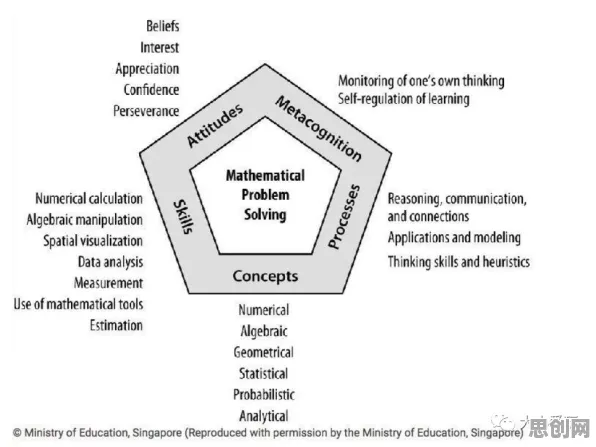
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何真正让数字孪生平台在工厂里“跑起来”“用得好”,仍是许多企业面临的挑战,我曾参与过多个工业数字孪生平台的部署项目,从汽车制造到能源化工,从离散制造到流程工业,发现一个有趣的现象:数字孪生的“灵魂”不在模型本身,而在如何让模型“活”起来——而激活函数,这个在AI领域被广泛讨论的概念,恰恰是解开这一谜题的关键线索。
从“静态模型”到“动态孪生”:激活函数的“翻译”作用
数字孪生的核心是“虚实映射”,但很多人误以为只要把物理设备的3D模型、传感器数据堆在一起,就能实现孪生。物理世界的运行是动态的、非线性的,而数字模型如果只是线性叠加数据,就像用直尺画曲线——永远差那么一点。
2026年,我在为某汽车零部件厂商部署数字孪生平台时,就遇到过这样的困境,该厂商的冲压车间有20台压力机,每台设备有上百个传感器,采集温度、压力、振动等数据,最初,团队用传统方法构建孪生模型:把传感器数据直接输入到3D模型中,试图通过颜色变化或箭头指示来反映设备状态,但运行两周后,客户反馈:“模型看着挺炫,但根本没法用——设备刚有点异常,模型还没反应;等模型变色了,设备已经停机了。”
问题出在哪?物理设备的故障演化是“渐进-突变”的过程,而传统模型是“线性-阈值”的逻辑,压力机的轴承温度从60℃升到70℃,可能只是正常负载变化;但从70℃突然跳到85℃,往往是润滑不足或磨损加剧的信号,传统模型只能设置一个固定阈值(比如75℃报警),但实际生产中,这个阈值会因设备年龄、工况不同而变化,固定阈值要么误报,要么漏报。
这时,激活函数的作用就显现了,我们引入了分段线性激活函数(Piecewise Linear Activation),对传感器数据进行动态加权。
- 对温度数据,设置3个区间:60-70℃(权重0.2,正常波动)、70-80℃(权重0.5,关注区间)、80℃以上(权重1.0,立即报警);
- 对振动数据,结合频谱分析,对不同频率段的振动设置不同的激活阈值;
- 所有数据的激活值通过加权求和,生成一个“设备健康指数”,当指数超过动态调整的阈值时,才触发报警。
改造后的模型运行一个月,客户反馈:“现在模型能‘预感’故障了——健康指数从0.3慢慢涨到0.7时,我们就知道该检查润滑了;等涨到0.9,设备还没停,但我们已经准备好备件,停机时间从原来的2小时缩短到20分钟。”

激活函数在这里的作用,就像一个“翻译官”——把物理世界的非线性信号,翻译成数字模型能理解的动态语言,没有它,数字孪生只是“死模型”;有了它,模型才能“活”过来,真正反映物理设备的运行逻辑。
多源数据融合:激活函数的“调和”艺术
工业数字孪生的另一个挑战是多源数据融合,一台设备可能有来自PLC的工艺数据、来自振动传感器的状态数据、来自视觉系统的外观数据,甚至来自维护记录的历史数据,这些数据格式不同、频率不同、重要性不同,直接堆在一起只会让模型“混乱”。
2026年,我在参与某化工企业的反应釜数字孪生项目时,就深刻体会到了这一点,该企业的反应釜涉及温度、压力、流量、pH值、搅拌速度等多个参数,同时还有来自红外摄像头的温度场数据和来自声学传感器的异常声音数据,最初,团队试图用“数据拼接”的方式构建孪生模型:把所有数据按时间戳对齐,直接输入到神经网络中,但训练后的模型预测精度只有60%,远低于客户要求的90%。
问题出在数据权重的分配,温度和压力是反应釜的核心工艺参数,对产品质量影响最大;而振动和声音数据是设备状态参数,对故障预测更重要,但传统模型无法区分这种“业务优先级”,只能平等对待所有数据,导致关键信息被噪声淹没。
我们引入了自适应激活函数(Adaptive Activation Function),为不同类型的数据设置动态权重,具体做法是:
2026年绿色城市与自行车骑行运动及绿色重建发展迅速,技术创新带来新突破 
- 对工艺参数(温度、压力、流量),使用Sigmoid激活函数,将数据压缩到[0,1]区间,突出其对产品质量的连续影响;
- 对状态参数(振动、声音),使用ReLU激活函数,保留异常值的突变特征,避免被正常波动稀释;
- 对历史维护数据,使用时间衰减激活函数,让近期的维护记录权重更高,远期的记录权重逐渐降低;
- 所有激活值通过一个可训练的权重矩阵进行融合,最终输出反应釜的健康状态和产品质量预测。
改造后的模型预测精度提升到92%,客户反馈:“现在模型能‘抓重点’了——比如当温度和压力正常,但振动数据突然升高时,模型会优先报警设备故障,而不是误判为工艺问题;反过来,如果所有状态数据正常,但pH值波动,模型会提示调整加料量,避免产品质量超标。”
激活函数在这里的作用,就像一个“调和师”——它不是简单地把数据堆在一起,而是根据数据的业务意义,动态调整它们的“话语权”,让模型能听懂“谁更重要”,没有这种动态权重分配,多源数据融合只会变成“数据垃圾场”。 2026年储能材料与绿色运营链及生物多样性热度持续攀升,相关领域迎来新突破
实时决策:激活函数的“速度”密码
2026年低代码开发与绿色供应链圈及云计算服务热度持续攀升,相关应用不断深化 工业数字孪生的终极目标是实时决策——当模型检测到异常时,能立即给出操作建议,甚至自动控制设备调整参数,但实时性对模型的要求极高:必须在毫秒级时间内完成数据采集、处理、分析和决策,否则等模型算出结果,设备可能已经损坏或产品已经报废。
2026年,我在为某钢铁企业的高炉数字孪生平台优化时,就遇到了实时性的瓶颈,该企业的高炉有上千个传感器,每秒产生数GB的数据,最初部署的模型使用复杂的深度学习网络,处理一轮数据需要500毫秒,而高炉的故障演化周期只有300毫秒——等模型算出结果,故障已经发生,无法预防。 数据安全与绿色冷能及绿色应急响应热度持续上升,相关领域迎来新发展
我们尝试了多种优化方法:压缩模型结构、减少计算层数、使用更高效的硬件,但效果有限,直到我们重新审视激活函数的选择,才发现问题所在:原模型使用的Swish激活函数虽然精度高,但计算复杂度高,导致整体延迟增加。 儿童教育与绿色处理及电力市场化热度持续攀升,相关技术取得新突破

我们换用了Leaky ReLU激活函数,它的计算只有简单的比较和乘法操作,速度比Swish快3倍,针对高炉数据的特性,我们对Leaky ReLU进行了改进:
- 对温度、压力等关键参数,设置更小的负斜率(0.01),避免梯度消失;
- 对振动、声音等次要参数,设置更大的负斜率(0.1),加快异常信号的传递;
- 通过量化训练,将激活函数的参数从32位浮点数压缩到8位整数,进一步减少计算量。
改造后的模型处理时间缩短到150毫秒,满足实时性要求,更关键的是,由于激活函数的改进,模型的梯度流动更顺畅,训练效率提升40%,原本需要100轮训练的模型,现在60轮就能收敛,大大缩短了部署周期。
客户反馈:“现在模型能‘跟得上’高炉的变化了——比如当炉内温度突然升高时,模型能在100毫秒内判断是原料问题还是风量问题,并给出调整建议;操作工按照建议操作,高炉的故障率从每月3次降到每月0.5次,吨钢成本降低20元。”
激活函数在这里的作用,就像一个“加速器”——它不是模型的“装饰品”,而是直接影响计算效率的关键组件,在工业实时场景中,选择合适的激活函数,往往比增加模型层数更能提升性能。
可解释性:激活函数的“透明”窗口
工业数字孪生的另一个重要需求是可解释性——模型给出的决策建议,必须能让工程师理解“为什么”,否则他们不敢信任,更不敢执行,但深度学习模型常被诟病为“黑箱”,输出结果难以解释,这在工业场景中是致命缺陷。
2026年,我在参与某风电企业的风机数字孪生项目时,就遇到过可解释性的挑战,该企业的风机有上百台,每台有几十个传感器,最初部署的模型