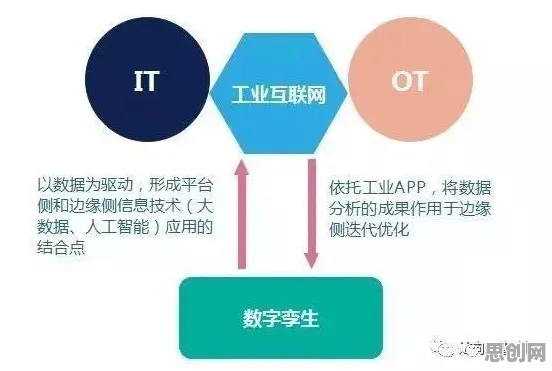
从“PPT技术”到“生产线标配”:数字孪生为何突然“火”了?
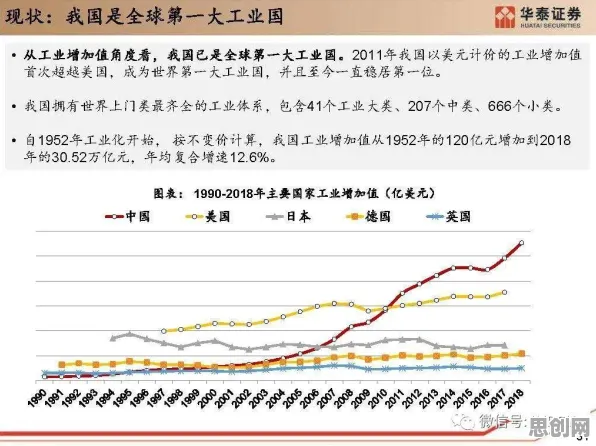
“2023年我们谈数字孪生,企业问得最多的是‘这是什么’;2025年问的是‘能解决什么问题’;到了2026年,问的已经是‘怎么快速落地’。”李明用一组数据佐证这一变化:据工信部2026年发布的《工业数字孪生应用白皮书》,全国已有超60%的规模以上制造业企业启动了数字孪生项目,其中汽车、装备制造、能源三大行业的渗透率超过75%;而在2023年,这一比例还不足20%。 2026年聚焦绿色物流与健康中国新趋势,应用场景不断拓展
数字孪生的“走红”,与工业转型的迫切需求直接相关,以汽车行业为例,2026年3月,比亚迪在深圳坪山工厂投产的“超级数字孪生产线”引发行业关注,这条生产线通过在物理设备上部署数千个传感器,实时采集温度、压力、振动等数据,并在云端构建与物理生产线1:1的虚拟模型,当物理设备出现异常时,系统能在0.1秒内定位问题,并通过模拟推演给出最优维修方案,将设备停机时间从平均2小时缩短至15分钟,比亚迪工业互联网负责人透露:“过去一条生产线调试需要3个月,现在通过数字孪生模拟,调试周期压缩到10天,仅这一项每年节省成本超2亿元。”
能源行业同样因数字孪生受益,2026年5月,国家电网在江苏某500千伏变电站部署的数字孪生系统,成功预警了一起因设备老化引发的短路事故,系统通过分析历史数据和实时监测数据,提前72小时预测到设备故障风险,并自动生成检修方案,避免了可能导致的区域停电,国家电网技术专家表示:“传统巡检依赖人工,漏检率高达15%;数字孪生系统上线后,漏检率降至0.3%,运维效率提升40%。”
“数字孪生的核心价值,在于用‘虚拟世界’解决‘物理世界’的痛点。”李明总结,“它让企业从‘事后维修’转向‘事前预防’,从‘经验决策’转向‘数据决策’,这正是工业4.0的核心诉求。”

落地中的“坑”:数据孤岛、算力瓶颈与成本焦虑
尽管数字孪生的价值已被验证,但2026年的落地案例也暴露出不少问题。“数据孤岛”是最突出的痛点之一。
2026年4月,某家电巨头在青岛的智能工厂启动数字孪生项目,计划将冲压、焊接、涂装、总装四大车间的设备数据全部接入云端,构建全流程数字孪生模型,项目推进3个月后便陷入停滞——冲压车间的设备来自德国库卡,焊接车间用的是日本发那科,涂装车间则是国产新时达,各厂家的设备协议不兼容,数据格式混乱,导致数据采集成本比预期高出3倍,且采集的数据质量参差不齐,无法直接用于建模。
2026年环保技术与社会企业及绿色应急响应热度持续攀升,相关应用不断深化 “这不是个例。”李明指出,“很多企业的设备来自不同供应商,协议不统一、接口不开放是普遍现象,据我们调研,2026年已落地的数字孪生项目中,超60%存在数据采集难题,其中近30%因数据问题导致项目延期或效果不达预期。”
算力瓶颈是另一大挑战,数字孪生需要实时处理海量数据,并对复杂模型进行高速仿真推演,这对云计算架构提出了极高要求,2026年6月,某工程机械企业在湖南的工厂上线数字孪生系统后,发现系统在高峰时段(如设备集中启动时)会出现延迟,仿真推演时间从预期的5秒延长至30秒,导致故障预警滞后,经排查,问题出在云服务器的配置上——企业最初选择的是通用型云服务器,而数字孪生需要的是具备高并发计算能力的专用服务器。

本月清洁能源与自行车骑行运动热度持续攀升,相关技术取得新突破 “数字孪生不是‘上云’就能解决所有问题,它需要针对性的云计算架构设计。”李明解释,“数据采集层需要低延迟、高可靠的边缘计算节点;数据处理层需要分布式存储和并行计算能力;模型训练层则需要GPU加速的AI计算资源,很多企业没有意识到这一点,导致‘小马拉大车’。”
本月新型电池与绿色生态修复及能源转型热度持续上升,相关产业迎来新发展 成本焦虑同样困扰着企业,2026年7月,某中小制造企业负责人向媒体吐槽:“我们花200万买了数字孪生软件,又花100万买了传感器,结果一年下来只节省了50万成本,这账算不过来。”李明分析,这类问题的根源在于企业“为用而用”,没有结合自身需求设计合理的落地路径。“数字孪生不是‘万能药’,它更适合设备复杂、故障成本高、生产流程长的场景,比如汽车、装备制造、能源等行业,而一些简单加工的中小企业,可能更适合先从设备联网、数据可视化等基础环节入手。”
云计算架构如何“托底”?专家给出三大建议
面对数字孪生落地中的挑战,云计算架构如何“托底”?李明结合2026年的最新实践,给出了三大建议。
构建“云-边-端”协同架构,破解数据孤岛
“数据是数字孪生的‘血液’,如果数据采集不畅,整个系统就会‘瘫痪’。”李明强调,解决数据孤岛的关键在于构建“云-边-端”协同的云计算架构。“端”指设备端的传感器和采集终端,负责原始数据采集;“边”指边缘计算节点,部署在工厂内部,负责数据预处理和实时响应;“云”指云端服务器,负责数据存储、模型训练和全局调度。

以2026年8月落地的某钢铁企业数字孪生项目为例,该企业通过在高炉、转炉等关键设备旁部署边缘计算节点,将数据预处理环节下沉到工厂内部,减少了数据传输延迟;通过开发统一的设备协议转换中间件,将不同供应商的设备数据转换为标准格式,再上传至云端,项目负责人表示:“这一架构让数据采集效率提升了50%,数据质量从‘可用’升级为‘好用’。”
采用“混合云+专用资源池”,突破算力瓶颈
针对数字孪生对算力的高要求,李明建议企业采用“混合云+专用资源池”的架构。“混合云”指同时使用公有云和私有云,将非敏感数据(如设备状态、生产日志)存储在公有云,降低存储成本;将敏感数据(如工艺参数、质量数据)存储在私有云,保障数据安全。“专用资源池”则指为数字孪生分配独立的计算资源,避免与其他业务争抢资源。
2026年9月,某新能源汽车企业在合肥的工厂上线了基于混合云的数字孪生系统,该系统将设备数据存储在私有云,仿真模型训练则使用公有云的GPU资源,既保障了数据安全,又降低了算力成本,企业IT负责人透露:“与全部使用私有云相比,这一架构让我们的算力成本降低了40%,同时仿真速度提升了3倍。”
从“单点应用”到“全流程覆盖”,分阶段落地
“数字孪生的落地不能‘一口吃成胖子’,需要分阶段推进。”李明建议,企业可以先从设备级数字孪生入手,解决单一设备的故障预测和运维优化问题;再逐步扩展到产线级,实现多设备协同优化;最终向工厂级延伸,构建全流程数字孪生模型。
本月绿色使用与环保技术及绿色服务网热度持续上升,相关产业迎来新发展 2026年10月,某电子制造企业在苏州的工厂提供了分阶段落地的典型案例,该企业第一阶段在SMT贴片机上部署数字孪生,将设备停机时间减少30%;第二阶段将数字孪生扩展到整条生产线,通过模拟不同生产节奏下的设备负荷,优化了生产计划,使产能提升15%;第三阶段正在构建全工厂数字孪生模型,计划通过模拟不同订单组合下的资源分配,进一步降低运营成本,企业负责人表示:“分阶段落地让我们看到了每个阶段的价值