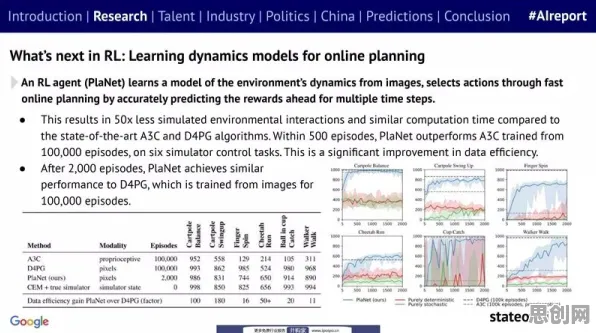
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它正以惊人的速度重塑着传统制造业的生产模式,从德国的智能工厂到中国的“灯塔工厂”,从航空航天到汽车制造,数字孪生技术如同工业领域的“智慧大脑”,让物理世界与虚拟世界深度交融,但当我们深入观察这些成功案例时,会发现一个有趣的现象:同样是应用数字孪生技术,不同企业的实施效果却大相径庭,有的企业借此实现了生产效率的飞跃式提升,而有的企业却陷入了“数据孤岛”和“模型失效”的困境,这背后的成因,与自适应系统的特性密切相关。
数字孪生:工业领域的“智慧镜像”
数字孪生技术的核心,在于通过物理实体与虚拟模型的实时交互,实现对生产过程的精准模拟和优化,它就像一面“智慧镜子”,能够实时反映物理设备的运行状态、生产流程的效率瓶颈,甚至预测未来的故障风险,在2026年的工业实践中,这种技术已经被广泛应用于产品设计、生产制造、设备维护等多个环节。
以德国西门子的安贝格电子制造工厂为例,这座被誉为“全球最智能的工厂”早在2016年就开始布局数字孪生技术,到了2026年,其生产线上的每一台设备、每一个工件都拥有对应的数字孪生体,通过这些虚拟模型,工程师可以实时监控生产线的运行状态,调整工艺参数,甚至在虚拟环境中模拟新产品的生产过程,从而大幅缩短研发周期,降低试错成本,据西门子官方公布的数据,安贝格工厂通过数字孪生技术,将生产效率提升了30%,产品缺陷率降低了50%。
并非所有企业都能像西门子那样成功应用数字孪生技术,在中国南方某汽车制造企业,2026年也投入巨资建设了数字孪生平台,但实施效果却不尽如人意,该企业的生产线虽然实现了部分设备的数字化建模,但由于缺乏统一的系统架构和数据标准,不同部门之间的数据无法共享,导致数字孪生模型成为“孤岛”,无法发挥整体优化作用,更糟糕的是,由于模型更新不及时,部分虚拟模型与物理设备的实际状态严重脱节,反而影响了生产决策的准确性。
自适应系统:数字孪生的“灵魂”
为什么同样是应用数字孪生技术,不同企业的实施效果会如此不同?从自适应系统的角度来看,关键在于数字孪生系统是否具备“自适应”能力,自适应系统是指能够根据外部环境的变化和内部状态的变化,自动调整自身结构和行为,以保持系统稳定性和优化性能的系统,在数字孪生领域,自适应能力意味着虚拟模型能够实时感知物理设备的变化,自动更新模型参数,甚至预测未来的运行趋势。
以美国通用电气(GE)的航空发动机数字孪生项目为例,2026年,GE已经为全球数万架飞机上的发动机建立了数字孪生体,这些虚拟模型不仅能够实时反映发动机的运行状态,还能通过机器学习算法分析历史数据,预测发动机的剩余寿命和潜在故障风险,更重要的是,GE的数字孪生系统具备强大的自适应能力,当发动机的某个部件出现磨损或故障时,虚拟模型能够自动调整相关参数,模拟不同维修方案的效果,为工程师提供最优的维修建议,这种自适应能力使得GE的航空发动机维修周期缩短了20%,维修成本降低了15%。
相比之下,前文提到的中国南方某汽车制造企业的数字孪生系统则缺乏这种自适应能力,该企业的数字孪生模型主要依赖于人工输入的数据和预设的规则,无法自动感知物理设备的变化,当生产线上的设备出现故障或工艺参数发生变化时,虚拟模型无法及时更新,导致模型与实际状态脱节,由于缺乏机器学习算法的支持,该企业的数字孪生系统也无法预测未来的运行趋势,只能提供事后的数据分析,无法为生产决策提供前瞻性指导。
数据驱动:自适应系统的“血液”
自适应系统的运行离不开数据的支持,在数字孪生领域,数据是连接物理世界与虚拟世界的桥梁,也是驱动虚拟模型自适应更新的“血液”,高质量的数据能够确保虚拟模型的准确性和实时性,而低质量的数据则会导致模型失效,甚至误导生产决策。

以中国某钢铁企业的数字孪生项目为例,2026年,该企业投入大量资源建设了数字孪生平台,旨在通过虚拟模型优化高炉炼铁过程,由于数据采集设备老化、数据传输延迟等问题,该企业收集到的数据质量参差不齐,部分数据存在缺失、错误或重复的情况,导致虚拟模型无法准确反映高炉的实际运行状态,更糟糕的是,由于缺乏数据清洗和预处理机制,这些低质量的数据直接被用于模型训练,导致模型性能下降,甚至出现了“过拟合”现象,该企业的数字孪生项目未能达到预期效果,反而增加了生产成本。
相比之下,德国宝马集团的数字孪生项目则非常注重数据质量,2026年,宝马集团在其位于沈阳的工厂中部署了先进的物联网传感器和边缘计算设备,实现了对生产线的实时数据采集和传输,宝马还建立了严格的数据治理体系,对采集到的数据进行清洗、预处理和标注,确保数据的质量和可用性,这些高质量的数据被用于训练数字孪生模型,使得虚拟模型能够准确反映生产线的实际运行状态,并为生产优化提供有力支持,据宝马官方公布的数据,沈阳工厂通过数字孪生技术,将生产效率提升了25%,产品合格率提高了10%。
算法创新:自适应系统的“大脑”
除了数据之外,算法也是驱动自适应系统运行的关键因素,在数字孪生领域,先进的算法能够使得虚拟模型具备更强的自适应能力和预测能力,从而更好地服务于生产优化和决策支持。
本月居家养老与绿色减灾防灾热度持续上升,相关领域迎来新机遇 以中国某风电企业的数字孪生项目为例,2026年,该企业面临风电场运维成本高、故障预测不准确等问题,为了解决这些问题,该企业与高校合作研发了基于深度学习的数字孪生算法,这种算法能够自动分析风电设备的运行数据,识别设备的异常模式,并预测未来的故障风险,更重要的是,该算法还具备自适应能力,能够根据设备的实际运行状态自动调整模型参数,提高预测的准确性,通过应用这种先进的算法,该企业的风电场运维成本降低了20%,故障预测准确率提高了30%。
 2026年心理健康与绿色标签热度持续上升,相关产业迎来新发展
2026年心理健康与绿色标签热度持续上升,相关产业迎来新发展
算法创新并非一蹴而就,在中国南方某电子制造企业的数字孪生项目中,由于缺乏算法研发能力,该企业只能采用传统的统计方法进行数据分析,这些方法虽然简单易行,但无法处理复杂的数据关系,也无法实现模型的自适应更新,该企业的数字孪生系统只能提供有限的数据分析功能,无法为生产优化提供有力支持。 体育教育与绿色物流持续升温,技术创新带来新突破
人才支撑:自适应系统的“基石”
无论是数据驱动还是算法创新,都离不开高素质人才的支撑,在数字孪生领域,既懂工业生产又懂信息技术的复合型人才是推动技术实施和优化的关键力量。
以中国某智能制造研究院为例,2026年,该研究院汇聚了一批来自工业、信息技术、数学等多个领域的专家,形成了跨学科的研究团队,这些专家不仅具备深厚的理论知识,还拥有丰富的实践经验,能够针对企业的实际需求开发定制化的数字孪生解决方案,该研究院还与高校合作开展人才培养项目,为工业领域输送了大量高素质的数字孪生人才,这些人才在企业的数字孪生项目中发挥了重要作用,推动了技术的落地和应用。
相比之下,一些企业在实施数字孪生项目时,由于缺乏专业人才的支持,往往陷入“技术瓶颈”和“实施困境”,这些企业要么无法开发出符合实际需求的数字孪生模型,要么无法将模型与生产系统有效集成,导致项目失败或效果不佳。
自适应系统引领数字孪生未来
从自适应系统的角度来看,工业数字孪生技术的实施效果取决于系统的自适应能力、数据质量、算法创新和人才支撑等多个因素,只有具备强大的自适应能力、高质量的数据、先进的算法和高素质的人才,才能构建出真正有效的数字孪生系统,为工业生产带来革命性的变化。
在2026年的工业领域,数字孪生技术已经成为推动制造业转型升级的重要力量,随着自适应系统理论的不断完善和技术的不断进步,我们有理由相信,数字孪生技术将在未来发挥更加重要的作用,引领工业生产迈向更加智能、高效和可持续的未来。