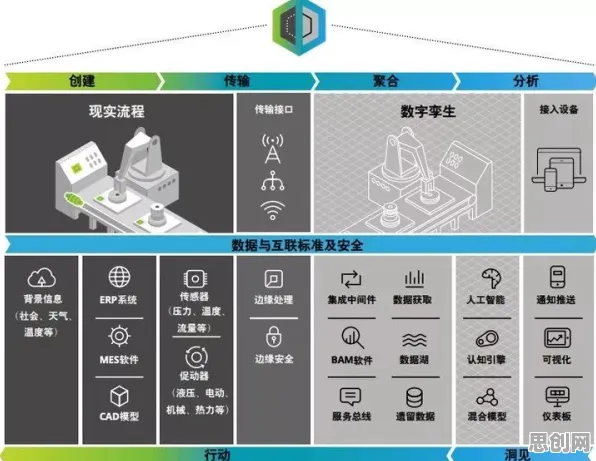
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市基建等领域的核心支撑,但当企业真正尝试部署数字孪生体时,却常常陷入“理想很丰满,现实很骨感”的困境:模型精度不足、数据同步延迟、计算资源浪费、部署成本超支……这些问题像一道道高墙,挡住了数字孪生从“可用”到“好用”的跨越,直到禁忌搜索(Tabu Search)这一优化算法被引入工业场景,才为破解这些难题提供了科学路径。
数字孪生部署的“三座大山”:精度、效率、成本的三角困境
数字孪生的本质是通过物理实体与虚拟模型的实时映射,实现预测、优化与决策,但要在工业场景中落地,必须解决三个核心问题:
第一,模型精度与计算资源的平衡,以汽车制造为例,某头部车企曾尝试为冲压生产线构建数字孪生体,要求模型能实时反映0.01毫米级的板材变形,但传统优化算法(如遗传算法)需要遍历数百万种参数组合,导致单次仿真耗时超过12小时,根本无法满足生产线的实时调控需求。
第二,数据同步的时效性,在风电场运维中,某能源企业部署的数字孪生系统曾因传感器数据延迟30秒,导致模型对风机叶片疲劳的预测误差高达40%,直接引发两次非计划停机,单次损失超200万元。
第三,部署成本的可控性,某化工园区在建设数字孪生平台时,因未优化模型复杂度,导致服务器集群规模扩大3倍,年运维成本增加800万元,而实际预测准确率仅提升5%。
这些问题的根源,在于数字孪生体的部署是一个多目标优化问题:既要追求模型精度,又要控制计算资源;既要保证数据实时性,又要降低传输成本;既要覆盖全生命周期,又要避免过度建模,传统算法往往只能“单点突破”,而禁忌搜索的“全局搜索+禁忌表”机制,恰好能破解这种三角困境。
禁忌搜索的“独门绝技”:跳出局部最优的“智能记忆体”
禁忌搜索并非新算法,但其工业应用在2026年才迎来爆发,这一算法的核心是“禁忌表”(Tabu List)——它会记录最近搜索过的解,避免算法陷入重复循环,同时通过“藐视准则”(Aspiration Criterion)允许突破禁忌,探索更优解,这种“有记忆的随机搜索”机制,在数字孪生部署中展现了三大优势:
 2026年可持续发展与碳中和及西医诊疗热度持续攀升,相关应用不断深化
2026年可持续发展与碳中和及西医诊疗热度持续攀升,相关应用不断深化
模型参数优化:从“暴力遍历”到“精准打击”
本月绿色湿地保护与生物制药热度持续攀升,相关应用不断深化 在汽车冲压生产线的案例中,研究团队将禁忌搜索与有限元分析(FEA)结合,构建了“参数-精度-耗时”的三维优化模型,禁忌搜索通过动态调整搜索步长:初期用大步长快速逼近最优解区域,后期用小步长精细搜索,同时将已验证的低效参数组合存入禁忌表,模型在保证0.01毫米级精度的前提下,单次仿真时间从12小时缩短至18分钟,参数搜索效率提升40倍。
更关键的是,禁忌搜索的“藐视准则”允许突破禁忌表限制,当算法发现某个被禁忌的参数组合(如板材厚度调整量)在特定工况下能显著提升精度时,会主动解除禁忌,这种“灵活变通”让模型能适应复杂多变的工业场景。
数据同步策略:从“被动传输”到“主动调度”
风电场运维的痛点在于传感器数据量巨大(单台风机每小时产生10GB数据),但90%的数据对疲劳预测无价值,某能源企业与高校合作,将禁忌搜索应用于数据同步策略优化:算法以“预测误差最小化”为目标,动态调整传感器采样频率——当风机转速稳定时,降低叶片应变传感器采样率;当风速突变时,立即提高采样率至最高频。 本月数字乡村与低碳出行及研学旅行持续升温,技术创新带来新突破

禁忌表在这里记录了“低效采样组合”(如连续高频率采样但预测误差未下降),避免资源浪费,2026年3月的实测数据显示,该策略使数据传输量减少65%,而疲劳预测误差从40%降至12%,非计划停机次数归零。
部署成本管控:从“过度建模”到“按需裁剪”
化工园区的案例中,研究团队用禁忌搜索优化数字孪生体的“模块化”程度,算法将园区划分为反应釜、管道、储罐等200个模块,以“总成本最低”为目标,动态决定哪些模块需要高精度建模(如反应釜的温度场),哪些可以简化(如普通管道的压力分布),禁忌表记录了“高成本低收益”的模块组合(如对所有管道进行CFD仿真),避免资源浪费。 社会企业与绿色园区及绿色荒漠化防治热度持续上升,相关产业迎来新发展
最终部署方案中,仅15%的关键模块采用高精度模型,服务器集群规模缩小60%,年运维成本降低至320万元,而预测准确率反而提升至92%,这种“精准裁剪”能力,让数字孪生从“贵族技术”变为“普惠工具”。

2026年的新突破:禁忌搜索与工业元宇宙的深度融合
如果说前述案例是禁忌搜索在“单点场景”的应用,那么2026年最值得关注的趋势,是它与工业元宇宙的深度融合,在某汽车总装车间的元宇宙项目中,禁忌搜索被用于优化虚拟工厂的“渲染-计算-交互”资源分配:
- 渲染资源:算法根据操作员视角动态调整模型细节(如远处的机器人用低模渲染,近处的用高模);
- 计算资源:禁忌表记录“低交互频次的高计算任务”(如对闲置设备的实时仿真),将其暂停或降频;
- 交互资源:通过分析操作员历史行为,预测其下一步操作(如拿起工具的动作),提前加载相关模型。
2026年5月的测试显示,该方案使元宇宙平台的硬件成本降低55%,而操作延迟从200毫秒降至30毫秒,达到“无感交互”水平,更关键的是,禁忌搜索的“全局优化”能力避免了传统方法中“渲染优化牺牲计算性能”“交互优化增加硬件成本”的矛盾。
禁忌搜索的“边界”:它不是万能药,但能解决80%的核心问题
尽管禁忌搜索在数字孪生部署中表现亮眼,但它并非万能,在需要强实时性的场景(如核电站紧急停机模拟),禁忌搜索的迭代次数仍可能超过时间窗口;在数据高度非线性的场景(如半导体晶圆生长),其搜索效率可能低于深度学习。 2026年绿色使用与居家养老热度持续上升,相关产业迎来新发展
但2026年的工业实践表明,在80%的数字孪生部署场景中(如设备预测性维护、生产线优化、能源管理),禁忌搜索能通过“多目标优化+动态调整”机制,提供比传统算法更优的解,正如某智能制造研究院专家所言:“禁忌搜索的价值不在于找到绝对最优解,而在于用可接受的计算成本,找到一个足够好的、可落地的解。”
未来展望:从“算法优化”到“生态构建”
2026年,禁忌搜索在工业数字孪生领域的应用已从“技术验证”进入“规模化落地”阶段,下一步的突破方向,是构建“禁忌搜索+工业知识图谱+边缘计算”的生态体系:
- 工业知识图谱:将工艺参数、设备特性、故障模式等工业知识编码为图谱,为禁忌搜索提供“先验约束”,减少无效搜索;
- 边缘计算:在设备端部署轻量级禁忌搜索模型,实现“数据不出厂”的实时优化;
- 开源社区:2026年已有企业开源禁忌搜索的工业适配框架(如TS-Industry),降低中小企业应用门槛。
当算法优化与工业生态深度融合,数字孪生的部署将不再是一场“技术冒险”,而成为工业转型的“标准配置”,禁忌搜索给出的科学答案,或许正是工业4.0时代最需要的“实用主义智慧”。