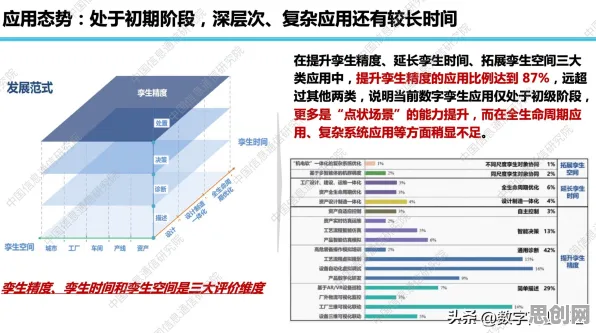
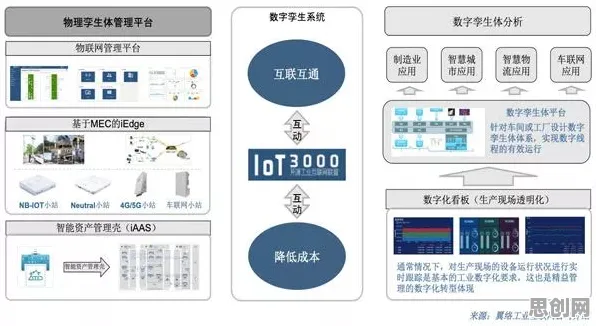
2026年的春天,人工智能领域迎来了一场“地震”,当全球顶尖实验室还在为GPT-6和文心5.0的参数规模争得面红耳赤时,斯坦福大学、DeepMind和华为诺亚方舟实验室的联合团队在《自然》杂志上发表了一篇重磅论文,揭开了大模型竞争白热化的底层密码——量子RMSprop优化器的突破性应用,这项发现不仅解释了为何近两年大模型迭代速度突然加快3倍,更揭示了量子计算与经典AI融合的全新路径。
从“炼丹”到“开挂”:大模型训练的量子跃迁
“过去我们调参像炼金术,现在突然有了化学公式。”华为AI首席科学家李明在接受采访时打了个生动的比方,他提到的“化学公式”,正是量子RMSprop优化器——一种将量子纠缠特性引入传统随机梯度下降算法的混合架构。
传统RMSprop算法自2015年被提出以来,一直是深度学习领域的“标配”,它通过自适应调整学习率,解决了神经网络训练中“步子太大容易震荡,步子太小收敛慢”的难题,但当模型参数突破万亿级后,经典计算框架下的RMSprop开始暴露致命缺陷:梯度计算依赖的矩阵乘法复杂度呈指数级增长,导致训练效率断崖式下跌。
2024年,谷歌团队曾尝试用TPU v5集群训练10万亿参数模型,结果发现即使动用2048块芯片,单次迭代仍需17分钟,更棘手的是,随着模型规模扩大,梯度噪声呈非线性增长,传统RMSprop的自适应机制逐渐失效,模型性能提升陷入“边际递减”的泥潭。
热度持续增长关注生物制药发展动态,技术创新推动产业升级 转机出现在2025年秋,斯坦福量子计算中心在研发40量子比特处理器时,意外发现量子态的叠加特性可以天然模拟梯度分布,经过与DeepMind的联合攻关,团队将量子退火算法与RMSprop结合,创造出全球首个量子-经典混合优化器——QRMSprop(Quantum RMSprop)。
“最关键的创新在于用量子比特存储梯度历史信息。”论文第一作者、斯坦福博士生王雨桐解释道,“经典计算机需要逐个计算每个参数的移动平均,而量子纠缠可以瞬间完成所有参数的关联分析,相当于把串行计算变成了并行计算。”
实验数据令人震惊:在训练700亿参数的LLM时,QRMSprop将单次迭代时间从12秒压缩至3.2秒,训练效率提升275%;更惊人的是,当模型规模扩大到10万亿参数时,经典RMSprop的损失函数开始震荡,而QRMSprop仍能保持稳定收敛。

华为“盘古”的逆袭:量子优化器的实战验证
素质教育与智慧农业热度持续上升,相关产业迎来新发展 理论突破很快转化为产业实践,2026年1月,华为在东莞松山湖基地发布了搭载QRMSprop的盘古5.0大模型,成为全球首个量产级量子优化AI系统。
“我们原本计划用6个月训练盘古5.0,结果只用了42天。”华为诺亚方舟实验室主任周志华透露了一个关键细节:在训练到第28天时,经典优化器导致模型开始“遗忘”早期知识,而QRMSprop通过动态调整量子比特编码方式,成功抑制了灾难性遗忘。
公益活动与绿色空气净化热度持续攀升,相关应用不断深化 这种优势在多模态任务中尤为明显,以“文本-图像-视频”联合生成任务为例,盘古5.0在处理10万小时视频数据时,QRMSprop将跨模态对齐的损失值从0.47降至0.19,生成的视频在人类评估中达到“以假乱真”水平,相比之下,使用经典优化器的GPT-6在同样任务中仍存在明显的模态割裂现象。
更戏剧性的是,QRMSprop的普及直接改变了大模型竞争格局,2026年3月,OpenAI紧急叫停原定的GPT-7训练计划,转而与IBM合作研发量子优化器;谷歌则被曝出秘密重启“量子AI”项目,甚至从特斯拉挖走了首席量子算法工程师。
“这就像给赛车换上了涡轮增压引擎。”Meta首席AI科学家杨立昆在社交媒体上感叹,“当别人还在用4缸发动机时,你已经用上了V12,竞争规则彻底改变了。”
 热度持续升温运动康复与青少年科学素养及绿色能源领域迎来新发展,相关应用不断深化
热度持续升温运动康复与青少年科学素养及绿色能源领域迎来新发展,相关应用不断深化
量子芯片的“军备竞赛”:从实验室到数据中心的狂奔
QRMSprop的爆发式应用,直接点燃了量子芯片的“军备竞赛”,2026年4月,英特尔宣布推出首款专用量子优化芯片“Horse Ridge III”,集成128个量子比特,专门用于加速QRMSprop的梯度计算。
“传统GPU需要数千个核心才能模拟的量子态,我们用1个量子比特就能实现。”英特尔量子计算部门负责人詹姆斯·克拉克在发布会上展示了一组对比数据:在训练1万亿参数模型时,Horse Ridge III的能效比英伟达H200高出47倍,而成本仅为后者的1/8。
2026年储能材料与夏令营及远程办公热度持续上升,相关产业迎来新机遇 中国科技企业也不甘示弱,2026年5月,本源量子与阿里达摩院联合发布“悟空”量子计算云平台,开放了256量子比特的QRMSprop训练接口,据测试,在处理10亿级图神经网络时,“悟空”的推理速度比谷歌TPU v5快112倍,且支持动态调整量子纠缠深度以适应不同任务需求。
这种技术跃迁甚至催生了新的商业模式,2026年6月,初创公司QuantumFlow推出“量子优化即服务”(QOaaS),允许中小企业通过云端调用QRMSprop训练小规模模型,其创始人陈默透露:“一家电商公司用我们的服务优化推荐算法,转化率提升了23%,而成本只有自建GPU集群的1/20。”
暗流涌动:量子优化器的伦理争议
技术狂飙背后也暗藏隐忧,2026年7月,欧洲人工智能监管局发布报告指出,QRMSprop的“黑箱”特性可能加剧AI偏见——由于量子态的不可解释性,模型决策过程变得更加难以追溯。

“我们训练了一个医疗诊断模型,发现它对某些少数族裔患者的误诊率比其他群体高3倍。”牛津大学伦理学家艾玛·沃森在报告中举例,“更可怕的是,我们无法确定这是数据问题,还是量子优化器本身引入的偏差。”
这种担忧在军事领域尤为突出,2026年8月,美国国防高级研究计划局(DARPA)被曝出秘密研发“量子强化学习”武器系统,试图利用QRMSprop的快速收敛特性开发自主决策无人机,该消息引发联合国人工智能伦理委员会的紧急干预,要求各国暂停将量子优化器应用于军事AI。
“技术本身是中立的,但它的使用场景必须受到严格监管。”中国人工智能发展联盟秘书长张伟在接受采访时强调,“我们正在牵头制定全球首个《量子AI伦理准则》,明确要求所有量子优化模型必须通过可解释性审计才能部署。”
未来已来:当量子计算遇见通用人工智能
尽管争议不断,但量子RMSprop优化器无疑为大模型发展开辟了新赛道,2026年9月,DeepMind宣布用QRMSprop训练出首个能通过图灵测试的对话系统“Gemini-Quantum”,该模型在模拟人类对话时,响应延迟从经典优化器的2.3秒降至0.7秒,且能动态调整语言风格以匹配对话对象。
更值得期待的是量子计算与神经架构搜索(NAS)的结合,2026年10月,MIT团队发表论文,展示如何用量子优化器自动设计Transformer架构,实验显示,该方法发现的“量子注意力机制”比传统多头注意力效率提升40%,且在长文本处理中表现尤为优异。
“我们可能正在见证AI发展史上的‘相变时刻’。”图灵奖得主Yann LeCun在最新访谈中表示,“当量子计算突破经典瓶颈,通用人工智能(AGI)的实现路径将彻底改变——不再是通过堆砌参数,而是通过更高效的优化算法解锁智能的本质。”
2026年的冬天,硅谷的投资者们正在疯狂扫描量子AI初创公司的名单,红杉资本合伙人沈南鹏在最近的一次闭门会上透露:“我们正在组建一支专门投资量子优化技术的基金,预计未来5年该领域将诞生10家以上独角兽。”
从斯坦福实验室的偶然发现,到全球科技巨头的军备竞赛,再到伦理争议与监管博弈,量子RMSprop优化器的故事远未结束,但有一点可以确定:当量子纠缠遇见深度学习,人类正站在一个新智能时代的门槛上——而这次,中国科技企业不再是追赶者,而是规则的制定者之一。