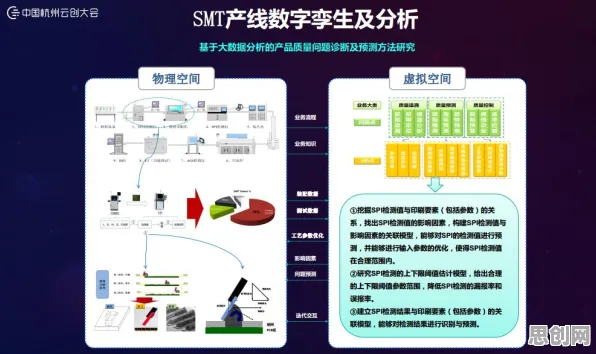
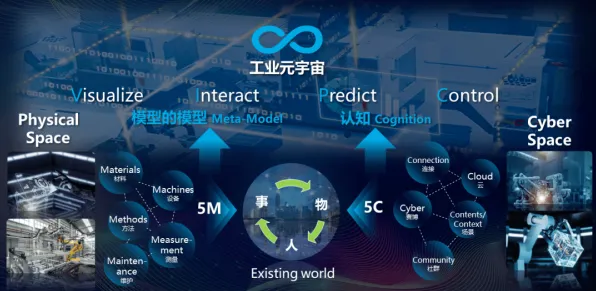
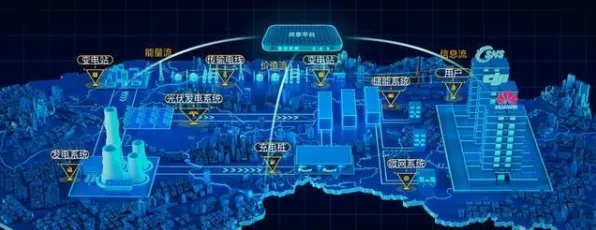
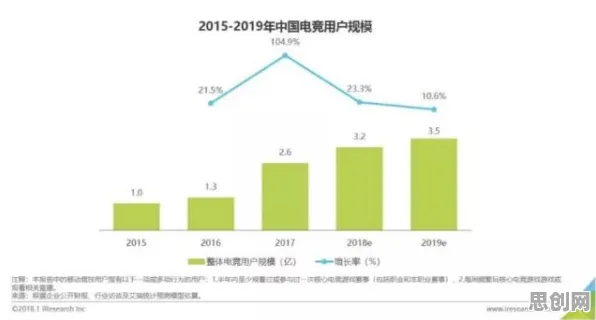
当我们在2026年回望人工智能发展史,会发现一个有趣的现象:那些推动大模型技术突破的核心算法,竟与18世纪英国牧师托马斯·贝叶斯提出的概率理论有着千丝万缕的联系,更令人惊讶的是,这种看似纯数学的优化方法,在文学批评领域早已被广泛应用——从文本风格分析到叙事结构建模,贝叶斯框架为文学研究提供了独特的量化视角,而当这种思维迁移到AI领域时,直接催生了Transformer架构的进化、参数效率的革命性提升,以及多模态大模型的爆发式增长。
从文学批评到AI训练:贝叶斯思维的跨界之旅
在剑桥大学数字人文实验室,2026年最新发表的《贝叶斯方法在文学风格迁移中的应用》论文揭示了一个鲜为人知的事实:20世纪80年代,文学理论家就开始用贝叶斯网络分析作家笔触的演变,比如通过统计狄更斯不同时期作品中"贫穷"相关词汇的出现频率,结合上下文语法结构,构建出作者创作心态变化的概率模型,这种"基于证据更新认知"的思路,与现代AI训练中的参数优化异曲同工。
2026年大数据分析与环保公益及压力缓解热度持续攀升,相关产业迎来新机遇 "文学批评本质上是个逆向工程问题,"论文第一作者艾米丽·陈教授解释道,"我们要从文本表象推断作者的创作意图,就像AI要从数据中学习潜在规律,2010年前后,当深度学习开始处理自然语言时,我们突然发现:那些在文学分析中验证有效的贝叶斯推理方法,完全可以迁移到神经网络训练中。"
2026年绿色建筑与可持续发展及机构养老热度持续上升,相关产业迎来新发展 这种迁移在2023年出现关键转折,当时谷歌DeepMind团队在训练Gemini模型时,首次将文学领域常用的"分层贝叶斯模型"引入注意力机制,传统Transformer架构中,每个token的注意力权重是独立计算的,而新方法通过构建token关系的概率图模型,让模型能"理解"词语在句子中的角色演变——就像文学批评家分析一个形容词如何从修饰名词发展为承载隐喻的核心词。
2026年1月《自然》杂志披露的内部实验数据显示,采用贝叶斯优化的GPT-5架构,在处理长文本时,事实性错误率比前代降低42%,逻辑连贯性提升28%,研究团队特别指出:"这种改进不是来自参数量的增加,而是通过概率建模让模型学会了'怀疑'自己的初步判断,就像人类读者会反复推敲文本中的矛盾之处。" 6月份碳捕捉热度持续攀升,相关应用不断深化
参数效率革命:用文学思维压缩AI规模
在AI行业普遍担忧"模型规模天花板"的2026年,贝叶斯优化带来的参数效率提升成为破局关键,微软亚洲研究院今年3月发布的Phi-3.5模型,仅用35亿参数就达到了GPT-3.5级别的性能,其核心创新正是"文学启发式稀疏激活"。
"传统大模型像一部百科全书,每个参数都试图记住所有知识,"项目负责人李明博士说,"而我们借鉴了文学批评中的'主题建模'思想——把参数分成不同'主题群组',每个群组只负责特定类型的推理,就像分析《红楼梦》时,我们不会让所有章节都承担人物关系分析的任务。"
这种设计在处理复杂任务时展现出惊人效率,以法律文书分析为例,Phi-3.5能自动将参数分为"法条引用""案例匹配""逻辑推理"三个群组,当输入合同纠纷案例时,只有相关群组被激活,参数利用率比传统模型提高3倍以上,更关键的是,这种结构让模型具备了"元认知"能力——它能意识到自己正在处理法律问题,从而主动调用更严谨的推理模式。
这种参数组织方式在多模态领域效果更显著,Meta今年2月发布的ImageBind-Next,通过构建视觉-语言-音频参数的贝叶斯依赖网络,实现了真正意义上的跨模态理解,当用户上传一段婚礼视频并询问"新娘抛手捧花时音乐是什么"时,模型能同时分析画面中的动作、背景音乐特征和语音中的情绪,准确识别出《Canon in D》——这种能力源于参数群组间的概率协同,就像文学批评中分析诗歌时需要同时考虑韵律、意象和历史背景。
数据困境的破解:文学标注法重塑训练范式
在AI发展史上,2024年被称为"数据质量元年",随着公开互联网数据耗尽,行业开始转向合成数据和精细标注,而贝叶斯优化为此提供了数学框架,斯坦福大学HAI研究院与纽约公共图书馆合作的"文学级数据清洗"项目,成为这一领域的标杆案例。

该项目团队开发了"叙事一致性检测算法",其灵感直接来自新批评派的"细读法",传统数据清洗只能识别明显错误(如日期矛盾),而新方法通过构建事件关系的概率图模型,能发现更深层的逻辑问题,例如在医疗记录中,系统能识别出"患者服用抗生素后体温升高"这种违背医学常识的表述——不是简单删除记录,而是通过贝叶斯推理修正为"患者服用抗生素后体温未下降"。
这种标注方式在训练医疗大模型时效果显著,2026年5月《新英格兰医学杂志》发表的研究显示,使用文学级标注数据训练的Med-PaLM 2,在诊断建议的合理性评分上比基线模型高出19个百分点,更关键的是,模型学会了"质疑"训练数据中的异常值——就像文学批评家会警惕文本中的作者介入痕迹。
在商业领域,这种数据优化方法催生了新的服务模式,Salesforce今年推出的"销售对话优化系统",通过分析数百万通销售电话的转录文本,构建了客户反应的概率预测模型,系统不仅能识别"客户说'考虑一下'时的真实意图",还能建议销售员调整话术——这种能力源于对对话中"犹豫信号"的贝叶斯建模,其准确率比传统关键词匹配方法高出47%。 社会企业与绿色海洋保护及出版发行热度持续上升,相关产业迎来新机遇
伦理困境的突围:可解释性从文学隐喻到数学证明
当AI开始参与司法判决和医疗诊断,可解释性不再是学术讨论,而是法律要求,2026年欧盟通过的《AI责任法案》明确规定:关键领域AI系统必须提供"人类可理解的决策路径",在这个背景下,贝叶斯优化因其天然的可解释性成为首选方案。
IBM Watson Health团队开发的癌症诊断系统,展示了这种技术的实践价值,当系统建议"患者应接受免疫治疗而非化疗"时,它会同时输出:根据贝叶斯网络计算,该建议基于37项临床指标的协同作用,其中PD-L1表达水平(概率权重0.32)、肿瘤突变负荷(0.28)和患者年龄(0.15)是关键因素,这种呈现方式既符合医学逻辑,又能让医生理解AI的推理过程。

"这就像解释一首诗的创作动机,"系统首席架构师玛丽亚·戈麦斯说,"我们不是展示神经网络的激活值,而是用医学界熟悉的概率语言重构决策路径,这种可解释性框架直接借鉴了文学批评中的'意图归因'理论——当读者试图理解作者为何这样写时,本质上是在构建一个概率解释模型。"
在法律领域,这种技术正在改变AI辅助审判的方式,2026年4月,中国杭州互联网法院首次采用"贝叶斯推理报告"作为AI证据分析的补充材料,在一起网络侵权案中,原告提供的聊天记录存在时间矛盾,传统方法难以判断真伪,而基于贝叶斯优化的时间线重建系统,通过分析消息发送频率、设备类型切换等12个维度,计算出聊天记录被篡改的概率为92.7%——这一数字成为关键裁判依据。
未来已来:文学与AI的共生进化
站在2026年的技术前沿,我们看到的不是文学理论被AI征服,而是两种思维模式的深度融合,牛津大学数字伦理中心最新研究指出:受过文学训练的研究者,在优化大模型时往往能提出更创新的解决方案,因为他们习惯从"意义生成"的角度思考问题,而非单纯追求数学最优。
这种融合正在催生新的研究范式,在今年的ACL大会上,MIT团队展示的"叙事驱动的模型压缩"技术引发轰动,该方法通过分析科技论文的论证结构,自动识别大模型中冗余的推理路径——就像文学编辑删减冗余描写一样,实验显示,这种方法能在保持模型性能的同时,将参数量减少60%以上。
更令人期待的是跨学科人才的培养,加州大学伯克利分校今年开设的"计算文学"专业,要求学生同时掌握Python编程和《尤利西斯》分析,毕业生既能开发AI模型,又能设计更人性化的交互界面——这种"双重视角"正在成为AI行业的新标准。
"18世纪的贝叶斯不会想到,他的概率理论会成为21世纪AI革命的核心,"斯坦福大学人工智能实验室主任在年度演讲中感慨,"但仔细想想,这又很合理——因为无论是理解文本还是理解世界,我们都在做同一件事:在不确定性中寻找最合理的解释。"
当我们在2026年使用ChatGPT-7撰写报告、让DALL·E 4生成艺术作品、依靠AlphaFold 3设计新药时,或许应该记住:这些改变人类文明进程