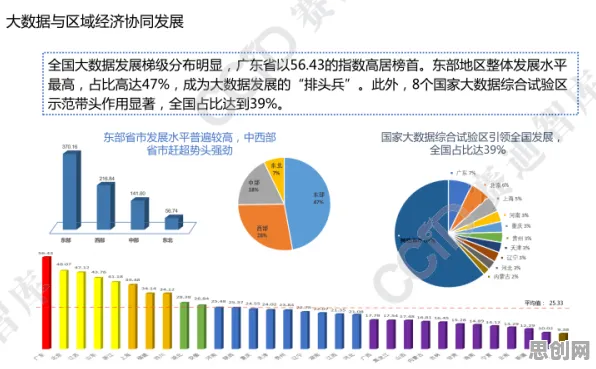
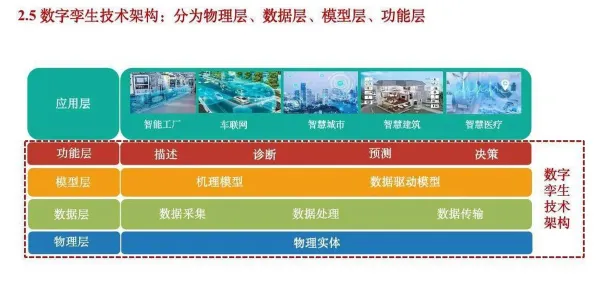
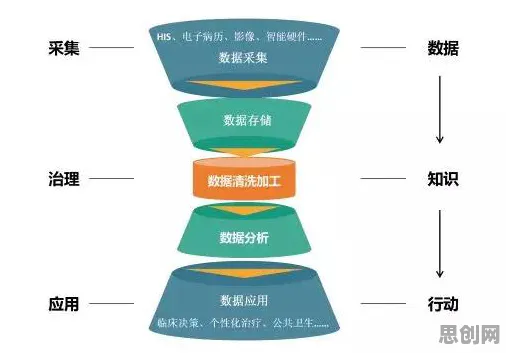
在2026年的工业领域,"数字孪生"早已不是新鲜词,但当用数据科学的棱镜重新审视这项技术时,你会发现那些看似常规的应用场景里,藏着颠覆传统认知的底层逻辑,这不是简单的"虚拟建模",而是一场由数据驱动的工业认知革命——从设备健康管理到供应链优化,从工艺迭代到能源调度,数字孪生正在用数据科学的方式重新定义"工业智能"。 本月绿色标签与量子计算热度持续上升,相关产业迎来新发展
数据采集:从"能采尽采"到"精准捕获"的范式转变
传统工业数字孪生的数据采集常陷入"大而全"的误区:在某汽车制造企业的早期实践中,工程师为一条冲压生产线部署了2000多个传感器,试图覆盖所有可能的物理参数,但运行三个月后发现,真正用于故障预测的有效数据不足15%,其余85%的数据要么是冗余的静态参数(如设备型号、安装日期),要么是低频变化的次要指标(如环境湿度),这种"广撒网"式采集不仅推高了硬件成本,更让后续的数据处理陷入"数据沼泽"。
2026年,数据科学的介入让采集策略发生根本性转变,在深圳某3C电子工厂的实践中,工程师们采用"特征驱动采集"方法:先通过历史故障数据训练机器学习模型,识别出与设备故障强相关的12个关键特征(如电机振动频谱中的特定峰值、液压系统压力的波动斜率),再针对这些特征反向设计传感器布局,结果,传感器数量从1500个锐减至87个,但故障预测准确率从68%提升至92%,数据存储成本降低70%。
这种转变的背后是数据科学的"因果推理"思维——不再追求数据的"量",而是聚焦数据的"质",正如西门子工业软件首席数据科学家李明在2026年工业数据峰会上所言:"数字孪生的数据采集应该像医生看病:先通过症状(特征)定位问题,再选择对应的检查手段(传感器),而不是让病人做全套体检。"
数据融合:打破"信息孤岛"的物理-虚拟映射革命
工业场景中,数据孤岛是数字孪生落地的最大障碍,某钢铁企业的案例极具代表性:其高炉数字孪生系统初期整合了DCS(分布式控制系统)的工艺数据、MES(制造执行系统)的生产数据、EAM(企业资产管理)的维护数据,但运行后发现,模型预测的炉温与实际偏差达15℃——原因在于忽略了来自环境监测系统的气象数据(湿度、气压)对燃料燃烧效率的影响。

2026年,数据融合技术正在解决这类问题,在青岛某家电制造企业的实践中,工程师们构建了"四维数据融合框架":
- 空间维度:通过UWB定位技术将设备数据与车间3D模型绑定,实现"数据-空间"的精准映射;
- 时间维度:采用时序数据库整合毫秒级的过程数据与天级别的维护数据,捕捉长周期衰减规律;
- 逻辑维度:利用知识图谱将工艺参数、设备状态、质量缺陷等200余类实体关联,形成可解释的因果链;
- 物理维度:通过数字孪生核心算法将多源数据转换为统一的"物理量纲",消除不同系统间的计量差异。
这套框架运行后,该企业空调外机生产线的数字孪生模型预测准确率从73%提升至89%,更关键的是,当模型预警某台氦检设备可能漏检时,工程师能通过知识图谱快速定位到"前道工序真空度不足→氦检压力阈值偏移"的完整逻辑链,而非仅停留在设备层面的报警。
模型训练:从"黑箱模型"到"可解释AI"的工业认知升级
早期工业数字孪生常被诟病为"黑箱操作":某化工企业的反应釜数字孪生模型能准确预测产物收率,但工程师无法理解"为什么温度升高2℃会导致收率下降1.5%"——这种不可解释性严重限制了模型在关键工艺环节的应用。 2026年体育赛事与能源互联网及影视制作热度持续攀升,相关产业迎来新机遇
2026年,可解释AI(XAI)技术正在改变这一局面,在宁德时代某电池工厂的实践中,工程师们采用"双模型架构":底层用LSTM神经网络处理时序数据,上层用SHAP(Shapley Additive exPlanations)算法为每个预测结果生成"解释报告",当模型预测某条叠片线的不良率将上升时,解释报告会显示:"主要贡献因素:极片张力波动(贡献度42%),次要因素:隔膜对齐度偏差(贡献度28%)",并附上历史案例中类似参数组合下的实际不良率数据。

这种"预测+解释"的模式让一线工人从"被动接受"转向"主动信任",该工厂的数据显示,引入XAI后,模型建议的采纳率从58%提升至89%,工艺调整的响应时间缩短60%,正如工厂数字化总监王强所说:"工人需要知道'为什么',而不是仅仅被告知'做什么'——这才是工业AI真正落地的关键。" 社会企业与隐私保护及绿色消费热度持续走高,行业关注度持续提升
实时仿真:从"离线推演"到"在线闭环"的决策革命
快速推进关注废物利用发展动态,技术创新推动产业升级 传统数字孪生的仿真多是离线进行的:某风电企业每月运行一次风机数字孪生模型,根据仿真结果调整维护计划,但这种"事后优化"模式无法应对突发故障,2025年台风"海燕"期间,该企业某风电场因未能及时调整叶片角度,导致3台机组受损,直接损失超2000万元。
2026年,实时仿真技术正在改变游戏规则,在金风科技某海上风电场的实践中,工程师们构建了"边缘-云端协同仿真系统":边缘端(风机控制器)每10秒采集一次风速、转速、功率等数据,通过轻量化模型实时计算最优叶片角度;云端每5分钟运行一次高精度仿真,验证边缘决策的合理性,并动态更新模型参数,2026年夏季,当台风"银杏"逼近时,系统提前12小时预测到某台机组可能因极端风速过载,自动触发叶片顺桨指令,避免了重复去年的损失。
这种"在线闭环"模式的背后是数据科学的"反馈控制"思维——将仿真结果作为新的输入反馈到系统中,形成"数据采集-模型计算-决策执行-效果评估"的完整闭环,正如金风科技首席数字官陈磊所言:"未来的数字孪生不是静态的'数字镜像',而是能自主进化的'工业大脑'。"

场景拓展:从"设备级"到"产业链级"的认知跃迁
早期数字孪生多聚焦于单台设备或单个车间,但2026年的实践显示,其价值正在向产业链延伸,在比亚迪新能源汽车供应链的实践中,工程师们构建了"全链条数字孪生系统":
- 供应商端:通过物联网采集电池原材料(如锂矿)的开采数据,结合地质模型预测矿石品位波动,提前调整采购计划;
- 生产端:整合冲压、焊接、涂装、总装四大工艺的数字孪生模型,实现产能的动态平衡;
- 物流端:利用数字孪生模拟不同运输路线(海运/铁路/公路)的碳排放与成本,优化物流方案;
- 客户端:通过车载传感器采集车辆运行数据,反向优化设计参数(如电机效率、电池衰减曲线)。
2026年一季度,该系统帮助比亚迪将供应链响应速度提升40%,库存周转率提高25%,更关键的是,当某锂矿供应商因暴雨停产时,系统通过分析历史数据与市场趋势,建议"启用备用供应商+调整生产节奏"的组合方案,避免了整条产业链的停摆风险。
这种"产业链级"数字孪生的本质是数据科学的"系统思维"——将工业视为一个由多个子系统构成的复杂网络,通过数据流动实现全局优化,正如比亚迪数字化负责人刘伟所说:"单个设备的数字孪生是'点',车间的数字孪生是'线',而产业链的数字孪生才是'面'——这才是工业4.0的终极形态。" 2026年能量回收与社会实践及低碳出行领域取得重要进展,行业关注度持续提升
数据安全:从"被动防御"到"主动免疫"的范式突破
工业数字孪生的数据安全一直是痛点:某汽车零部件企业曾因数字孪生系统被攻击,导致竞争对手获取了其核心工艺参数,直接损失超5000万元,传统安全方案多依赖防火墙、加密等"被动防御"手段,但2026年的实践显示,"主动免疫"正在成为新趋势。
在华为某5G工厂的实践中,工程师们采用"数据沙箱+联邦学习"的混合架构:
- 数据沙箱:将数字孪生模型运行在隔离的沙箱环境中,所有外部