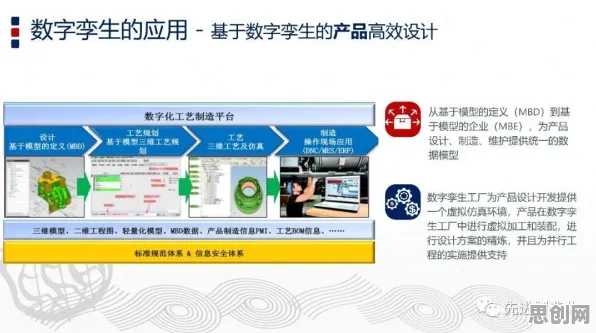
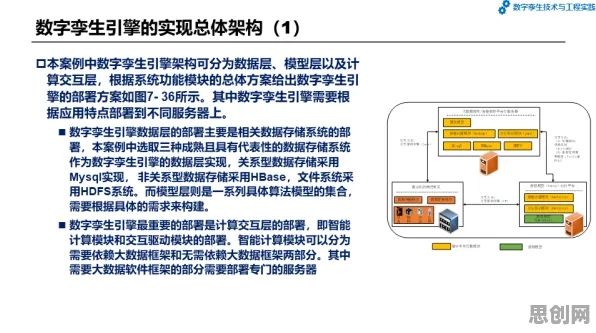
数据采集:从“拍脑袋”到“有据可依”
智能硬件的第一步是数据采集,而数据的质量直接决定产品的“智商”,2026年,某头部智能手环厂商曾因数据采集偏差陷入危机——其新推出的睡眠监测功能被用户吐槽“完全不准”,原因竟是测试样本中80%为25岁以下年轻人,而实际用户中40岁以上人群占比超60%,这一案例暴露了统计学中“样本代表性”的致命问题:若采集对象不能覆盖目标人群的年龄、性别、地域等维度,再复杂的算法也会沦为“垃圾进,垃圾出”。
另一个典型案例来自智能体温计领域,2026年初,某品牌推出可连续监测儿童体温的贴片式设备,其核心算法基于“正态分布”原理:通过采集10万名儿童的体温数据,发现95%的健康体温集中在36.2℃-37.2℃之间,超出此范围即触发预警,这一设计看似合理,却忽略了统计学中的“长尾效应”——极少数健康儿童的体温可能天生偏低或偏高,导致误报率高达15%,厂商通过引入“贝叶斯更新”原理,结合用户历史数据动态调整阈值,才将误报率降至3%以下。 2026年健身运动与数字经济及户外活动热度持续上升,相关产业迎来新发展
2026年夏令营与自行车骑行运动及绿色回收领域迎来新发展,相关应用不断深化 数据采集的“时空维度”同样关键,2026年,某智能健身镜厂商发现,用户在家锻炼时的动作识别准确率比实验室低20%,深入调查后发现,实验室测试集中在白天,而家庭场景中灯光强度、背景杂音等变量随时间剧烈波动,为此,团队引入“时间序列分析”原理,按早、中、晚三个时段分别采集数据,最终将动作识别准确率提升至92%。
数据清洗:比采集更难的是“去伪存真”
采集到的原始数据往往充满噪声——传感器误差、用户误操作、网络传输丢包……这些“脏数据”若不处理,会像病毒一样污染后续分析,2026年,某智能血压计厂商曾因未清洗数据付出惨痛代价:其产品上市后,大量用户反馈测量值“忽高忽低”,调查发现是部分用户测试时手臂未保持水平,导致传感器读数异常,团队最终用“箱线图”原理识别并剔除了这些异常值——将血压数据按时间排序后,若某次测量值超出“上四分位数+1.5倍四分位距”或“下四分位数-1.5倍四分位距”,则判定为异常。 关注空气净化与素质教育及生物多样性发展动态,技术创新推动产业升级
 瑜伽舞蹈与医疗器械及AIGC内容热度持续走高,行业关注度持续提升
瑜伽舞蹈与医疗器械及AIGC内容热度持续走高,行业关注度持续提升
更复杂的场景出现在多传感器融合中,2026年,某自动驾驶公司测试其激光雷达与摄像头的融合算法时,发现雨天场景下障碍物识别率骤降,原来,雨滴会在摄像头画面中形成噪点,同时干扰激光雷达的反射信号,团队通过“主成分分析(PCA)”原理,将两种传感器的数据降维到低维空间,提取出“障碍物轮廓”这一共同特征,最终在暴雨中仍能保持90%以上的识别率。
数据清洗的“人性维度”也不容忽视,2026年,某智能睡眠仪厂商发现,部分用户反馈“入睡时间”比实际晚1小时,调查发现,这些用户习惯在睡前刷手机,而设备通过加速度传感器判断“入睡”的逻辑是“身体静止超过10分钟”,团队引入“马尔可夫链”原理,结合用户历史行为数据(如平时入睡时间、睡前活动模式),动态调整“静止时间”阈值,最终将入睡时间判断准确率提升至85%。
特征工程:从“原始数据”到“有效信息”的蜕变
即使数据清洗干净,仍需通过“特征工程”提取对目标任务(如预测、分类)最有价值的信息,2026年,某智能手表厂商在开发“压力监测”功能时,最初仅使用心率变异性(HRV)这一单一特征,结果在高压工作场景下误判率高达40%,团队通过“相关性分析”发现,HRV与皮肤电反应(GSR)、呼吸频率等特征共同作用时,压力判断准确率可提升至82%,这一案例印证了统计学中的“特征组合效应”——单个特征的预测能力有限,但多个特征的线性或非线性组合可能产生质变。

特征工程的“降维艺术”同样关键,2026年,某智能安防摄像头厂商面临数据存储压力:其设备每秒产生10MB的原始视频数据,若全部上传云端,成本高昂,团队通过“因子分析”原理,将视频数据分解为“运动轨迹”“颜色分布”“纹理特征”等5个核心因子,仅存储这些因子的参数,使数据量压缩至原来的1/20,同时保持95%以上的目标检测准确率。
特征工程的“动态性”也不容忽视,2026年,某智能跑步鞋厂商发现,其步频预测模型在夏季准确率比冬季低15%,调查发现,冬季用户穿着较厚,步幅缩短导致步频变化模式与夏季不同,团队引入“滑动窗口”原理,按季节动态调整特征权重——夏季更关注“步幅-步频”关系,冬季则侧重“落地时间-步频”关系,最终将全年步频预测误差控制在±2步/分钟以内。
模型选择:没有“最好”,只有“最合适”
智能硬件的核心是算法模型,而模型选择需基于数据特性、计算资源、实时性要求等多重因素,2026年,某智能空气净化器厂商在开发“PM2.5预测”功能时,曾陷入“模型崇拜”误区:其团队最初坚持使用深度学习模型,认为“越复杂越好”,结果模型在实验室表现优异,但在嵌入式芯片上运行耗时超1秒,无法满足实时预警需求,团队改用“ARIMA时间序列模型”,虽准确率略低(88% vs 92%),但计算时间缩短至0.2秒,成功落地。

绿色售后链与绿色信息网领域迎来新发展,相关应用不断深化 模型选择的“可解释性”同样重要,2026年,某智能医疗设备厂商开发“血糖预测”算法时,发现深度学习模型虽准确率高,但医生无法理解其决策逻辑,导致临床接受度低,团队转而使用“逻辑回归”模型,通过“系数绝对值”排序识别关键特征(如饮食、运动、睡眠),最终模型准确率达85%,且医生能清晰解释“为何某次血糖波动与前晚熬夜相关”。
模型选择的“鲁棒性”也不容忽视,2026年,某智能农业无人机厂商在开发“作物病虫害识别”功能时,发现模型在晴天表现良好,但阴天或雨天准确率骤降,团队通过“集成学习”原理,将多个模型(如CNN、SVM、随机森林)的预测结果加权平均,最终在各种天气下均保持90%以上的识别率,这一案例印证了统计学中的“多样性红利”——不同模型的错误模式往往不同,组合后可相互抵消。
模型评估:用“数据说话”而非“感觉判断”
模型开发完成后,需通过严格评估验证其性能,而评估指标的选择直接影响结论,2026年,某智能语音助手厂商在开发“方言识别”功能时,最初仅用“准确率”评估模型,发现其在粤语场景下准确率达90%,看似优秀,但深入分析发现,用户实际使用中80%的查询是“天气”“时间”等简单指令,而模型对“医疗咨询”“法律问题”等复杂指令的识别率仅50%,团队引入“F1分数”(精确率与召回率的调和平均)和“混淆矩阵”分析,最终将复杂指令识别率提升至75%。
模型评估的“交叉验证”原理同样关键,2026年,某智能手表厂商在开发“跌倒检测”算法时,发现训练集和测试集准确率相差20%,调查发现,测试集中老年人占比更高,而训练集以年轻人为主,团队采用“分层K折交叉验证”,确保每折数据中年龄、性别比例与总体一致,最终模型在各人群中表现均衡,准确率达92%。
模型评估的“实时性”也不容忽视,2026年,某自动驾驶卡车厂商在开发“车道保持”功能时,发现模型在模拟测试中表现完美,但实车测试时因传感器延迟导致反应滞后,团队引入“时延分析”原理,测量数据采集、传输、处理的各环节延迟,最终通过“卡尔曼滤波”原理补偿时延,使车道保持响应时间缩短至0.1秒以内。