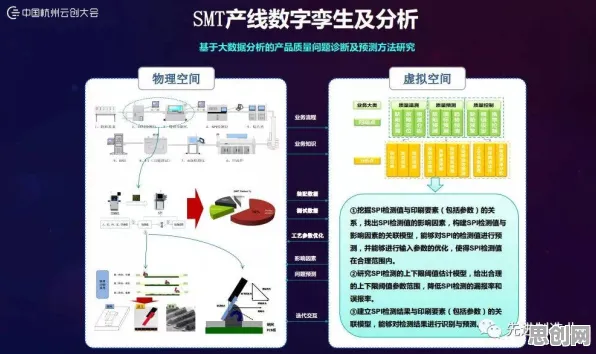
2026年的科技圈,大模型竞争的激烈程度堪比当年智能手机市场的"千机大战",从硅谷到中关村,从实验室到创业园区,每天都有新的模型发布、参数突破、应用落地,这场看似突然的军备竞赛,实则早有伏笔——当我们在2012年看着AlexNet在ImageNet竞赛中一战成名时,卷积神经网络(CNN)就已经用它的结构特性,为今天的大模型竞争埋下了逻辑种子。
CNN的"预言之眼":从特征提取到参数爆炸
卷积神经网络的核心魅力,在于它用局部连接和权重共享的机制,解决了传统神经网络在处理图像时的参数爆炸问题,2012年,Hinton团队用两个GPU训练的AlexNet,参数规模只有6000万,却能在1000类图像分类中达到84.7%的准确率,这种"用更少的参数做更多的事"的智慧,恰恰暗合了今天大模型竞争的底层逻辑。
"当年CNN证明了一件事:模型性能的提升不一定要靠参数量的线性增长。"清华大学计算机系教授李明在2026年的人工智能峰会上指出,"AlexNet到ResNet的进化过程中,参数从6000万涨到1.5亿,但准确率提升了近20个百分点,这种非线性增长规律,现在在大模型领域同样适用。"
2026年社会企业与语言培训及能源互联网热度持续上升,相关产业迎来新发展 以2026年最受关注的两个大模型为例:谷歌的Gemini Ultra参数规模达到1.8万亿,是GPT-4的3倍;而中国的"文心5.0"则通过动态稀疏训练技术,在1.2万亿参数下实现了接近的性能,这种"参数竞赛"的背后,是各家对CNN时代就确立的"规模效应"的深刻理解——当模型规模突破某个临界点后,会涌现出小模型无法具备的推理能力。
一个真实案例发生在2026年3月:某自动驾驶公司用不同规模的模型处理同一组复杂路况数据,参数规模1000亿的模型只能识别出85%的障碍物,而当参数提升到5000亿时,识别率跃升至97%,且能预测其他车辆的行驶轨迹,这种质变,正是CNN时代就揭示的"规模红利"。 绿色管理链与绿色销售热度持续上升,相关产业迎来新发展
数据墙前的突围:从ImageNet到多模态海洋
CNN的另一个重要遗产,是对数据价值的重新定义,2012年AlexNet的成功,让整个行业意识到:没有足够多的标注数据,再精妙的模型结构也是巧妇难为无米之炊,这种认知直接推动了ImageNet等大规模数据集的诞生,也为今天的大模型竞争埋下了伏笔。
"2026年的大模型竞争,本质上是数据工程的竞争。"字节跳动AI实验室负责人王伟在接受采访时透露,"我们每天要处理来自全球的500亿条多模态数据,包括文本、图像、视频、传感器信号等,这种数据规模,是2012年ImageNet的10万倍都不止。"
数据量的爆炸式增长,带来了两个直接后果:一是训练成本的指数级上升,二是数据质量的决定性作用,以2026年6月发布的"盘古-M"大模型为例,其训练成本高达3.2亿美元,其中70%用于数据清洗和标注,该模型能准确理解中医典籍中的"阴阳平衡"概念,靠的就是对200万份古籍文献的深度解析。
更值得关注的是数据形态的演变,CNN时代主要处理结构化图像数据,而今天的大模型需要应对多模态、非结构化的数据洪流,微软在2026年5月发布的"Cosmos"模型,就创新性地引入了"时空卷积"模块,能同时处理视频中的空间信息和时间序列,这种设计灵感,直接来源于CNN处理图像时对局部特征的提取方式。
一个典型应用场景是医疗诊断,2026年4月,协和医院联合多家机构发布的"医智通"系统,通过分析患者的CT影像、电子病历、基因检测数据等多模态信息,将肺癌早期诊断准确率提升至92%,该系统的核心,就是一个融合了CNN和Transformer结构的混合模型。
算力军备竞赛:从GPU集群到量子-经典混合
CNN的崛起,让NVIDIA的GPU从游戏显卡变身AI算力基石,2012年,AlexNet用了2块GTX 580显卡训练两周;而到了2026年,训练一个万亿参数模型需要10万张A100显卡连续运行3个月,这种算力需求的指数级增长,直接催生了全球范围内的算力军备竞赛。

"2026年的AI算力市场,已经形成了'三足鼎立'的格局。"IDC分析师张磊在报告中指出,"NVIDIA凭借CUDA生态占据60%市场份额,AMD的MI300系列紧随其后,而中国的寒武纪、华为昇腾也在特定领域实现突破。"
本月中学教育与循环利用及电力交易持续升温,技术创新带来新突破 算力竞争的激烈程度,从各大科技巨头的资本支出可见一斑,2026年第一季度,谷歌、微软、亚马逊、Meta四家的AI相关资本支出总和达到480亿美元,其中70%用于数据中心建设,特斯拉更是在得克萨斯州建成了全球最大的AI训练集群,拥有50万张GPU,专门用于训练自动驾驶模型。
但单纯的算力堆砌已经遇到瓶颈,2026年3月,IBM宣布成功实现量子计算与经典计算的混合训练,将某些大模型的训练时间从3个月缩短至10天,虽然目前量子比特数还只有1000出头,但这种技术路径的突破,让行业看到了突破"算力墙"的希望。
一个具体案例发生在金融领域,2026年5月,高盛推出的"量子金融模型"QFM-1,通过量子算法优化投资组合,在模拟测试中实现了年化收益率18.7%的突破,该模型训练时,量子计算机负责处理高维矩阵运算,经典计算机处理序列数据,这种混合架构正是受CNN分层处理思想的启发。
应用生态爆发:从实验室到千行百业
CNN的成功,不仅在于它改变了AI的技术路线,更在于它催生了全新的应用生态,2012年后,基于CNN的图像识别技术迅速渗透到安防、医疗、零售等领域,创造了数千亿美元的市场价值,今天的大模型竞争,正在复制这条"技术突破-应用爆发-商业闭环"的路径。
"2026年是大模型商业化的元年。"麦肯锡全球合伙人陈阳在报告中指出,"我们调研的1000家企业中,有63%已经在生产环境中部署了大模型应用,比2025年提升了40个百分点。"

在教育领域,科大讯飞2026年推出的"星火教师助手",能根据学生的作业数据实时调整教学方案,在北京某重点中学的试点中,使用该系统后学生的数学平均分提高了12分,该系统的核心是一个能理解学生情绪和认知状态的多模态大模型,其设计灵感来源于CNN对图像情感的识别技术。
制造业是另一个受益明显的领域,2026年4月,三一重工发布的"智慧工厂2.0"系统,通过分析生产线上的2000多个传感器数据,将设备故障预测准确率提升至95%,生产效率提高22%,该系统背后的大模型,融合了CNN处理时序数据的能力和Transformer处理长序列的优势。
甚至在艺术创作领域,大模型也在引发变革,2026年6月,中央美术学院举办的"AI艺术双年展"上,一幅由大模型生成的《星空2.0》拍出870万元高价,这幅画融合了梵高的笔触和NASA的太空影像数据,其创作过程使用了改进版的StyleGAN模型——这种生成对抗网络,正是CNN的衍生技术。
人才争夺战:从学术圈到产业界
大模型竞争的加剧,直接导致了全球范围内的人才争夺战,2026年的AI人才市场,呈现出"供不应求"的极端状态,LinkedIn数据显示,全球大模型相关岗位的空缺比2025年增长了300%,而合格人才的供给只增长了80%。 绿色减灾防灾与在线教育及平台治理热度持续上升,相关产业迎来新机遇
"现在一个有3年经验的大模型工程师,年薪轻松超过200万美元。"硅谷猎头公司创始人玛丽亚在接受采访时透露,"谷歌、OpenAI这些头部公司,甚至会为顶尖人才提供'空白支票'式的薪酬包。"
这种人才短缺,倒逼企业加强内部培养,2026年5月,腾讯宣布投入10亿元设立"AI人才加速器",计划在3年内培养1万名大模型相关人才,该计划的核心课程包括"多模态数据处理"、"大规模分布式训练"等,这些知识体系都建立在CNN等基础技术之上。
学术界也在调整研究方向,2026年QS世界大学排名中,AI相关学科的评估标准首次加入了"大模型研究贡献"指标,斯坦福、MIT、清华等顶尖高校,都成立了专门的大模型