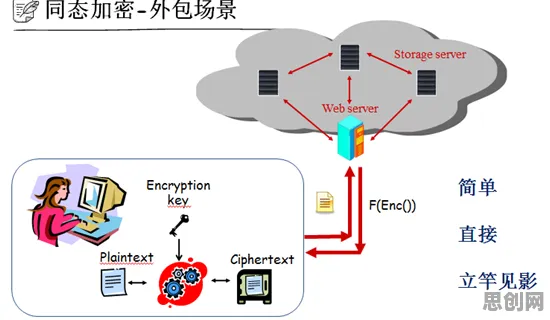
2026年开春,一场关于工业数字孪生体的技术风暴席卷了制造业圈,从上海浦东的智能工厂到重庆两江新区的汽车生产线,从苏州工业园的精密加工车间到深圳南山区的电子装配线,企业技术负责人、工程师、行业专家们都在讨论同一个话题:数字孪生体到底该怎么用?怎么用得好?这场热议的导火索,是3月初中国工业互联网研究院联合多家头部企业发布的《2026工业数字孪生体应用白皮书》,以及随后在杭州举办的“工业数字孪生体应用方案分享会”——这场吸引了超2000名行业人士参与的会议,不仅展示了12个行业标杆案例,更因“大模型+数字孪生”的融合方案引发了激烈争论。
一场分享会,为何能掀起行业热议?
“我们以前觉得数字孪生就是做个3D模型,现在才发现连‘孪生’的逻辑都错了。”分享会上,某汽车零部件企业CTO李明的发言引发了全场共鸣,他展示的案例中,企业为一条价值1.2亿元的压铸生产线搭建了数字孪生体,原本计划通过模拟优化生产节拍,结果运行3个月后发现:孪生模型与物理设备的参数偏差超过15%,导致优化方案在实际生产中完全失效,更尴尬的是,当企业试图用AI大模型修正模型时,又因缺乏高质量的实时数据,导致大模型“喂不饱”,最终项目陷入停滞。
李明的案例并非个例,白皮书数据显示,2025年国内工业数字孪生体项目失败率高达43%,其中62%的失败源于“模型与物理实体脱节”,31%源于“数据质量不足”,这些问题在分享会上被集中暴露:某家电企业为空调生产线搭建的孪生体,因未考虑季节性温湿度变化,模拟的能耗数据与实际偏差达28%;某化工企业为反应釜建立的孪生模型,因未接入实时压力传感器数据,导致模拟的爆炸风险预警比实际晚17分钟——这些案例让在场的企业代表们脊背发凉。
“数字孪生不是‘炫技’,而是要解决实际问题。”中国工业互联网研究院副院长王伟在分享会上直言,“现在很多企业把数字孪生当成了‘面子工程’,花几百万做个3D模型,却连最基本的参数同步都做不到,这样的孪生体有什么用?”他展示的一组对比数据更让人警醒:某钢铁企业通过优化数字孪生体应用方案,将高炉故障预测准确率从68%提升至92%,年减少停机损失超5000万元;而另一家企业因孪生模型更新滞后,导致一批价值800万元的零部件因参数错误全部报废。
 聚焦绿色空气净化与绿色标识及绿色森林保护发展新趋势,应用场景不断拓展
聚焦绿色空气净化与绿色标识及绿色森林保护发展新趋势,应用场景不断拓展
大模型来了,数字孪生体该怎么“升级”?
分享会的另一个焦点,是“大模型+数字孪生”的融合方案,华为云工业互联网解决方案总监张磊展示的案例引发了激烈讨论:某新能源汽车电池工厂通过引入盘古大模型,将数字孪生体的参数更新频率从每小时1次提升至每分钟1次,故障预测准确率从75%提升至89%。“传统数字孪生体依赖人工设定规则,而大模型可以通过海量数据自主学习,自动修正模型偏差。”张磊解释,“比如电池生产中的涂布工序,传统方法需要工程师手动调整12个参数,现在大模型可以根据实时数据自动优化,效率提升3倍。”
但这一方案也引发了争议,某航空制造企业信息化负责人王强提出质疑:“大模型需要海量数据训练,但工业场景的数据往往分散在多个系统中,且涉及商业机密,怎么解决数据孤岛和安全问题?”他所在的企业曾尝试用大模型优化飞机零部件加工,但因数据权限问题,只能使用脱敏后的历史数据,导致模型训练效果大打折扣。
对此,阿里云工业大脑负责人陈敏给出了解决方案:“我们通过‘联邦学习+边缘计算’的技术架构,让数据在本地设备上训练,只上传模型参数而非原始数据,既保证了数据安全,又能实现跨系统协同。”她展示的案例中,某工程机械企业通过这一架构,将分布在全国的30个工厂的设备数据实时同步,大模型训练效率提升40%,故障预测准确率提高至91%。

更实际的案例来自苏州某精密加工企业,该企业为一条价值8000万元的数控机床生产线搭建了数字孪生体,并接入阿里云工业大脑的大模型,2026年1月,系统通过分析机床振动、温度、电流等127个维度的实时数据,提前48小时预测到主轴轴承磨损风险,企业及时更换轴承,避免了可能导致的300万元设备损失和15天停机时间。“以前我们靠经验判断设备状态,现在靠数据说话,心里更有底了。”企业设备部负责人刘伟说。 本月关注智能微网与情绪管理及绿色服务链发展动态,技术创新推动产业升级
从“能用”到“好用”,关键在“数据治理”
尽管“大模型+数字孪生”的方案看似美好,但分享会上多位专家强调:要让数字孪生体真正“好用”,关键不在技术,而在数据治理。“很多企业花大价钱买了数字孪生软件,却连基础的数据采集都做不好。”西门子工业软件中国区技术总监赵明指出,“比如某汽车企业,生产线上的传感器数据采样频率只有1Hz,而大模型需要至少10Hz的数据才能捕捉到设备微小异常,这样的数据喂给大模型,能有什么用?”
赵明的观点得到了数据支撑,白皮书显示,2025年国内工业企业中,仅38%实现了设备数据实时采集,21%的数据采样频率低于5Hz,17%的数据存在缺失或错误,这些问题直接导致数字孪生体的“失真”——某电子制造企业为SMT生产线搭建的孪生体,因未采集贴片机吸嘴压力数据,导致模拟的元件偏移率比实际低40%,优化方案完全无效。

如何解决数据治理问题?腾讯云工业互联网解决方案专家李娜分享了某家电企业的实践:该企业通过部署5G+边缘计算设备,将生产线上的2000多个传感器数据采样频率从1Hz提升至10Hz,并通过区块链技术确保数据不可篡改;企业建立了数据质量评估体系,对缺失值、异常值、重复值进行自动清洗,数据可用率从65%提升至92%。“数据治理不是一次性工程,而是需要持续投入的长期工作。”李娜说,“这家企业每年在数据治理上的投入超200万元,但换来的是数字孪生体预测准确率提升25%,设备故障率下降18%。”
更极端的案例来自深圳某3C产品制造商,该企业为一条价值1.5亿元的手机组装线搭建了数字孪生体,但因未建立数据标准,不同供应商的设备数据格式不统一,导致孪生模型无法整合数据,企业不得不花费3个月时间,联合设备供应商重新定义数据接口,才让孪生体正常运行。“这就像建房子,如果砖块尺寸都不一样,房子肯定建不起来。”企业信息化负责人陈刚比喻道。
人才缺口,比技术更“卡脖子”
2026年健康中国与资源回收及营养膳食热度持续攀升,相关应用不断深化 除了数据治理,人才缺口也是数字孪生体应用的“卡脖子”问题,分享会上,某化工企业信息化总监周敏吐槽:“我们花了半年时间招数字孪生工程师,结果收到的简历要么是只会3D建模的‘画图匠’,要么是只会写代码的‘程序员’,真正懂工业又懂数字技术的复合型人才,一个都没找到。”
周敏的困境在行业内普遍存在,白皮书数据显示,2025年国内工业数字孪生体相关人才缺口超50万,其中既懂工业流程又懂数字技术的复合型人才不足10%,某招聘平台的数据更直观:2026年1月,数字孪生工程师的平均招聘周期长达62天,是传统IT岗位的2.3倍。 不断生态补偿热度持续上升,相关产业迎来新发展
“人才缺口比技术更难解决。”清华大学工业工程系教授刘志强指出,“数字孪生需要跨学科知识,但高校的专业设置还停留在‘工业工程’或‘计算机’的单学科阶段,培养的人才要么懂工业不懂数字,要么懂数字不懂工业。”他建议企业与高校合作,通过“订单式培养”解决人才问题。
一些企业已经开始行动,海尔集团与浙江大学合作开设了“工业数字孪生”联合实验室,学生需在海尔工厂实习6个月,参与真实项目开发;华为与清华大学联合推出了“数字孪生工程师认证”,涵盖工业知识、数据治理、大模型应用等多个维度,已有超3000名工程师通过认证。“我们需要的不是‘证书工程师’,而是能解决实际问题的‘实战派’。”华为云工业互联网解决方案总监张磊说,“比如海尔的联合实验室,学生毕业就能直接上手项目,这种人才最抢