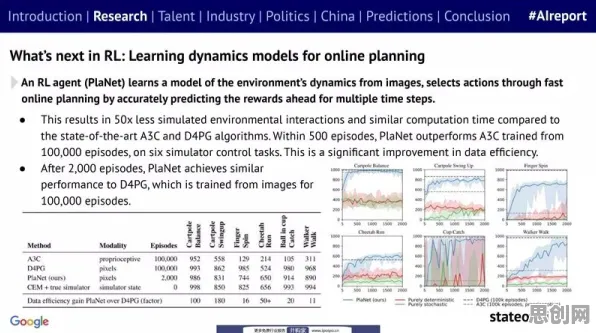
数据采集:从“物理世界”到“数字镜像”的第一步
工业数字孪生的基础是构建一个与物理实体完全对应的虚拟模型,而这一过程的第一步就是数据采集,2026年,随着物联网(IoT)技术的成熟,工业设备的数据采集已不再局限于简单的温度、压力等基础参数,而是延伸至设备振动、声音、图像甚至工艺流程中的化学成分变化等多维度数据。
以某新能源汽车电池生产线为例,该企业在2026年引入了数字孪生技术,旨在优化电池生产过程中的良品率,其数据采集系统覆盖了从原材料投料到成品包装的全流程:在涂布环节,通过高精度传感器实时采集涂布厚度、均匀度等数据;在卷绕环节,激光传感器监测极片对齐度;在化成环节,电压、电流、温度等参数被以毫秒级频率记录,更关键的是,该企业还部署了边缘计算设备,在数据产生源头进行初步处理,过滤掉无效数据,仅将关键特征值上传至云端,既降低了传输压力,又提高了数据质量。
这一案例的典型性在于,它展示了工业数据采集的“全面性”与“精准性”缺一不可,如果仅采集部分关键参数,数字孪生模型将无法完整反映物理实体的状态;而如果数据精度不足,模型预测的结果也会大打折扣,据该企业技术负责人透露,其数据采集系统的误差率控制在0.1%以内,为后续分析提供了可靠基础。
数据清洗:从“海量数据”到“可用数据”的筛选过程
采集到的原始数据往往存在噪声、缺失值、异常值等问题,直接用于建模会导致结果偏差,数据清洗是大数据分析逻辑链条中至关重要的一环,在2026年的工业场景中,数据清洗已不再依赖人工,而是通过机器学习算法实现自动化处理。
仍以上述电池生产企业为例,其数据清洗流程包括三个步骤:通过时序分析算法识别并剔除传感器故障导致的异常数据点;利用插值算法填补因网络中断或设备维护导致的缺失值;通过聚类分析将相似工况下的数据归为一类,为后续建模提供标准化输入,在涂布环节,系统发现某段时间内涂布厚度数据突然波动,经分析确认是传感器被意外碰撞导致,系统自动剔除了这段异常数据,并用前后正常数据的平均值进行填补。

绿色回收与养生保健热度持续上升,相关产业迎来新机遇 这一过程的关键在于“自动化”与“可解释性”的平衡,自动化清洗提高了效率,但必须确保算法的决策逻辑可追溯,否则一旦出现错误,工程师将难以排查问题,该企业通过引入可解释AI(XAI)技术,为每个清洗步骤生成详细的日志报告,工程师可以随时回溯数据处理的每一步,确保清洗后的数据质量,据统计,经过清洗的数据,其可用率从原始的70%提升至95%以上,为后续建模提供了坚实保障。
特征工程:从“原始数据”到“关键特征”的提炼过程
智慧城市与美妆护肤及碳封存热度持续上升,相关产业迎来新发展 数据清洗后,下一步是特征工程——即从海量数据中提取对建模最有价值的特征,在工业场景中,特征工程往往需要结合领域知识,而非单纯依赖算法,2026年,随着工业知识图谱的普及,特征工程已从“人工经验驱动”转向“知识+算法协同驱动”。
绿色防洪抗旱与虚拟电厂热度持续攀升,相关应用不断深化 以某航空发动机制造企业为例,其在2026年部署了数字孪生系统,用于预测发动机叶片的疲劳寿命,该企业的特征工程过程充分体现了领域知识的重要性:工程师根据材料力学原理,确定影响叶片寿命的关键参数,如应力、温度、振动频率等;通过相关性分析,筛选出与疲劳寿命高度相关的特征组合;利用主成分分析(PCA)降维,将数十个原始特征压缩为3-5个关键特征,既减少了计算量,又提高了模型准确性。
这一案例的亮点在于“知识引导”与“数据驱动”的结合,如果仅依赖算法自动提取特征,可能会忽略一些对物理过程至关重要的参数;而如果完全依赖人工经验,又可能遗漏数据中隐藏的复杂关系,该企业通过构建发动机材料-工艺-性能的知识图谱,为特征工程提供了结构化指导,使提取的特征既符合物理规律,又能充分反映数据中的模式,据测试,基于这些特征构建的寿命预测模型,其准确率比传统方法提升了20%以上。

建模与仿真:从“数字镜像”到“预测决策”的核心环节
特征工程完成后,下一步是构建数字孪生模型并进行仿真分析,在2026年,工业数字孪生模型已从单一的物理模型发展为“物理+数据+知识”的混合模型,能够更准确地模拟复杂工业过程。
以某半导体制造企业为例,其在2026年引入了数字孪生技术,用于优化光刻机的工艺参数,该企业的建模过程分为三个层次:基于第一性原理构建光刻机的物理模型,模拟光刻胶的曝光、显影等化学过程;利用历史生产数据训练数据驱动模型,捕捉物理模型难以描述的复杂非线性关系;将领域知识(如材料特性、设备限制)嵌入模型,形成混合模型,在仿真阶段,系统通过蒙特卡洛模拟,对不同工艺参数组合下的成品率进行预测,并生成最优参数建议。
这一案例的典型性在于,它展示了混合模型的优势,纯物理模型虽然理论严谨,但往往无法描述实际生产中的所有变量;纯数据驱动模型虽然灵活,但可能缺乏物理可解释性,而混合模型结合了两者的优点,既能基于物理规律进行可靠预测,又能通过数据学习适应实际工况的变化,据该企业统计,应用数字孪生技术后,光刻机的成品率从85%提升至92%,每年节省成本超千万元。
闭环优化:从“单次建模”到“持续迭代”的进化过程
工业数字孪生的价值不仅在于单次建模与仿真,更在于通过实时数据反馈实现模型的持续优化,形成“建模-仿真-优化-再建模”的闭环,在2026年,随着数字孪生与工业互联网的深度融合,这一闭环已实现自动化运行。

以某钢铁企业的高炉炼铁过程为例,其在2026年部署了数字孪生系统,用于优化高炉操作参数,该系统的闭环优化流程如下:基于历史数据构建初始模型,预测不同风量、料速等参数下的铁水温度与硅含量;在实际生产中,系统实时采集高炉运行数据,并与模型预测结果对比;如果偏差超过阈值,系统自动调整模型参数,并通过强化学习算法生成新的操作建议;新的操作数据又被反馈至模型,形成持续迭代。
这一案例的关键在于“实时性”与“自适应性”,传统的高炉控制依赖人工经验,调整周期长且容易滞后;而数字孪生系统通过实时数据反馈,能够在分钟级时间内完成模型更新与参数调整,据该企业统计,应用闭环优化后,高炉的燃料比降低了3%,铁水质量波动减少了15%,年增效益超5000万元。
安全与隐私:工业大数据分析的“隐形防线”
在工业数字孪生的应用中,数据安全与隐私保护是容易被忽视却至关重要的环节,2026年,随着工业数据价值的提升,黑客攻击、数据泄露等风险也日益严峻,在大数据分析逻辑链条中,必须嵌入安全与隐私保护机制。
以某能源企业为例,其在2026年部署了覆盖全国的输油管道数字孪生系统,用于监测管道泄漏与腐蚀情况,该系统的安全设计包括三个层面:在数据采集层,所有传感器数据通过加密通道传输,防止中间人攻击;在数据处理层,采用联邦学习技术,各站点数据在本地训练模型,仅上传模型参数而非原始数据,避免数据集中泄露;在模型应用层,通过区块链技术记录所有操作日志,确保任何异常访问都可追溯。 2026年可持续商业与绿色消费热度持续上升,相关产业迎来新发展
这一案例的典型性在于,它展示了工业数据安全需要“分层防御”,从数据产生到应用的全流程中,任何环节的疏忽都可能导致安全漏洞,该企业通过“加密传输+联邦学习+区块链审计”的组合方案,构建了多层次的安全防线,确保了数字孪生系统的可靠运行,据其安全团队统计,自系统上线以来,未发生任何数据泄露或模型篡改事件。