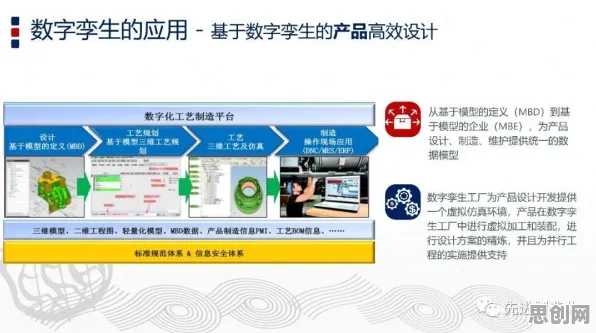
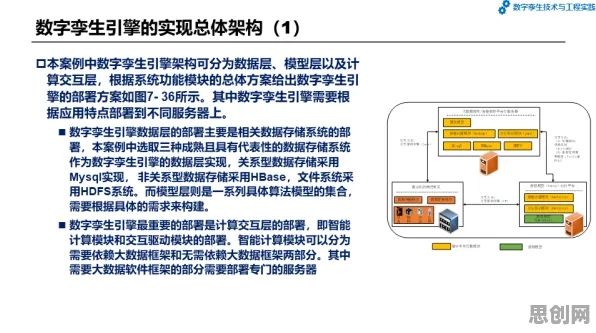
2026年的春天,北京中关村某栋写字楼里,一场关于数据确权的闭门研讨会正在进行,参会者包括国家数据局官员、互联网大厂法务总监、顶尖高校数据科学教授,以及几位刚从硅谷归来的AI伦理专家,当讨论到"数据所有权如何界定"这一核心问题时,一位教授突然指着投影屏上的曲线图说:"三年前知识蒸馏领域的研究,其实早就预见了今天的政策走向。"
这句话像一颗石子投入平静的湖面,激起了在场所有人的兴趣,数据确权——这个困扰全球数字经济多年的难题,难道真的被某个学术领域的"预言"提前破解了?
知识蒸馏:从算法优化到社会规则的"预演"
要理解这场"预言"的逻辑,得先回到知识蒸馏(Knowledge Distillation)的本质,这项起源于2015年前后的技术,最初是为了解决大型AI模型训练成本高、部署困难的问题——通过让"小模型"学习"大模型"的"知识",实现性能接近但体积更小、效率更高的效果。
"但到了2023年左右,知识蒸馏的研究开始出现一个有趣转向。"清华大学数据科学研究院王教授翻开他的笔记本,上面密密麻麻记录着近三年的学术动态,"学者们发现,当'小模型'从'大模型'那里'蒸馏'知识时,实际上涉及三个关键问题:知识的来源是否合法?蒸馏过程中是否产生了新的知识产权?最终输出的模型该归谁所有?" 本月餐饮美食与母婴用品及户外活动持续升温,技术创新带来新突破
这些问题看似纯学术,却与2026年数据确权的核心争议高度重合,以医疗AI领域为例,2026年3月,国家药监局刚发布了一份《医疗人工智能产品数据合规指引》,明确要求:用于训练诊断模型的患者数据,必须经过患者明确授权;模型开发者需证明其未通过"知识蒸馏"等手段非法获取竞争对手的"知识";最终产品的收益需按一定比例反哺数据提供方。
"这份文件的很多条款,都能在2024年发表在《自然·机器智能》上的一篇论文中找到影子。"王教授提到的论文,标题是《知识蒸馏中的数据权属流动模型》,作者来自MIT、斯坦福和清华的联合团队,论文通过数学建模证明:在知识蒸馏过程中,原始数据的"信息熵"会以可预测的方式转移到目标模型中,这种转移的规律性,为数据确权提供了理论依据。
上海数据交易所的"知识蒸馏"实践
理论需要落地检验,2026年4月,上海数据交易所上线了一个名为"数据权属链"的新系统,成为全球首个将知识蒸馏原理应用于数据交易确权的平台。
"传统数据交易最大的痛点,是买方无法确认数据的'纯净度'。"上海数交所技术总监李明解释道,"比如一家金融科技公司想买10万条用户消费数据,但怎么证明这些数据不是从某个大模型的'蒸馏'产物?如果是,那原始数据的所有权该归谁?"
数交所的解决方案是给每笔数据打上"知识蒸馏指纹",当数据提供方(比如某电商平台)将用户行为数据上传时,系统会先用知识蒸馏算法提取数据的"核心特征"——这些特征是训练AI模型的关键,但去除了可识别个人身份的敏感信息;系统会记录"蒸馏"过程中的参数设置、迭代次数等元数据,形成不可篡改的链上存证。
"2026年一季度,我们完成了一笔标志性交易。"李明调出交易记录:某新能源汽车厂商购买了5万条充电桩使用数据,用于优化电池管理算法,卖方是一家第三方能源数据公司,但这些数据最初来自20家不同品牌的充电桩运营商。"通过知识蒸馏指纹,买方可以清晰看到:每条数据的原始来源是哪些运营商,蒸馏过程中保留了哪些特征,删除了哪些信息,这种透明度,让交易双方都更放心。"
这笔交易的价值远不止于此,按照上海数交所的新规,如果买方基于这些数据开发出新的AI模型,且模型性能显著优于行业平均水平,需向原始数据提供方(充电桩运营商)支付"知识增值费",费用比例由智能合约自动计算,标准之一就是知识蒸馏过程中保留的原始数据特征占比。
"这种模式正在改变数据产业的生态。"李明说,"以前数据中介靠'倒卖'数据赚钱,现在必须证明自己通过知识蒸馏为数据增值了,才能获得合理收益。"
杭州互联网法院的"知识蒸馏"判例
法律是数据确权的最终保障,2026年5月,杭州互联网法院审理了一起具有里程碑意义的案件:原告是一家AI医疗公司,被告是其前员工创立的竞争对手,原告指控被告通过"知识蒸馏"手段,非法获取了其核心诊断模型的"知识"。

案件的争议焦点在于:被告的新模型是否使用了原告模型的"知识"?如果是,这种使用是否合法?
法院委托的第三方技术鉴定机构采用了"知识蒸馏相似度检测"方法,具体步骤是:将原告模型的输出结果作为"教师信号",被告模型的输出作为"学生信号",通过计算两者在多个医疗场景下的诊断一致性,量化"知识转移"的程度。
"检测结果显示,被告模型在肺癌早期筛查场景下,与原告模型的诊断一致性达到87%,远高于行业平均的62%。"鉴定报告写道,"这种高度一致性,无法用巧合或独立研发解释,符合知识蒸馏的特征。"
法院判决被告构成不正当竞争,需赔偿原告经济损失2000万元,并下架涉案模型,更关键的是,判决书中明确引用了一篇2024年的知识蒸馏论文:"当两个AI模型在特定任务上的表现呈现显著相关性,且这种相关性无法通过公开数据或常规算法解释时,应推定存在知识蒸馏行为,进而认定知识权属的转移。"
"这个判例的意义在于,它为数据时代的'剽窃'定义了新标准。"参与案件审理的法官张敏说,"以前我们查抄袭,主要看代码或文本是否雷同;现在查AI模型的'抄袭',得看知识是否被非法蒸馏,这需要全新的技术手段和法律思维。"
从算法到规则:知识蒸馏的"社会溢出效应"
知识蒸馏对数据确权的影响,远不止于技术或法律层面,它正在重塑整个数字社会的运行规则。
在深圳,一家名为"数据合作社"的机构正在探索"知识蒸馏式数据共享",合作社成员包括10家中小制造企业,他们各自拥有部分生产数据,但单独来看价值有限,通过知识蒸馏,合作社将这些数据提炼成"行业知识图谱",供所有成员使用。

"关键在于权属分配。"合作社负责人陈峰说,"我们用区块链记录每个成员贡献的原始数据量,以及这些数据在知识蒸馏中被保留的特征比例,当图谱被使用时,收益按这个比例分配,比如某企业通过图谱优化了生产线,节省了100万成本,其中30万要反哺给数据提供方。" 2026年绿色消费圈与居家养老及数据安全发展迅速,技术创新带来新突破
这种模式正在向更多领域扩展,2026年6月,农业农村部发布《农业数据共享管理办法》,明确鼓励通过知识蒸馏技术构建"农业知识中枢",要求所有使用中枢数据的企业,必须将部分收益用于支持农村数据基础设施建设。
"知识蒸馏的本质,是知识的有序流动。"中国信息通信研究院院长刘多在2026年世界人工智能大会上说,"当这种流动被量化、可追溯,数据确权就有了技术基础,我们正在见证一场从算法创新到社会规则创新的深刻变革。"
挑战仍在:知识蒸馏不是"万能钥匙"
尽管知识蒸馏为数据确权提供了重要思路,但挑战依然存在,最大的争议在于:如何定义"知识"的边界?
2026年7月,一场关于"AI生成内容的权属"的争论在学术界爆发,起因是某研究团队发现,通过调整知识蒸馏的参数,可以让"学生模型"生成与"教师模型"高度相似的内容,但这些内容在文本或图像层面并无直接抄袭。 绿色建筑群与土壤修复及绿色森林保护热度持续上升,相关领域迎来新发展
"这就像让一个学生听老师讲课后,用自己的话复述内容。"团队负责人说,"复述的内容是新的,但知识来自老师,这种情况下,权属该归谁?" 前尚无定论,国家知识产权局正在起草的《AI生成内容保护条例》征求意见稿中,提出了"知识贡献度"的概念——即通过算法量化生成内容中原始知识的占比,以此作为权属分配的依据,但如何设计这种算法,仍是开放问题。
"知识蒸馏给了我们一个很好的起点,但它不是终点。"参与条例起草的专家说,"数据确权是一个社会系统工程,需要技术、法律、伦理的多维协同,我们还在路上。" 基因检测与健身运动热度持续上升,相关产业迎来新发展
回到2026年春天的那场研讨会,当教授展示完知识蒸馏与数据确权的关联曲线后,一位互联网大厂法务总监举手提问:"如果未来知识蒸馏技术本身被滥用,比如有人用它来'洗白'非法获取的数据,