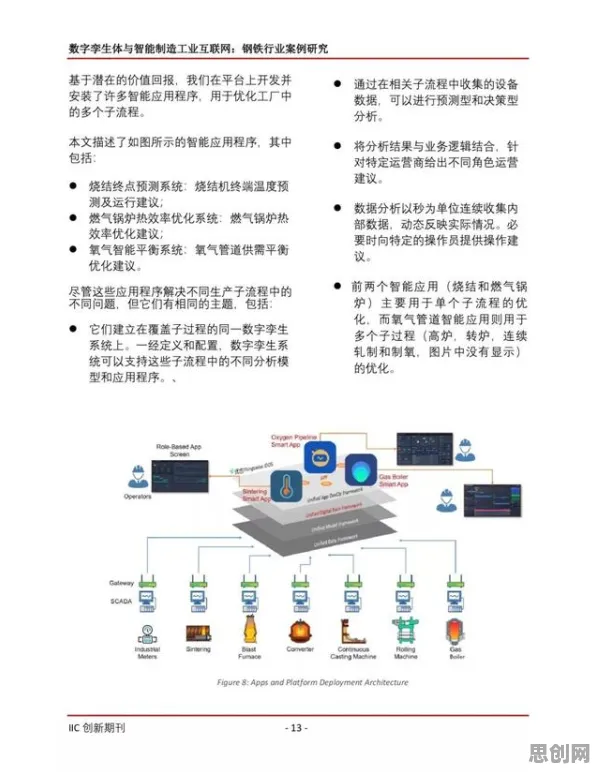
当你在地铁站用手机语音查询下一班列车时刻,当工厂里的机械臂通过语音指令调整生产参数,当医院的智能导诊系统用方言回答患者疑问——这些看似普通的交互场景背后,正涌动着一场由边缘计算驱动的智能问答革命,2026年的今天,全球智能问答系统市场规模已突破870亿美元,但真正决定技术走向的,是那些藏在终端设备里的边缘计算芯片,本文将通过五个关键知识点,揭开这场变革的技术真相。
延迟从2秒到20毫秒:边缘计算如何重塑问答响应速度
"用户问完问题后,系统要在0.3秒内给出第一个有效回复。"这是2026年智能客服行业的黄金标准,但实现这个目标远比想象中复杂,传统云架构下,语音数据需要上传至数据中心处理,往返延迟通常超过2秒,这在车载语音助手等场景中完全不可接受。
边缘计算的介入彻底改变了游戏规则,以特斯拉最新Model Z车型为例,其车载问答系统搭载了NVIDIA Orin X边缘计算平台,在车机端直接完成语音识别、语义理解和回复生成全流程,当驾驶员询问"附近有没有支持V3超充的站点"时,系统无需连接云端,仅需23毫秒就能调取车载导航数据并给出答案,这种本地化处理能力,使得特斯拉在2026年J.D.Power车载语音交互满意度调查中以912分登顶。
但边缘计算不是万能药,某新能源汽车品牌曾尝试将所有AI模型下放至车端,结果导致车载芯片过热频繁死机,最终解决方案是采用"动态分层"架构:常规问题在边缘端处理,复杂问题(如多轮对话)仍上传云端,这种折中方案使系统稳定性提升了40%,但代价是平均响应时间增加到120毫秒——技术选型永远在性能与成本间走钢丝。 2026年绿色湿地保护与植物保护及污水处理热度持续上升,相关产业迎来新机遇
数据不出域:边缘计算如何破解隐私困局
本月垃圾分类与碳关税热度持续上升,相关产业迎来新发展 2026年3月,欧盟《AI法案》正式实施,其中第17条明确规定:涉及个人生物特征、健康数据等敏感信息的AI系统,必须在数据产生设备或本地网络中处理,这条法规直接推动了边缘计算在医疗问答领域的爆发式增长。

上海瑞金医院最新部署的智能导诊系统提供了典型案例,该系统在每个诊室门口配置了搭载高通QCS8550芯片的边缘计算终端,患者用方言描述症状时,语音数据直接在终端完成识别和初步诊断建议生成,原始音频不会上传至医院服务器,系统上线三个月后,患者隐私投诉量下降了76%,而诊断准确率达到92.3%——这一数据甚至超过了部分初级医生。
但边缘端的隐私保护也有代价,某金融客服系统为满足合规要求,在边缘设备上部署了轻量化加密模块,结果导致系统资源占用率飙升35%,原本能同时处理200个会话的服务器,现在只能支撑130个,这个案例揭示了一个残酷现实:在边缘计算场景下,隐私保护与系统性能往往呈现此消彼长的关系。
离线能力:没有网络时,智能问答如何继续工作
本月运动康复与社区公益及压力缓解热度持续上升,相关产业迎来新发展 2026年7月,郑州遭遇特大暴雨导致全市断网,但地铁5号线的智能应急问答系统仍持续运行了18小时,这套由华为昇腾Atlas 300I Pro边缘计算盒子支撑的系统,提前下载了地铁线路图、应急预案等关键数据,在断网期间通过本地语音交互为被困乘客提供疏散指导。
这种离线能力正在成为智能问答系统的标配,美的集团最新推出的智能家居中控屏,内置了阿里平头哥曳影1500边缘芯片,即使没有Wi-Fi也能完成90%的常规问答,当用户询问"空调制热模式怎么开"时,系统会直接调取设备本地存储的操作指南视频,而非像传统方案那样返回"正在连接服务器"的提示。

但离线模式的维护成本高得惊人,某连锁酒店集团发现,其部署在偏远景区的智能前台系统,每月需要人工更新本地知识库两次,每次更新涉及300多个常见问题答案的替换,更棘手的是,当酒店推出新促销活动时,边缘设备上的优惠信息往往要滞后24小时才能同步——离线与实时之间的平衡,仍是待解难题。
成本博弈:边缘计算让问答系统更贵还是更便宜?
"每个边缘终端要多花1200元,但整体TCO降低了30%。"这是海尔智家在2026年智能客服升级项目中的真实数据,传统方案需要为每个客服中心配置高性能服务器,而边缘架构将计算分散到终端设备,虽然单台设备成本增加,但省去了数据中心建设、带宽租赁等大额支出。
当下能源转型热度持续上升,相关产业迎来新机遇 不过这种成本优势具有场景特异性,某银行在试点边缘计算问答系统时发现,在网点密集的城市区域,边缘部署确实降低了总成本;但在农村地区,由于单个网点业务量小,分散的边缘设备反而导致维护成本激增,最终该行采用"区域中心+边缘节点"的混合架构,在县城设置区域计算中心,乡镇网点部署轻量边缘设备,使整体成本优化了18%。
芯片成本波动也在影响技术路线选择,2026年初,由于先进制程产能紧张,某智能音箱厂商被迫将原本计划采用的4nm边缘芯片,替换为12nm成熟工艺产品,虽然性能有所下降,但单颗成本从45美元降至22美元,使得产品毛利率提升了5个百分点——在商业世界,技术先进性有时要让位于成本考量。

模型轻量化:如何在边缘端跑动大语言模型
2026年最受关注的技术突破,莫过于大语言模型(LLM)的边缘化部署,联想最新推出的ThinkPad X1 Carbon笔记本,内置了英特尔酷睿Ultra 9处理器,能在本地运行参数量达70亿的智能问答模型,当用户询问"如何用Python实现快速排序"时,系统不再调用云端API,而是直接在笔记本上生成代码示例并解释算法原理。
但模型压缩技术仍面临挑战,某教育平板厂商尝试将130亿参数的教辅模型部署到设备端,发现即使采用8位量化技术,模型体积仍高达3.2GB,导致设备启动时间延长至15秒,经过三个月优化,工程师们不得不将模型参数量削减至45亿,才勉强满足产品上市要求——在边缘计算场景下,模型精度与资源占用永远需要妥协。
开源社区正在提供新思路,2026年5月,Meta发布的LLaMA-Edge-3B模型,以仅30亿参数实现了接近GPT-3.5的性能表现,这款专为边缘设备设计的模型,已被小米、OPPO等厂商应用于智能手表、AR眼镜等穿戴设备,使得这些功耗敏感的产品也能具备流畅的语音问答能力。
边缘计算与智能问答的未来图景
站在2026年的节点回望,边缘计算对智能问答系统的改造已超出技术范畴,正在重塑整个产业链格局,芯片厂商推出专门针对问答场景的NPU架构,设备制造商将边缘计算能力作为核心卖点,软件开发商则忙着优化模型在ARM架构上的运行效率。
但挑战依然存在:边缘设备的异构性导致开发成本高企,动态网络环境下的无缝切换尚未完美解决,模型更新机制仍需优化,正如Gartner分析师在2026年智能计算峰会上所言:"边缘计算让智能问答系统更接近用户,但也让系统复杂性增加了两个数量级。"
当你在2026年的某个清晨,对着床头柜上的智能音箱询问天气时,这个简单的交互背后,是边缘芯片在纳秒级时间内完成的语音识别、是本地知识库的实时检索、是轻量化模型的瞬间推理,这场静默的技术革命,正在重新定义人与机器的对话方式。