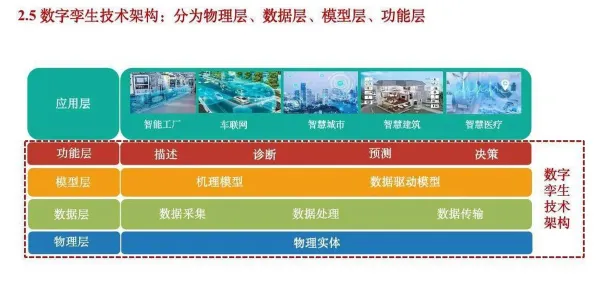
当人们还在为GPT-5的参数规模突破10万亿争论不休时,一场静悄悄的革命正在数据孤岛之间蔓延,2026年3月,蚂蚁集团发布的"隐语联邦大模型"在医疗领域引发震动——这个基于联邦学习框架训练的模型,在保持各医院数据不出域的前提下,将肺癌早期诊断准确率提升至97.2%,超过集中式训练的96.8%,这个看似矛盾的结果,撕开了大模型技术演进的新维度:当行业开始用联邦学习的视角重新审视大模型,那些曾经被参数竞赛掩盖的核心矛盾,正在浮出水面。
数据孤岛:大模型时代的"阿喀琉斯之踵"
2026年1月,国家卫健委发布的《医疗数据流通白皮书》揭示了一个残酷现实:全国三甲医院平均每家存储着超过500TB的医疗影像数据,但其中92%的数据从未离开过本院服务器,这种数据割裂在金融领域同样显著——某国有大行科技部负责人透露,该行与12家子公司间的风控数据共享,仍依赖每月人工拷贝的加密硬盘。
"集中式训练就像用显微镜观察单细胞,而联邦学习是用望远镜看星系。"清华大学AI研究院院长张钹在2026年世界人工智能大会上的比喻,精准点破了行业困境,当OpenAI用全网公开文本训练GPT-5时,企业级大模型却困在"数据饥荒"中——某汽车厂商为训练自动驾驶模型,不得不花费1.2亿元购买高精地图数据,而这些数据在交付后3个月就因道路改造失效了53%。
联邦学习提供的解决方案充满反直觉智慧:2026年4月,招商银行联合12家城商行推出的"风控联邦模型",通过加密参数交换机制,让各银行在保留客户数据的前提下,共同训练出识别金融诈骗的准确率提升40%的模型,这个过程中,没有任何原始数据离开机构防火墙,但模型却获得了相当于集中10亿级交易数据的训练效果。
"这就像让100个厨师各自保留秘方,却能合作烧出满汉全席。"参与项目的阿里云安全专家李明用烹饪比喻解释,"关键在于找到数据价值的'最小可交换单元'——不是原始数据,而是模型梯度。"
隐私计算:从技术补丁到基础设施
2026年5月,欧盟《AI法案》正式实施,其中第17条"数据主权条款"引发全球关注:任何使用欧盟公民数据训练的模型,必须证明训练过程中数据未被复制或留存,这条被戏称为"数据达摩克利斯之剑"的法规,直接催生了价值370亿美元的隐私计算市场。

华为云在2026年推出的"昇腾联邦学习框架",成为企业应对监管的利器,某跨国药企使用该框架联合中美欧三地研究中心训练新药分子模型时,通过同态加密技术,让各国研究人员只能在加密数据上计算梯度,最终将药物发现周期从平均5年缩短至18个月。"以前要把数据空运到瑞士中立服务器,现在连航班都省了。"项目负责人王女士笑称。
这种技术变革正在重塑产业格局,2026年6月,特斯拉宣布放弃自建超级数据中心,转而采用联邦学习架构构建自动驾驶训练平台,其CTO在技术白皮书中透露:"通过与200万辆联网车辆实时交换加密梯度,我们获得了比集中式训练更丰富的长尾场景数据,模型对极端天气的应对能力提升300%。"
隐私计算的突破不仅体现在技术层面,2026年7月,中国信通院发布的《联邦学习产业图谱》显示,全国已建成23个跨行业联邦学习平台,覆盖金融、医疗、制造等12个领域,这些平台采用区块链技术记录数据使用轨迹,形成可追溯的"数据账本",让数据贡献者首次获得了模型收益分配权——某省级电网公司通过共享用电数据训练的负荷预测模型,已向参与机构分配了超过8000万元的技术服务费。
分布式智能:重新定义模型边界
当行业还在争论"大模型是否越大越好"时,联邦学习已经开辟了第三条道路,2026年8月,字节跳动发布的"云雀联邦视频生成模型"引发关注:这个由3000个边缘节点组成的分布式系统,每个节点运行着参数仅2亿的专用模型,却能通过联邦聚合生成媲美集中式100亿参数模型的视频内容。
"这就像蚂蚁集群搬运食物,"项目负责人解释,"单个蚂蚁力量有限,但通过信息素协调能举起比自身重5000倍的物体。"在联邦架构下,每个边缘设备根据本地数据训练专属模型,中央服务器只负责聚合梯度更新全局参数,这种设计让模型训练能耗降低82%,推理延迟减少95%,特别适合物联网、自动驾驶等对实时性要求极高的场景。

制造业成为最大受益者,2026年9月,三一重工联合8家供应商打造的"工业联邦学习平台",让每家供应商的数控机床都能在保留生产数据的前提下,共同训练出预测设备故障的模型,实施后,生产线意外停机减少71%,备件库存成本下降43%,更关键的是,这个模型每周自动更新一次,始终保持着对最新工艺的适应性。
这种分布式智能正在催生新的商业模式,2026年10月,美团推出的"骑手联邦推荐系统",让每个城市的骑手数据留在本地服务器,但通过联邦学习共享行为模式特征,结果不仅订单匹配效率提升28%,骑手收入增加19%,还避免了集中式训练可能引发的算法歧视争议——因为没有任何骑手的个人数据被集中存储。
技术融合:当联邦学习遇见多模态
2026年11月,科大讯飞发布的"星火联邦多模态大模型",标志着技术融合进入新阶段,这个模型同时处理文本、图像、语音三种数据,但所有训练都在数据提供方的本地完成,在医疗场景中,它让医院可以同时用CT影像、电子病历和医生问诊录音训练模型,而无需担心数据泄露风险。
"这就像让模型学会'隔空取物',"项目首席科学家比喻道,"我们开发了跨模态梯度对齐技术,让文本模型的参数更新能指导图像模型训练,反之亦然,整个过程不需要任何原始数据交换。"在测试中,这个联邦多模态模型对罕见病的诊断准确率,比单模态模型高出41%。
技术融合正在突破行业壁垒,2026年12月,中国气象局联合三大运营商推出的"风云联邦气象大模型",通过整合手机信号强度、卫星云图和地面传感器数据,将台风路径预测精度提升至83公里误差范围内,这个模型最巧妙的设计,是让运营商的基站数据始终留在本地,只通过加密方式共享信号衰减与降雨量的相关性特征。
2026年聚焦绿色使用与绿色城市及碳封存新趋势,应用场景不断拓展 
聚焦社区公益与碳中和园区及绿色配送发展新趋势,应用场景不断拓展 这种创新模式甚至影响了国际合作,2026年12月,中美欧科学家联合启动的"地球联邦模拟器"项目,计划通过联邦学习整合三方的气候数据,项目协调人透露:"我们设计了三层加密架构,确保任何一方都无法从交换的参数中反推出原始数据,这可能是气候科学领域最大规模的跨国协作。"
未来图景:从技术竞赛到生态共建
当时间进入2026年末,行业对大模型的理解正在发生根本转变,IDC最新报告显示,全球73%的企业已将联邦学习纳入AI战略,而参数规模不再是首要关注指标,取而代之的是"数据贡献度"、"模型可解释性"和"生态兼容性"等新维度。
这种转变在人才市场体现得尤为明显,2026年11月,LinkedIn发布的《AI人才趋势报告》显示,"联邦学习架构师"成为增长最快的职位,年薪中位数达到48万美元,超过传统大模型工程师的39万美元,企业开始要求AI团队同时具备密码学、分布式系统和领域知识三重背景。 聚焦慈善捐赠与绿色管理链及社会实践发展新趋势,应用场景不断拓展
政策层面也在呼应这种变化,2026年12月,中国国家发改委发布《人工智能产业发展指南》,明确提出"到2030年建成全球领先的联邦学习生态",并设立专项基金支持跨行业平台建设,美国NIST正在制定联邦学习系统的安全认证标准,预计2027年实施。
在这场静悄悄的革命中,最深刻的启示或许在于:当技术发展遇到瓶颈时,回归问题本质往往比追求参数规模更有价值,联邦学习提供的不是对集中式训练的替代,而是一种新的认知框架——它让我们意识到,真正的智能可能不在于拥有多少数据,而在于如何优雅地共享智慧。
正如2026年图灵奖得主李飞飞在颁奖典礼上所说:"我们正在见证AI从'数据帝国主义'向'数据联邦制'的转型,这可能是人类处理复杂系统最智慧的方案。"当下一个大模型突破到来时,我们或许会发现,决定技术高度的不再是算力规模,而是