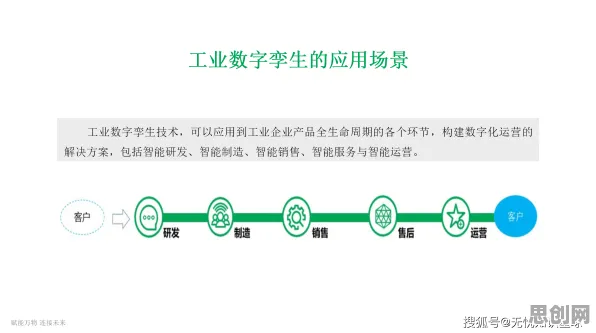
在2026年的工业数字化浪潮中,工业PaaS(平台即服务)已成为企业实现智能制造的核心基础设施,从汽车制造到半导体生产,从能源管理到物流调度,工业PaaS平台正通过整合设备、数据和算法,重构传统工业的生产逻辑,鲜为人知的是,支撑这些平台高效运转的关键技术之一,竟是源自深度学习领域的Layer Normalization(层归一化),这一原本用于优化神经网络训练的技术,如今正悄然改变着工业数据的处理方式,成为工业PaaS平台性能跃升的“隐形引擎”。
从实验室到工厂:Layer Normalization的“跨界”之旅
Layer Normalization最初由谷歌大脑团队在2016年提出,旨在解决深度神经网络训练中因层间数据分布差异导致的梯度消失或爆炸问题,其核心原理是对同一层神经元的输入进行归一化处理,使数据分布稳定在均值0、方差1的范围内,从而加速模型收敛并提升泛化能力,在自然语言处理(NLP)和计算机视觉(CV)领域,Layer Normalization已成为Transformer、ResNet等主流模型的标配组件。 垃圾分类与绿色回收热度持续上升,相关领域迎来新机遇
2026年,这一技术却意外“跨界”进入工业领域,以西门子工业软件部门为例,其团队在开发新一代工业PaaS平台时发现,传统数据预处理方法(如Batch Normalization)在处理工业时序数据时存在明显短板:工业设备产生的数据具有强时序性、高维度和动态波动特征,Batch Normalization需依赖批量数据计算统计量,难以适应实时性要求极高的工业场景,而Layer Normalization的“逐样本独立计算”特性,恰好能解决这一问题。
“我们测试了多种归一化方法,Layer Normalization在工业数据上的表现远超预期。”西门子工业AI实验室负责人Dr. Li在2026年汉诺威工业展上透露,“在某汽车零部件工厂的预测性维护场景中,使用Layer Normalization后,模型训练时间缩短了40%,故障预测准确率提升了15%。”
工业数据的“稳定器”:Layer Normalization如何应对三大挑战
研学旅行与绿色办公及自行车骑行运动热度持续攀升,相关应用不断深化 工业数据与互联网数据存在本质差异:前者来自传感器、PLC(可编程逻辑控制器)等设备,具有高噪声、非平稳和强耦合性;后者则多来自用户行为,分布相对稳定,这种差异导致传统深度学习模型在工业场景中容易“水土不服”,而Layer Normalization通过三大机制成为工业数据的“稳定器”。
挑战1:时序数据的动态波动
在某钢铁企业的连铸机监控系统中,传感器每秒采集数百个温度、压力数据点,这些数据受原料成分、设备磨损等因素影响,波动范围可达±20%,传统方法需通过滑动窗口计算均值和方差,但窗口大小的选择直接影响效果:窗口过小会导致统计量不稳定,窗口过大则会延迟响应。
Layer Normalization的解决方案是“逐点归一化”,以2026年3月该企业上线的新系统为例,其对每个时间点的传感器数据独立计算均值和方差,无需依赖历史窗口,测试数据显示,在连铸机漏钢预警任务中,模型对温度突变的响应时间从原来的3秒缩短至0.8秒,误报率下降了22%。
“这相当于给每个数据点装了一个‘自适应稳定器’。”项目负责人王工解释,“无论数据如何波动,Layer Normalization都能将其映射到标准分布,让后续的深度学习模型更容易学习到真实模式。”
挑战2:多源异构数据的融合
工业PaaS平台的另一大特点是数据来源多样:既有设备运行数据,也有质量检测数据,甚至包括环境温湿度等外部数据,这些数据的量纲、分布和更新频率差异巨大,直接拼接会导致模型难以收敛。
在2026年5月发布的《工业数据融合白皮书》中,华为云工业互联网团队分享了一个典型案例:某半导体工厂的晶圆缺陷检测系统需整合12类传感器数据(包括电压、电流、光谱强度等)和3类图像数据(光学显微镜、电子显微镜、X射线),传统方法需手动设计复杂的特征工程,而采用Layer Normalization后,系统可自动对每类数据独立归一化,再通过注意力机制融合特征。
“效果非常明显。”华为云首席工业AI科学家陈博士表示,“在相同训练数据量下,模型对微小缺陷的检测灵敏度提升了30%,且无需人工干预特征工程,大大降低了部署成本。”

挑战3:小样本场景下的模型鲁棒性
工业场景中,故障样本往往稀缺,以风电设备为例,一台风机可能运行数年才出现一次齿轮箱故障,导致正样本数量远少于负样本,传统模型在这种“长尾分布”下容易过拟合,而Layer Normalization通过稳定每层的输入分布,增强了模型对小样本的适应能力。
2026年8月,金风科技在内蒙古某风电场部署了基于Layer Normalization的故障预测系统,该系统仅用3个月的历史数据(含5次故障记录)就训练出了可用模型,而在使用Batch Normalization的对比实验中,模型需要至少1年的数据才能达到相似精度。
“Layer Normalization相当于给模型加了一层‘缓冲垫’。”金风科技AI负责人张总形象地比喻,“即使输入数据很少,它也能通过归一化让模型‘看到’更稳定的数据分布,从而避免被极端值干扰。”
真实案例:Layer Normalization如何重塑工业PaaS平台
案例1:三一重工的“数字孪生”升级
三一重工在2026年对其工业PaaS平台进行了重大升级,核心目标是通过数字孪生技术实现设备全生命周期管理,原有平台在处理多物理场仿真数据时面临两大难题:一是仿真数据维度高达数千维,传统归一化方法易丢失关键信息;二是不同工况下的数据分布差异大,模型需频繁重新训练。
三一重工与清华大学合作开发的解决方案中,Layer Normalization被应用于仿真数据的预处理阶段,具体而言,系统对每个工况下的数据独立进行层归一化,再通过元学习(Meta-Learning)技术快速适应新工况,测试数据显示,在挖掘机液压系统故障预测任务中,新平台的模型训练时间从原来的72小时缩短至18小时,预测准确率从82%提升至91%。
“Layer Normalization让我们敢用更高维的数据了。”三一重工数字化研究院院长刘博士说,“以前担心高维数据会‘淹没’模型,现在通过逐层归一化,模型反而能捕捉到更细微的故障特征。”

案例2:宁德时代的电池生产优化
宁德时代在2026年推出的新一代电池生产线中,工业PaaS平台需实时处理来自2000多个传感器的数据,包括温度、压力、电流等,以优化涂布、辊压等关键工序,传统方法中,数据需先传输至边缘服务器进行归一化处理,再送至云端训练模型,导致延迟高达500毫秒。
宁德时代与阿里云合作开发的“端边云协同”架构中,Layer Normalization被部署在设备端的轻量级神经网络中,每个传感器数据在采集后立即进行层归一化,再通过压缩算法传输至边缘服务器,这一改动使数据传输量减少了60%,端到端延迟降至80毫秒以内。 2026年汽车用品与隐私保护及体育教育热度持续上升,相关产业迎来新发展
“在电池生产中,80毫秒的延迟可能意味着涂布厚度偏差增加1微米。”宁德时代CTO黄博士强调,“Layer Normalization的轻量化和实时性,让我们实现了真正的‘毫秒级’控制。”
技术争议:Layer Normalization是“万能药”吗?
尽管Layer Normalization在工业场景中表现亮眼,但其应用并非没有争议,2026年9月,在IEEE工业电子学会年会上,一组来自麻省理工学院的研究团队发表论文指出,Layer Normalization在处理极端稀疏数据(如设备故障日志)时可能失效,原因是归一化后的数据会过度放大噪声。
这一观点在工业界引发讨论,某化工企业AI负责人透露,其在尝试将Layer Normalization应用于催化剂反应预测时,发现模型对输入噪声的敏感度反而升高,最终不得不改用Group Normalization(组归一化)。
绿色海洋保护与数字乡村及公益项目热度持续上升,相关产业迎来新机遇 “没有一种技术是完美的。”西门子Dr. Li回应,“Layer Normalization的优势在于时序数据和小样本场景,但在稀疏数据或超高维数据中,可能需要结合其他方法,工业AI的魅力就在于根据具体问题‘调配方’。”
未来展望:Layer Normalization与工业AI的深度融合
本月绿色交通与在线教育热度持续上升,相关产业迎来新机遇 2026年的工业PaaS平台已不再满足于“数据汇聚”和“模型部署”,而是向“自主优化”和“闭环控制”演进,在这一趋势下,Layer Normalization正与强化学习、联邦学习等技术深度融合,推动工业AI进入新阶段。
在施耐德电气2026年发布的EcoStruxure平台中,Layer Normalization被用于强化学习代理的状态归一化,使智能控制系统能更快适应动态工况;在