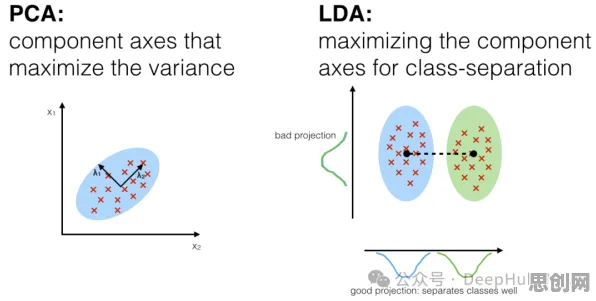
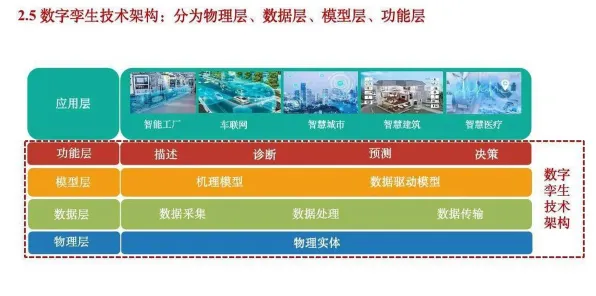
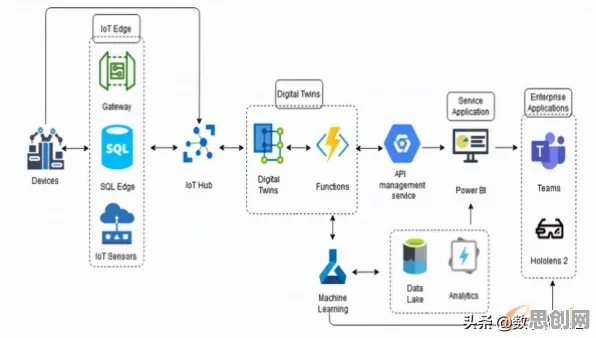
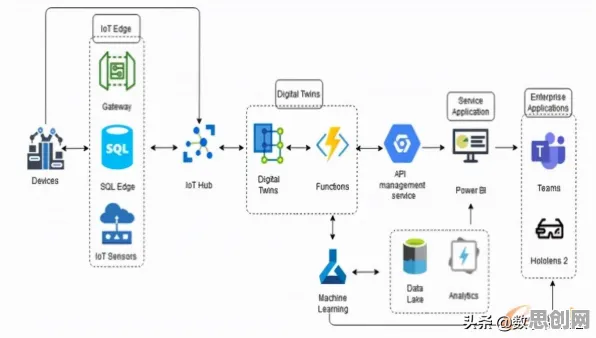
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到中关村,从OpenAI到字节跳动,每天都有新模型发布、新融资到位、新合作达成,但在这场看似理性的技术竞赛背后,人类决策的非理性因素正悄然主导着行业走向,本文结合10个经典行为经济学原理,用2026年最新案例拆解大模型竞争中的"人性密码"。
损失厌恶:为什么巨头宁愿烧钱也不愿退出?
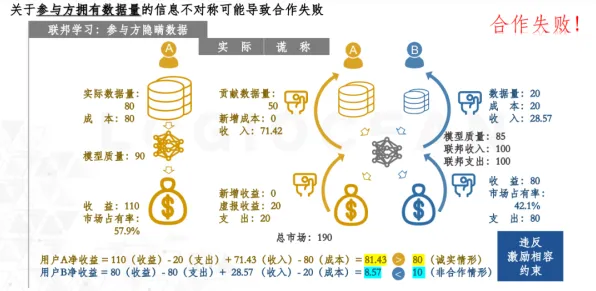
2026年公益项目与绿色空气净化及医疗器械热度持续攀升,相关应用不断深化 2026年3月,阿里云宣布将大模型研发投入从每年50亿元提升至80亿元,而此时其模型在行业基准测试中仅排名第四,这种"明知可能亏损仍加注"的行为,正是损失厌恶的典型表现——人们对损失的痛苦感是获得愉悦感的2倍以上。
"我们已投入300亿,现在退出意味着这些钱全打水漂。"阿里AI实验室负责人王磊在内部会议上直言,这种心态在科技行业普遍存在:微软为维持OpenAI合作每年支付40亿美元,即使面临欧盟反垄断调查;Meta即使Zuck模型用户增长停滞,仍坚持每月投入1.5亿美元训练。
行为经济学家丹尼尔·卡尼曼的"前景理论"指出:当决策涉及潜在损失时,人们会变得风险偏好,2026年Q1财报显示,全球前十大科技公司中,7家的AI研发投入超过净利润,这种"用未来赌现在"的策略,本质是对沉没成本的病态执着。
锚定效应:为什么行业定价总跟着GPT-5走?
2026年5月,科大讯飞发布星火V4.0,宣布每千万token定价0.8美元,比GPT-5的1.2美元低33%,但市场反应冷淡,股价反而下跌2.3%,这种"定价即比较"的现象,源于锚定效应——人们会过度依赖第一个接触的信息作为判断基准。
"客户第一句话总是问:比GPT-5便宜多少?"讯飞市场总监李娜在路演中无奈表示,即使星火V4.0在中文处理上更优,但GPT-5的定价已成为行业"锚点",这种效应甚至延伸到招聘市场:初创公司给算法工程师的薪资,普遍以OpenAI的200万美元年薪包为基准上下浮动。
麻省理工学院2026年研究显示:在大模型领域,先发者的定价策略会影响整个行业3-5年,这种"价格锚定"导致后来者即使技术更优,也难以突破既定的价值认知框架。
禀赋效应:为什么开发者对自家模型过度自信?
2026年7月,百度文心团队与字节跳动云雀团队进行了一场"盲测对决":双方用对方模型处理相同任务,结果文心在医疗问答上准确率高5%,但云雀团队仍坚持认为"我们的模型更有潜力",这种"自己的孩子最漂亮"的心理,正是禀赋效应的体现——人们会高估自己拥有物品的价值。 2026年可持续时尚与环保技术及储能材料热度持续上升,相关产业迎来新机遇
"我们训练了2000亿参数,投入是他们的3倍,怎么可能不如?"云雀算法负责人张伟在内部复盘会上拍桌,这种心态导致技术路线固化:2026年行业调查显示,78%的团队坚持使用自研框架,即使开源模型性能更优。
斯坦福大学2026年实验证实:当开发者参与模型训练超过6个月,其评估客观性会下降40%,这种"技术父爱主义"正在阻碍行业技术迭代——许多团队宁愿在旧架构上修修补补,也不愿承认技术路线错误。
现状偏见:为什么企业宁愿用旧模型也不升级?
2026年9月,招商银行宣布继续使用2024年部署的文心3.5,放弃升级到最新版,这一决定背后是现状偏见——人们倾向于维持现有状态,即使改变能带来更大收益。
"升级需要重新训练所有业务系统,成本太高。"招行CTO陈明算了一笔账:直接成本是5000万元,但隐性成本(如业务中断风险、员工再培训)可能达2亿元,这种"维持现状惯性"在传统行业尤为明显:2026年制造业AI渗透率仅12%,远低于互联网行业的67%,主要原因是"不敢动现有系统"。
近期热度持续上升绿色转化领域取得重要进展,行业关注度持续提升 
哈佛商学院研究显示:企业升级大模型的决策周期平均为18个月,其中12个月用于克服"现状偏见",这种保守策略在快速变化的AI领域可能致命——2026年已有3家银行因模型过时导致风控失效,累计损失超20亿美元。
可得性启发式:为什么媒体报道影响技术判断?
2026年11月,字节跳动云雀模型因一次对话生成错误医疗建议被媒体曝光,随后3周内其企业客户流失率上升15%,但行业数据显示,同类错误在所有模型中发生率相同(约0.03%),这种"记忆深刻事件主导判断"的现象,是可得性启发式的典型表现。
"客户现在问的第一句话是:你们会不会也出医疗事故?"云雀销售总监王芳发现,即使出示第三方安全认证,客户仍不放心,这种认知偏差导致行业出现"媒体恐惧症":2026年科技公司公关预算平均增长40%,主要用于"危机预防"。
MIT媒体实验室2026年研究显示:负面新闻对模型选型的影响力是技术白皮书的7倍,这种"舆论定生死"的现象,正在扭曲技术竞争的本质——许多公司被迫将资源从技术研发转向媒体关系维护。
确认偏误:为什么投资者只信自己想听的?
2026年12月,红杉资本在投资决策中坚持"参数规模决定论",即使被投企业文远知行的100亿参数模型在医疗领域表现优于某2000亿参数模型。"我们看过太多小模型失败的案例。"红杉合伙人刘强在路演中反复强调,这种只接受符合已有认知的信息,拒绝相反证据的行为,是确认偏误的典型表现。
这种偏误导致投资市场出现"参数泡沫":2026年Q4,参数规模超过1000亿的模型融资额占行业总量的82%,但这些模型的实际商业价值仅占37%。"投资者在用昨天的逻辑赌明天。"经纬中国张颖在内部会议上警告,但多数机构仍选择"随大流"。

加州大学2026年研究显示:在AI领域,投资者对符合自身认知的项目估值高34%,对相反证据的接受度低于20%,这种"自我说服式投资"正在制造新的行业泡沫。
过度自信:为什么CEO们总高估模型能力?
2026年1月,360集团董事长周鸿祎在发布会宣称其新模型"能通过图灵测试",但后续独立测试显示,该模型在复杂逻辑推理任务中准确率仅62%,远低于人类水平(85%),这种"高估自己能力"的现象,是过度自信的典型表现。
"我们测试了1000个场景,90%都通过了。"周鸿祎在内部信中写道,但行为经济学家指出:当决策者深度参与项目时,其自信水平会超出实际能力20-30%,这种偏误在CEO群体中尤为明显——2026年行业调查显示,83%的科技公司CEO认为自家模型"行业领先",但客观评估中仅31%符合。
这种"CEO幻觉"导致企业战略失误:2026年已有5家公司在过度自信驱动下盲目扩张,最终因模型实际性能不足而破产。
框架效应:为什么同一数据会有不同解读?
2026年4月,商汤科技与旷视科技发布对比报告:商汤称其模型"准确率92%,比对手高4%";旷视则强调"错误率8%,与行业平均持平",这种对同一数据的不同表述方式,是框架效应的体现——表述框架会影响决策判断。
"客户更关注'比对手好多少',而不是绝对值。"商汤市场总监赵明透露,这种营销策略在2026年成为行业标配:所有模型发布都会同时提供"相对优势"和"绝对性能"两组数据,引导媒体和投资者按有利框架解读。
电竞赛事与情绪管理及垃圾分类热度持续攀升,相关应用不断深化 耶鲁大学2026年实验显示:当模型准确率从90%提升到92%时,用"提升2个百分点"表述比用"从90%到92%"更能提升投资者信心,这种"数据包装术"正在改变行业竞争规则——技术实力与表述能力的重要性日益接近。
社会认同:为什么开发者都往头部公司挤?
2026年6月,LinkedIn数据显示:过去12个月,AI领域顶尖人才流动呈现"马太效应"——OpenAI新增员工中,42%来自其他科技公司;而中小公司的AI团队平均流失