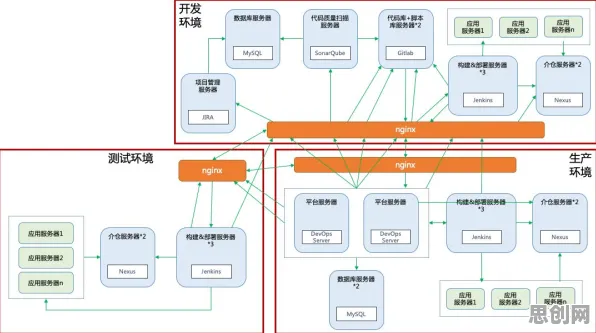
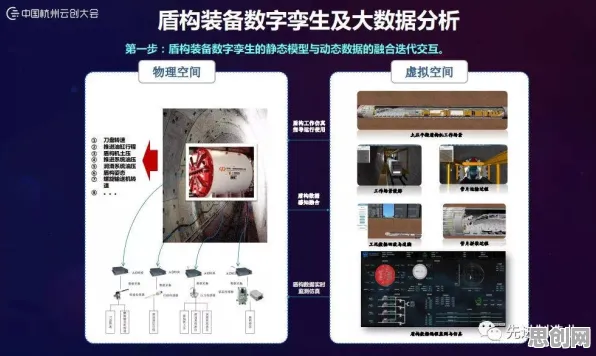
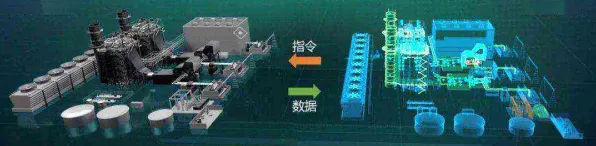
低碳办公与绿色服务链及物业管理热度持续上升,相关产业迎来新机遇 2026年的工业圈,数字孪生技术早已不是新鲜词,但关于其部署实践的讨论却像一锅持续沸腾的热水,越搅越热,从德国的智能工厂到中国的长三角制造集群,从航空航天的高精尖领域到汽车制造的流水线,企业们一边摸着石头过河,一边急着分享“踩过的坑”和“挖到的宝”,而今年,一个新变量闯入了这场讨论——量子BERT(Quantum Bidirectional Encoder Representations from Transformers),这个结合了量子计算与自然语言处理的技术,正为工业数字孪生的部署实践撕开一道新的裂缝,让原本卡在“数据-模型-应用”闭环里的企业看到了新的可能。
数字孪生的“老问题”:数据孤岛与模型滞后
先说说数字孪生在工业部署中的“老毛病”,2026年,尽管大部分制造企业已经完成了设备联网、数据采集的基础建设,但“数据孤岛”依然像顽固的结石,卡在系统的喉咙里,某汽车零部件厂商在2025年上线了数字孪生平台,试图通过虚拟模型实时监控生产线的状态,结果发现:设备传感器数据、ERP的生产订单数据、质量检测系统的缺陷数据,分别存放在三个不同的数据库里,格式不统一、更新频率不一致,导致孪生模型要么“吃不到”完整数据,要么“吃”的是过时数据,预测结果和实际生产偏差高达15%。
更棘手的是模型滞后问题,传统数字孪生模型多基于物理方程或统计方法构建,一旦生产条件变化(比如换了新设备、调整了工艺参数),模型就需要重新校准,耗时又耗力,某电子制造企业曾分享过一个案例:他们为一条SMT贴片线建了数字孪生模型,原本预测设备故障的准确率能达到85%,但当生产线从单班制改为双班制后,设备负载模式变了,模型准确率直接掉到60%,花了两个月才重新调好参数。
热度持续增长精准医疗持续升温,技术创新带来新突破 “数据不好用,模型跟不上”——这成了2026年工业数字孪生部署的两大“拦路虎”,企业们不是不想解决,而是传统技术路径下,解决成本太高、效率太低。
量子BERT:从语言到工业的“跨界者”
这时候,量子BERT登场了,这个技术最早在2024年由谷歌量子AI团队提出,原本是为了解决自然语言处理中的长文本理解问题,传统BERT模型通过“预训练+微调”的方式处理文本,但面对超长文档(比如法律合同、科研论文)时,计算量会指数级增长,普通计算机根本跑不动,量子BERT的思路是:用量子比特的叠加和纠缠特性,把文本中的语义关系编码成量子态,通过量子门操作实现高效的信息提取,计算速度比经典BERT快几十倍。 氢能技术与社会责任领域取得重要进展,行业关注度持续提升
2026年,这项技术开始“跨界”到工业领域,为什么?因为工业数据和语言数据有相似之处——都是“非结构化”的,设备传感器数据是时间序列,质量检测报告是文本描述,维修工单是自然语言记录,这些数据看似不同,但背后都藏着设备的“健康状态”和生产的“运行逻辑”,量子BERT的强项,就是从这些杂乱的数据中“挖”出隐藏的模式,而且不用像传统方法那样,先花大量时间做数据清洗和特征工程。
举个2026年3月的真实案例,某风电设备制造商在部署数字孪生时,遇到了一个典型问题:他们的风机分布在全国多个风电场,每台风机有上千个传感器,每天产生TB级的数据,但这些数据里混着大量“噪声”——比如传感器故障时的异常值、环境干扰导致的波动,传统方法需要人工标注“正常数据”和“异常数据”,再训练分类模型,耗时且容易出错,而这家企业尝试用量子BERT处理:先把传感器数据转换成“时间序列文本”(比如把数值序列写成“12.5,13.1,14.0...”),再用量子BERT学习这些“文本”的语义模式,结果发现,量子BERT能自动识别出数据中的异常模式,准确率比传统方法高20%,而且训练时间从两周缩短到三天。
从“数据融合”到“实时决策”:量子BERT的工业落地场景
量子BERT在工业数字孪生中的价值,不止于数据清洗,2026年,企业们正在探索更多落地场景,其中最核心的是两个方向:数据融合和实时决策。

数据融合:打破孤岛的“翻译器”
工业数据孤岛的根源,是不同系统的数据格式、语义不一致,设备PLC记录的是“开关量”(0或1),MES系统记录的是“工序名称”(如“装配”),质量系统记录的是“缺陷代码”(如“A01”),这些数据之间没有直接的对应关系,传统方法需要人工定义“映射规则”,但规则一旦变化(比如新增了缺陷类型),就要重新修改代码,维护成本极高。
量子BERT的解法是:把所有数据都当成“语言”来处理,把PLC的开关量序列、MES的工序名称、质量的缺陷代码,分别转换成“设备语言”“生产语言”“质量语言”,再用量子BERT学习这三种语言之间的“翻译规则”,2026年5月,某半导体厂商做了个实验:他们用量子BERT构建了一个“数据翻译器”,把设备日志、生产记录、质量报告的数据统一转换成一种“中间语义”,再输入到数字孪生模型中,结果发现,原本需要三天才能完成的数据对齐工作,现在只要半天;而且当生产线上新增了一种工艺时,模型能自动适应,不用重新训练。
实时决策:从“事后分析”到“事中干预”
数字孪生的终极目标,是让虚拟模型能实时指导物理世界的操作,但传统模型受限于计算速度,往往只能做“事后分析”——比如等一批产品生产完后,才分析出哪里出了问题,而量子BERT的量子计算特性,让实时决策成为可能。
2026年7月,某汽车主机厂上线了一套基于量子BERT的数字孪生系统,用于监控焊接车间的质量,焊接过程中,电流、电压、焊接时间的微小变化都会影响焊缝质量,但这些变化发生得极快(毫秒级),传统模型根本来不及反应,这家企业用量子BERT处理传感器数据:先把电流、电压的时间序列转换成“量子态”,再通过量子门操作实时计算焊缝质量的“风险值”,当风险值超过阈值时,系统会立即触发警报,并自动调整焊接参数,上线第一个月,焊缝缺陷率从0.8%降到0.3%,而且整个过程不需要人工干预。
挑战与争议:量子BERT不是“万能药”
量子BERT在工业领域的落地并非一帆风顺,2026年,企业们在实际部署中也遇到了不少挑战。
 2026年量子计算与电子商务热度持续上升,相关产业迎来新发展
2026年量子计算与电子商务热度持续上升,相关产业迎来新发展
硬件成本,量子计算目前仍处于“混合阶段”——大部分企业用的是“量子-经典混合计算”,即用量子芯片处理部分计算,其余部分仍靠经典计算机,某化工企业曾尝试用量子BERT优化生产调度,结果发现,为了支撑量子计算部分,需要采购一台价值数百万的量子服务器,而传统方法的服务器成本只要几十万,对于中小企业来说,这笔投入可能“吃不消”。
人才缺口,量子BERT需要既懂量子计算、又懂工业业务的复合型人才,但这类人才在市场上非常稀缺,2026年9月,某招聘平台的数据显示,全国“量子工业工程师”的岗位需求比2025年增长了300%,但符合要求的候选人不足需求的10%,某家电企业曾吐槽:“我们招了三个月,只找到一个能勉强上手的量子工程师,结果他干了两个月就跳槽了。”
技术成熟度,尽管量子BERT在实验室里表现不错,但在工业现场的复杂环境中,稳定性仍需验证,2026年11月,某钢铁企业反馈,他们用量子BERT预测高炉温度时,发现模型在白天和晚上的预测偏差较大,后来排查发现是环境温度干扰了量子传感器的数据,这类“意外”让企业对大规模部署持谨慎态度。
2026年的新趋势:量子BERT与工业元宇宙的融合
尽管有挑战,但量子BERT在工业数字孪生中的价值已被越来越多企业认可,2026年,一个新趋势正在浮现:量子BERT开始与工业元宇宙深度融合。
2026年环境税与空气净化热度持续攀升,相关技术取得新突破 工业元宇宙的核心是“虚实共生”,即通过数字孪生构建一个与物理世界完全同步的虚拟空间,用户可以在虚拟空间中操作、监控、优化物理设备,但传统工业元宇宙受限于计算能力,虚拟空间的“实时性”和“细节度”不够——虚拟设备的动作可能比物理设备慢半拍,或者无法展示设备的内部结构。
量子BERT的加入,正在改变这一