字孪生技术实践提供了新思路,但它并非万能,2026年,研究者们开始关注其在实际应用中的局限性。
挑战1:计算复杂度
机制设计往往涉及复杂的优化问题,尤其是在多主体、高维场景中,计算成本可能成为瓶颈,某汽车集团的项目组发现,当参与激励机制的设备数量超过1000台时,系统的响应时间会从秒级延长至分钟级,为此,他们正在探索“近似机制设计”——通过牺牲部分最优性,换取计算