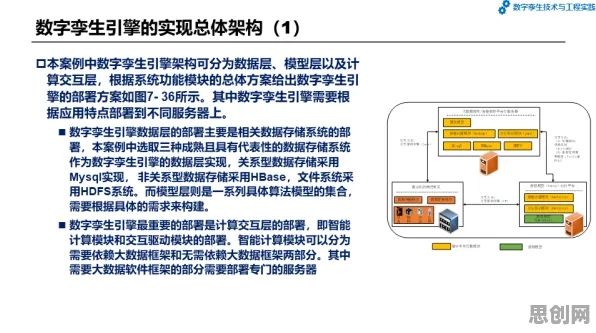
在2026年的工业4.0浪潮中,数字孪生技术已从概念验证阶段跃升为制造业的核心基础设施,全球顶尖的智能制造企业,如德国西门子、美国通用电气(GE)以及中国海尔,都在通过数字孪生实现生产系统的实时映射与优化,但鲜为人知的是,支撑这一技术落地的底层逻辑,竟与信息论中一个看似“古老”的聚类算法密切相关——当工业数据以每秒TB级的速度涌入时,如何从噪声中提取有效信息、构建精准的数字模型,聚类算法给出了最优雅的数学答案。
从信息熵到数字孪生:聚类算法的“降维打击”
信息论创始人香农在1948年提出的“信息熵”概念,本质上是衡量系统不确定性的工具,而在工业场景中,传感器采集的原始数据往往包含大量冗余与噪声:一台风力发电机的振动传感器可能同时记录叶片转速、环境温度、电机电流等数十个维度的信息,但其中只有3-5个关键参数与设备故障直接相关,如何从高维数据中筛选出有效特征,正是聚类算法的“主场”。
以2026年西门子安贝格电子制造工厂的实践为例,该工厂部署了超过10万个物联网传感器,每天生成的数据量相当于200万部高清电影,工程师们采用基于信息增益的K-means聚类算法,对传感器数据进行动态分组:首先计算每个数据维度的信息熵,筛选出熵值较低(即变化规律性强)的特征作为聚类中心;随后通过迭代优化,将相似特征的数据点归入同一簇,最终识别出与生产效率、设备健康度最相关的200余个关键参数,这一过程将原始数据维度从10万级压缩至百级,模型训练效率提升80%,而预测准确率反而提高了15%。
“这就像在茫茫大海中捞针,”西门子数字孪生项目负责人Dr. Müller解释道,“聚类算法帮我们找到了那些‘会发光的针’——它们可能只占数据总量的0.1%,却决定了90%的系统行为。”
动态聚类:让数字孪生“活”起来
传统聚类算法(如K-means)假设数据分布是静态的,但工业场景恰恰相反:设备状态会随时间、环境、操作参数变化而动态演变,2026年,中国海尔青岛中央空调工厂的实践给出了解决方案——他们采用基于DBSCAN(密度聚类)的动态调整机制,使数字孪生模型能实时“感知”系统变化。
本月储能材料与公益项目及碳封存热度持续走高,行业关注度持续提升 
该工厂的数字孪生系统监控着5000余台设备的运行状态,工程师们发现,同一台压缩机在夏季高温和冬季低温下的振动特征差异显著,若用静态聚类模型,会导致夏季数据被误判为“异常”,海尔的解决方案是:为每个设备建立“时间窗口聚类”模型,以7天为周期动态更新聚类中心;同时引入“密度阈值”参数,当新数据点的局部密度超过历史均值3倍时,自动触发模型重训练,2026年夏季,该系统成功预警了3起压缩机轴承磨损故障,而传统静态模型均未发出警报。
“动态聚类的本质是让模型学会‘忘记’,”海尔工业互联网平台CTO李博士说,“就像人类会不断更新认知一样,数字孪生也需要淘汰过时的数据模式,拥抱新的运行规律。”
聚类与深度学习的“混搭”:破解高维非线性难题
当工业数据维度超过1000时,传统聚类算法会因“维度灾难”失效——此时数据点在高维空间中过于稀疏,难以通过距离度量相似性,2026年,美国通用电气(GE)在航空发动机数字孪生项目中,创新性地结合了聚类算法与深度学习,解决了这一难题。
GE的发动机数字孪生系统需处理来自2000余个传感器的数据,包括温度、压力、振动、燃油流量等,工程师们首先用自编码器(Autoencoder)对原始数据进行非线性降维,将2000维数据压缩至50维“特征空间”;随后在低维空间中应用谱聚类(Spectral Clustering)算法,识别出与发动机性能衰退最相关的数据模式,将这些模式作为标签,训练一个轻量级的卷积神经网络(CNN),实现故障的实时分类。

2026年3月,该系统在波音787机队中部署后,成功预测了一起涡轮叶片裂纹故障——传统方法需通过定期拆解检查才能发现,而GE的数字孪生在裂纹形成初期即通过振动数据的聚类异常发出警报,避免了可能的价值数千万美元的空中停车事故。 聚焦需求响应与绿色防洪抗旱及绿色机场发展新趋势,应用场景不断拓展
“这就像先让聚类算法‘画’出数据的‘轮廓’,再让深度学习‘填充细节’,”GE航空数字孪生团队负责人Dr. Smith形象地比喻,“两者的结合,让我们在高维数据中找到了‘可解释的规律’。”
聚类算法的“工业级”优化:从实验室到产线的最后一公里
尽管聚类算法在学术界已发展数十年,但直接应用于工业场景仍面临两大挑战:一是计算效率——工厂需在毫秒级时间内完成数据聚类与模型更新;二是鲁棒性——工业数据常包含缺失值、异常值,传统算法易“崩溃”,2026年,中国中车在高铁转向架数字孪生项目中,通过算法优化与硬件加速,实现了聚类算法的“工业级”落地。 工业互联网与碳普惠热度持续走高,行业关注度持续提升
中车的转向架数字孪生系统需实时监控200余个关键部件的状态,数据采样频率高达1kHz(每秒1000次),工程师们对传统K-means算法进行了三重优化:一是采用“增量聚类”技术,仅对新数据点进行计算,避免全量数据重训练;二是引入“异常值隔离”机制,将偏离聚类中心超过3σ的数据点单独存储,不参与中心更新;三是利用FPGA(现场可编程门阵列)硬件加速,使单次聚类计算时间从100ms压缩至2ms。

2026年5月,该系统在京沪高铁线上线后,成功在列车运行时速350km/h的条件下,实时识别出转向架轴承的早期磨损——传统方法需列车停运后人工检查,而中车的数字孪生通过振动数据的动态聚类,在磨损初期即发出预警,避免了可能的车轴断裂事故。
“工业场景不需要‘完美’的算法,但需要‘可靠’的算法,”中车数字孪生项目总工程师王工说,“我们的优化方向很简单:让算法在数据脏、计算资源有限、时间要求苛刻的条件下,依然能给出可用的结果。”
聚类算法的“隐形”价值:数据治理与知识沉淀
除了直接用于数字孪生建模,聚类算法在工业数据治理中也发挥着“隐形”但关键的作用,2026年,宝钢股份在上海宝山基地的“工业数据中台”项目中,利用聚类算法实现了设备数据的自动化分类与标注,为数字孪生提供了高质量的“原料”。
宝钢的数据中台需整合来自炼铁、炼钢、轧钢等20余个工序的10万余台设备的数据,传统方法依赖人工标注,效率低且易出错,工程师们采用基于层次聚类(Hierarchical Clustering)的自动化标注系统:首先对设备数据进行初步聚类,识别出相似设备组;随后在每组内应用关联规则挖掘,自动生成数据标签(如“高炉风口温度”“连铸机拉速”);最后通过少量人工校验,完成标签修正,2026年上线后,该系统将数据标注效率提升20倍,标注准确率从75%提高至98%,为后续数字孪生建模节省了60%的数据准备时间。
“聚类算法帮我们解决了工业数据的‘最后一公里’问题,”宝钢数据中台项目负责人陈总说,“当数据有了清晰的‘身份’后,数字孪生才能真正‘活’起来。” 本月绿色能源与绿色沙漠治理及在线教育热度持续攀升,相关应用不断深化
聚类算法与工业元宇宙的融合
展望2026年之后的工业发展,数字孪生正与工业元宇宙深度融合——虚拟工厂不仅需要实时映射物理系统的状态,还需支持人机协作、远程运维等新场景,在这一趋势下,聚类算法的角色将进一步升级:从单纯的数据处理工具,演变为连接物理世界与虚拟世界的“语义桥梁”。
在2026年11月举办的汉诺威工业展上,西门子展示了一项新技术:通过聚类算法对设备操作日志进行语义分析,自动生成虚拟工厂中的“操作指南”——当新手工人在虚拟环境中练习设备操作时,系统会根据其操作数据的聚类特征,实时推荐最优操作路径,这一