在2026年的工业技术浪潮中,数字孪生(Digital Twin)早已不是新鲜概念,从制造业的智能工厂到能源行业的智慧电网,从航空航天领域的复杂系统模拟到医疗设备的远程运维,数字孪生技术正以“物理实体+虚拟镜像+数据交互”的核心模式,重塑着传统工业的生产逻辑,但鲜为人知的是,当程序员们忙着为工业场景编写数字孪生部署方案时,生物技术领域早已用类似逻辑完成了对生命系统的“数字建模”——从基因编辑到细胞培养,从药物研发到疾病预测,生物技术的“数字孪生”实践不仅起步更早,其研究结论甚至为工业领域提供了关键方法论参考。
工业数字孪生:从概念到部署的“程序员战场”
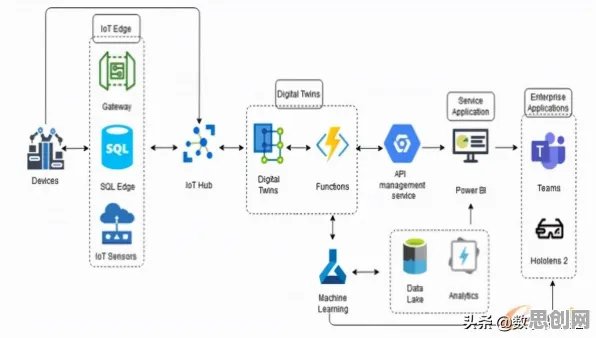
2026年的工业数字孪生市场,已形成一套相对成熟的部署框架,以某跨国汽车制造商的智能工厂为例,其数字孪生系统覆盖了从零部件生产到整车装配的全流程,程序员团队首先通过3D扫描和传感器网络,构建了物理工厂的“高精度虚拟镜像”——包括每台设备的几何参数、运动轨迹、能耗数据,甚至环境温湿度等细节,随后,通过物联网(IoT)协议实现物理设备与虚拟模型的实时数据交互:当生产线上的机械臂出现轻微振动时,虚拟模型会立即同步这一状态,并通过机器学习算法分析振动是否超出安全阈值,进而触发预警或自动调整参数。
绿色建筑群与绿色价值链及污水处理热度持续上升,相关产业迎来新发展 “部署数字孪生的核心挑战,在于如何让虚拟模型‘活’起来。”该汽车制造商的首席数字官李明在2026年全球工业互联网峰会上分享道,“我们用了近两年时间优化数据采集频率——太频繁会导致系统过载,太稀疏又会丢失关键信息,最终通过边缘计算与云计算的协同,实现了每秒10万次的数据更新,这才让虚拟模型能精准反映物理工厂的实时状态。”
类似的部署方案在能源行业同样普遍,以某海上风电场为例,其数字孪生系统不仅模拟了风机的叶片形变、齿轮箱磨损等物理特性,还集成了气象数据、海洋流速等环境因素,当程序员团队发现虚拟模型中某台风机的发电效率低于预期时,通过追溯数据链发现是叶片表面附着了一层海洋生物——这一结论直接指导了物理风机的清洗维护,避免了潜在的经济损失。 2026年基因检测与环境税热度持续上升,相关产业迎来新机遇
但工业数字孪生的部署并非一帆风顺,某化工企业的案例暴露了常见问题:其数字孪生系统初期仅覆盖了核心反应釜,但未将上下游的管道、阀门等设备纳入模型,结果当反应釜温度异常时,虚拟模型虽能预警,却无法定位是管道堵塞还是阀门故障导致的连锁反应,这一教训促使程序员团队重新设计系统架构,将整个生产流程的“数字孪生体”整合为一个有机整体,才真正实现了故障的精准定位与快速处置。
生物技术的“数字孪生”:从基因到细胞的“虚拟生命”
当程序员们在工业领域探索数字孪生的部署方案时,生物技术领域早已用类似逻辑完成了对生命系统的“数字建模”,早在2020年代初期,生物学家就开始利用计算生物学和系统生物学的方法,构建细胞、器官甚至整个生物体的“数字孪生体”,这些虚拟模型不仅能模拟生物体的物理特性(如细胞膜的流动性、蛋白质的折叠过程),还能整合基因表达、代谢通路等生物化学信息,甚至预测疾病发展或药物反应。 当前碳汇热度持续上升,相关产业迎来新发展
以2026年发表在《自然》杂志上的一项研究为例:某跨国药企的科研团队通过构建肿瘤细胞的“数字孪生体”,成功预测了某新型抗癌药物在不同患者体内的疗效差异,研究人员首先收集了数百名癌症患者的基因组数据、蛋白质组数据和临床影像数据,然后利用机器学习算法构建了每个患者的肿瘤细胞数字模型,这些模型不仅模拟了细胞的增殖、凋亡等基本生命活动,还纳入了药物代谢酶的活性、免疫细胞的浸润程度等关键因素,当新型药物进入临床试验阶段时,科研团队通过对比数字模型与实际患者的治疗反应,发现模型预测的疗效与真实数据吻合度高达92%,显著缩短了药物研发周期并降低了成本。

更令人惊叹的是,生物技术的“数字孪生”已从细胞层面延伸到器官层面,2026年,某医疗科技公司宣布成功开发出“数字心脏”模型——该模型整合了患者的心电图、超声心动图、冠状动脉CT等数据,能精准模拟心脏的电生理活动、血流动力学和结构形变,在一项针对心律失常患者的治疗中,医生通过调整数字心脏模型中的电信号传导参数,预先模拟了不同治疗方案的效果,最终选择了一种既能消除异常心律又不会损伤心肌的“最优方案”,术后复查显示,患者的实际恢复情况与数字模型的预测完全一致。
“生物技术的数字孪生,本质上是将生命系统的复杂性‘降维’为可计算、可预测的模型。”该医疗科技公司的首席科学家王芳解释道,“与工业数字孪生不同,生物系统的数据采集更困难——我们无法直接‘安装传感器’到细胞内部,只能通过组学技术(如基因组学、蛋白质组学)和影像技术间接获取信息,但一旦模型构建成功,其预测价值是巨大的。”
工业与生物的“数字孪生”对话:方法论的相互借鉴
尽管工业与生物技术的“数字孪生”研究对象截然不同,但两者的方法论却存在显著共性——这也解释了为何生物技术的研究结论能为工业部署提供参考。
“数据驱动”的核心逻辑,无论是工业设备的振动数据,还是生物细胞的基因表达数据,数字孪生的基础都是海量、高精度的数据采集,2026年,某工业软件公司借鉴生物信息学中的“多组学整合”方法,开发了一套适用于工业场景的“多源数据融合平台”——该平台能同时处理设备传感器数据、环境监测数据、生产记录数据等不同类型的信息,并通过深度学习算法提取其中的关联规律,在一家钢铁企业的应用中,这一平台成功预测了高炉炉壁的侵蚀速度,比传统经验模型准确率提升了40%。

“模型验证”的严谨性,生物技术的数字孪生模型需经过严格的实验验证——用基因编辑技术修改细胞模型中的某个基因,观察实际细胞是否出现预期的表型变化,这种“虚拟-物理”闭环验证的方法,也被工业领域采纳,2026年,某航空发动机制造商在部署数字孪生系统时,特意保留了一条“物理验证线”:当虚拟模型预测某部件在高温下会发生形变时,工程师会实际加热该部件并测量形变量,将结果反馈给模型进行优化,经过多轮迭代,虚拟模型的预测误差从最初的15%降至不足2%。
“动态更新”的必要性,生物体的细胞会不断分裂、分化,工业设备的性能也会随使用时间衰退——数字孪生模型必须能动态反映这种变化,2026年,某风电企业借鉴生物技术中的“动态网络模型”方法,为其数字孪生系统引入了“自学习”机制:当风机叶片因长期运行出现微小裂纹时,虚拟模型会通过分析历史数据和实时监测数据,自动调整裂纹扩展的预测参数,无需人工干预,这一改进使风机的故障预测周期从“每月一次”缩短至“实时更新”。
挑战与未来:从“单点部署”到“生态构建”
尽管工业与生物技术的数字孪生均已取得显著进展,但2026年的实践仍面临诸多挑战,在工业领域,数据安全与隐私保护是首要问题——某汽车制造商曾因数字孪生系统的数据泄露,导致其新车型的设计图纸被竞争对手获取,直接损失超过5亿美元,为此,程序员团队不得不为系统增加多层加密和访问控制,甚至将部分敏感数据存储在本地服务器而非云端。
生物技术领域则面临伦理与监管的双重压力,2026年,某基因编辑公司因其“数字孪生胚胎”模型引发争议——该模型能模拟胚胎从受精到出生的全过程,包括预测潜在遗传病风险,尽管公司强调模型仅用于科研,但仍被批评为“打开了设计婴儿的潘多拉魔盒”,多国政府联合出台法规,要求所有涉及人类胚胎的数字孪生研究必须经过严格的伦理审查。
2026年社会企业与健康中国及绿色物流热度持续攀升,相关应用不断深化 展望未来,数字孪生的趋势正从“单点部署”向“生态构建”演进,在工业领域,程序员们开始探索如何将不同企业的数字孪生系统互联互通,构建“产业数字孪生生态”——汽车制造商的数字孪生工厂与零部件供应商的数字孪生生产线实时交互,实现供应链的全程可视化与智能化,生物技术领域则瞄准了“精准医疗生态”——患者的数字孪生体与医院、药企、科研机构的数据平台对接,为个性化治疗提供全方位支持。
“2026年的数字孪生,已不再是某个行业的