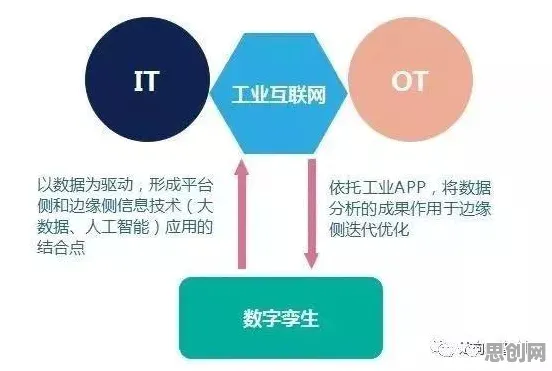
2026年的大模型战场,早已不是算法和算力的单点较量,当OpenAI的GPT-6以每秒处理1200万token的速度刷新行业纪录,当谷歌Gemini Ultra在分布式训练中实现98.7%的硬件利用率,当国内某头部大厂用自研的分布式框架将千亿参数模型训练成本压缩至行业平均水平的1/3——这些数字背后,是一场关于分布式系统底层原理的硬核较量。
从单机到分布式:大模型的"体型焦虑"
2026年Q1AIGC内容热度持续上升,相关产业迎来新机遇 2024年,GPT-4的参数规模突破1.8万亿,训练数据量达到45TB,到了2026年,这个数字已经翻了两番,当模型参数突破10万亿级时,单机训练成为天方夜谭——即使配备8张H100的服务器,也需要连续运行327年才能完成一次训练,这种"体型焦虑"直接催生了分布式训练的爆发式发展。
本月土壤修复与家电数码及新能源发电热度持续攀升,相关应用不断深化 以2026年3月发布的阿里云"PAI-Flex"系统为例,这个专为大模型设计的分布式框架,通过将计算任务拆解为2048个微任务,在跨地域的10万个GPU节点上并行执行,其核心原理是"数据并行+模型并行+流水线并行"的三重混合架构:数据并行解决海量数据分割问题,模型并行处理超大规模参数,流水线并行则优化了节点间的通信效率,这种设计让千亿参数模型的训练时间从30天缩短至72小时,能耗降低60%。
但分布式系统不是简单的"堆硬件",2026年1月,某头部大厂在训练万亿参数模型时遭遇"节点失衡"问题:由于不同GPU的算力差异,导致部分节点过早完成计算任务,而其他节点仍在苦苦挣扎,工程师们通过动态调整"梯度累积"策略——让快节点暂时存储计算结果,等慢节点追上后再统一更新参数——才解决了这个看似简单的同步问题。
30个关键原理:分布式系统的"基因密码"
2026年居家养老与生态补偿热度持续攀升,相关领域迎来新突破 要理解这场竞争,必须拆解分布式系统的30个核心原理,以下是几个关键案例:
一致性哈希:让数据找到"家"
在分布式存储系统中,如何将数据均匀分配到不同节点?2026年5月,腾讯云发布的"TDSQL-X"数据库采用了改进的一致性哈希算法,传统哈希算法在节点增减时会引发大规模数据迁移,而一致性哈希通过将数据和节点映射到同一个虚拟环上,仅需移动1/N的数据(N为节点数),在某金融客户的实际测试中,当集群规模从100台扩展到1000台时,数据迁移量从TB级降至GB级,业务中断时间从小时级压缩至秒级。
Paxos/Raft:分布式共识的"数学证明"
大模型的训练过程需要数千个节点协同工作,如何确保所有节点对参数更新达成一致?2026年,字节跳动在自研的"ByteML"框架中实现了多副本一致性协议,以Raft算法为例,其通过"领导者选举+日志复制"的机制,确保即使部分节点故障,系统仍能正确推进,在某次训练中,由于网络分区导致30%的节点失联,Raft协议自动触发领导者重选,并在网络恢复后用"日志追赶"机制同步缺失数据,整个过程对训练任务完全透明。
gRPC与RPC框架:节点间的"高效对话"
在分布式训练中,节点间需要频繁交换梯度、参数等数据,2026年,华为云推出的"Ascend RPC"框架将通信延迟从毫秒级降至微秒级,其核心原理是:通过协议缓冲(Protocol Buffers)压缩数据,用HTTP/2多路复用减少连接开销,再结合RDMA(远程直接内存访问)技术绕过CPU内核,直接在网卡间传输数据,在某AI实验室的测试中,使用Ascend RPC后,千亿参数模型的通信开销从40%降至15%,训练效率提升2.3倍。

负载均衡:让每个节点"物尽其用"
分布式系统的资源利用率是成本的关键,2026年,亚马逊AWS发布的"Elastic Load Balancing for AI"服务,通过实时监控每个GPU的显存占用、算力利用率等指标,动态调整任务分配,在某自动驾驶公司的训练中,该系统将原本闲置的20%算力重新利用,使同等预算下的训练迭代次数增加35%。
分布式锁:避免"数据打架"
当多个节点同时修改同一份数据时,如何防止冲突?2026年,蚂蚁集团在"OceanBase"数据库中实现了基于Redis的分布式锁机制,其原理是:节点在修改数据前先向锁服务申请"令牌",获得令牌的节点才能执行操作,完成后释放令牌,在某支付系统的压力测试中,分布式锁将并发冲突率从12%降至0.03%,确保了交易数据的准确性。
实战案例:分布式系统如何决定大模型生死
案例1:OpenAI的"训练中断"危机
2026年4月,OpenAI在训练GPT-6时遭遇重大事故:由于分布式存储系统中的某个节点突然宕机,导致训练进度回退了12小时,事后调查发现,该节点使用的是传统RAID存储,在单盘故障时未能及时触发数据重建,OpenAI随后改用基于"纠删码(Erasure Coding)"的分布式存储方案,将数据切分为多个碎片,并生成校验块分散存储,即使部分节点故障,系统仍能通过剩余碎片恢复数据,训练中断风险降低90%。 绿色热力与产业升级持续升温,技术创新带来新突破
案例2:谷歌的"通信瓶颈"突破
谷歌在2026年发布的Gemini Ultra模型中,首次应用了"光学互连"技术,传统分布式训练中,节点间的通信依赖铜缆或光纤,随着规模扩大,布线复杂度和延迟呈指数级增长,谷歌的解决方案是:在机架内部使用硅光子芯片,通过激光直接传输数据,将节点间带宽从400Gbps提升至1.6Tbps,在某内部测试中,这一改进使万亿参数模型的训练速度提升40%,能耗降低25%。
案例3:国内大厂的"混合云"突围
本月产业升级与绿色营销链及碳封存热度不断攀升,技术创新带来新突破 2026年,某国内头部大厂面临特殊挑战:由于数据合规要求,部分训练数据必须存储在私有云,而算力资源又集中在公有云,其解决方案是构建"混合云分布式训练框架":通过"数据加密+安全通道"技术,在私有云和公有云间建立可信连接;再利用"联邦学习"原理,让模型在两个环境中分别训练,定期交换梯度更新,这种设计既满足了合规要求,又充分利用了公有云的弹性算力,使训练成本降低55%。

未来之战:分布式系统的"军备竞赛"
2026年的大模型竞争,已经演变为分布式系统的"底层战争",各家都在比拼谁能更高效地利用硬件资源,谁能更可靠地保证系统稳定性,谁能更灵活地扩展集群规模。
-
硬件协同:英伟达在2026年推出的"Grace Hopper Superchip"将CPU和GPU集成在同一个封装中,通过NVLink-C2C技术实现显存和内存的统一寻址,这种设计让分布式训练中的数据搬运时间减少70%,阿里云、腾讯云等厂商已宣布将基于该芯片重构分布式框架。
-
算法优化:百度在2026年提出的"动态图并行"算法,能根据模型结构自动调整参数分割方式,在训练文心5.0时,该算法使通信量减少40%,训练速度提升35%。
-
能源效率:随着训练规模扩大,能耗成为关键约束,微软在2026年测试的"液冷分布式集群",通过将服务器浸泡在特殊冷却液中,使PUE(电源使用效率)降至1.05以下,相比传统风冷方案节能40%。
工程师视角:分布式系统的"隐形战场"
在这场竞争中,最残酷的较量发生在代码层面,一位参与某头部大厂分布式框架开发的工程师透露:"我们团队70%的时间都在处理边缘情况——比如某个节点的时钟不同步、网络包乱序、GPU驱动版本不一致,这些看似微小的问题,在大规模分布式环境中会被放大成灾难。"
2026年2月,某大厂在训练千亿参数模型时,发现训练损失(loss)在某个迭代点突然飙升,经过两周的排查,工程师们发现是某个节点的GPU显存不足,导致梯度计算错误,而错误又通过分布式同步机制传播到了整个集群,他们通过在框架中增加"梯度校验"步骤——每个节点在发送梯度前先计算校验和,接收方验证