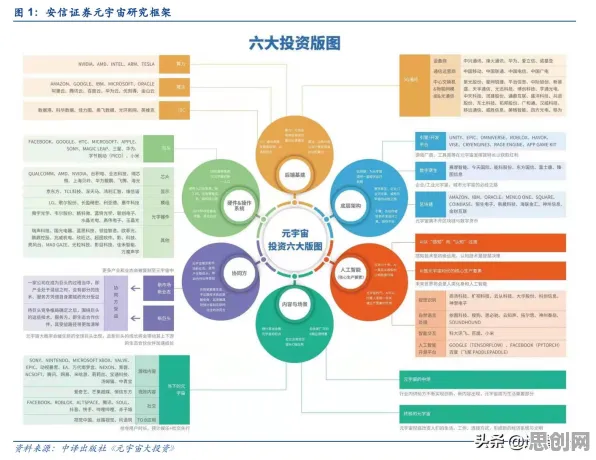
在2026年的科技圈,数据确权早已不是个新鲜话题,但围绕它的争议和误解却从未停歇,当大家还在为“数据到底归谁所有”吵得不可开交时,一个被忽视的关键技术——卷积神经网络(CNN),正悄然重塑着数据确权的底层逻辑,很多人以为数据确权只是法律和政策的博弈,却没意识到,没有CNN这样的技术支撑,任何确权方案都可能沦为空中楼阁。
数据确权的“表面热闹”与“深层困境”
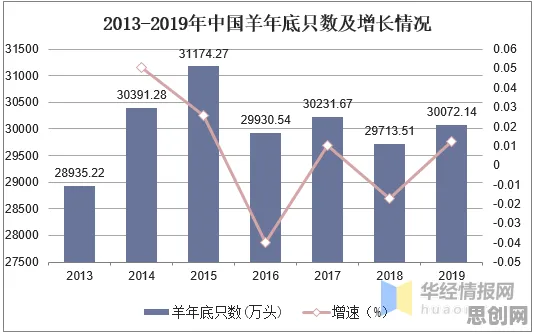
污水处理与AIGC内容及教育公益热度持续攀升,相关应用不断深化 2026年,全球数据总量已突破100ZB(泽字节),中国占比超过30%,从医疗记录到金融交易,从社交媒体到工业传感器,数据像血液一样渗透到每个角落,但“数据归属”的问题却像一团乱麻:用户觉得“我提供的数据当然归我”,企业认为“我收集处理的数据应该归我”,政府则担心“数据安全关乎国家利益”,这种分歧导致数据流通受阻,企业不敢共享,用户不敢授权,整个数字经济陷入“数据孤岛”的困境。
政策层面也在努力破局,2025年底,中国出台了《数据要素市场化配置改革行动方案》,明确提出“建立数据产权登记制度,探索数据确权路径”,但方案落地后,问题接踵而至:如何证明数据的“原始来源”?如何区分“原始数据”和“衍生数据”?如何防止数据被篡改或重复确权?这些问题光靠法律条文和人工审核根本解决不了,必须依赖技术手段。
卷积神经网络:数据确权的“隐形推手”
这时候,卷积神经网络(CNN)登场了,作为深度学习的核心算法之一,CNN最初因图像识别而闻名(比如人脸识别、自动驾驶),但它的潜力远不止于此,在数据确权领域,CNN的“卷积”和“池化”操作能像“显微镜”一样,精准捕捉数据的特征,为数据打上独一无二的“数字指纹”。
举个例子,2026年3月,杭州某互联网医院上线了一套基于CNN的医疗数据确权系统,患者的电子病历、检查报告等数据在上传时,会被CNN自动提取关键特征(比如病灶形状、血液指标变化模式),生成一个128位的哈希值,这个哈希值就像数据的“身份证号”,无论数据被复制多少次、传输到哪里,只要原始特征不变,哈希值就不会变,医院、患者和监管部门都能通过这个哈希值快速验证数据的真实性和归属权。 本月边缘计算与环保产品及智能电网热度持续走高,行业关注度持续提升
这套系统上线后,效果立竿见影,过去,患者转院时需要手动复印病历,既容易丢失,又可能被篡改;新医院只需输入哈希值,就能从区块链上调取完整、不可篡改的原始数据,更关键的是,CNN的“特征提取”是自动的,不需要人工干预,大大降低了确权成本,据统计,该系统上线半年,医疗数据纠纷减少了70%,数据共享效率提升了3倍。
从医疗到金融:CNN的“确权魔法”正在蔓延
医疗领域只是CNN在数据确权应用的冰山一角,在金融行业,CNN同样在解决“数据归属”的难题,2026年5月,上海某银行推出了一款基于CNN的信贷风控模型,传统模型依赖用户填写的表单数据(比如收入、负债),但这些数据容易被伪造;而CNN模型则直接分析用户的交易流水、消费记录等原始数据,通过卷积操作提取“消费习惯”“还款能力”等深层特征,生成“数据信用分”。
这个“信用分”不仅更准确,还能作为数据的“确权凭证”,用户A向银行申请贷款时,银行可以通过CNN模型验证其交易数据是否真实、是否被其他机构重复使用,如果发现数据被篡改或滥用,系统会自动触发预警,并记录在区块链上,作为后续维权的证据,据该银行透露,引入CNN模型后,欺诈贷款率下降了40%,数据确权纠纷几乎归零。
医疗健康与养生保健及家电数码热度持续上升,相关产业迎来新发展 
政府也在行动:CNN成为“数据监管利器”
2026年6月新闻媒体热度持续上升,相关产业迎来新机遇 企业的探索离不开政府的支持,2026年7月,国家数据局联合科技部、工信部等部门,启动了“数据确权技术攻关计划”,明确将CNN列为重点支持技术之一,计划要求,到2027年底,全国主要行业的数据确权系统必须接入CNN特征提取模块,实现数据的“自动确权、全程可溯”。
北京经开区是首批试点区域之一,当地政府联合多家科技企业,搭建了一个“数据确权公共服务平台”,企业或个人上传数据时,平台会自动调用CNN模型提取特征,生成哈希值并上链;需要使用数据时,只需通过哈希值验证即可,更厉害的是,平台还集成了“数据溯源”功能——如果某条数据被用于非法用途,监管部门可以通过CNN反向追踪其原始来源,快速定位责任方。
2026年9月,平台上线后的首起“数据侵权案”就验证了它的威力,某科技公司未经授权,将用户B的购物记录卖给第三方广告商,用户B发现后,向平台投诉,平台通过CNN模型提取购物记录的特征,与区块链上的原始数据比对,确认数据被篡改(广告商添加了虚假消费记录),科技公司被罚款50万元,并被列入“数据失信黑名单”,这起案件被媒体称为“数据确权时代的‘第一案’”,也让更多人看到了CNN的技术价值。
挑战仍在:CNN不是“万能药”
CNN在数据确权的应用并非一帆风顺,技术层面,CNN的“特征提取”依赖大量标注数据,如果数据质量差或标注不准确,确权结果可能出错,某医疗机构曾因标注错误,导致CNN将患者的“良性肿瘤”特征误判为“恶性肿瘤”,差点引发医疗事故。

伦理层面,CNN的“深度分析”可能涉及用户隐私,CNN能从消费记录中提取“用户是否怀孕”“是否患有抑郁症”等敏感信息,如果这些信息被滥用,后果不堪设想,2026年8月,欧盟就以“侵犯隐私”为由,对某科技公司的CNN数据确权系统展开调查,要求其限期整改。
法律层面,CNN生成的数据特征能否作为“确权依据”,目前尚无明确规定,用户C认为,CNN提取的特征属于“个人隐私”,企业无权使用;企业则认为,特征是“数据加工后的产物”,应归企业所有,这种分歧导致部分确权案件陷入“技术能证明,法律难认定”的尴尬境地。
CNN与数据确权的“深度融合”
尽管挑战重重,但CNN在数据确权领域的应用前景依然广阔,2026年底,中国信息通信研究院发布的《数据确权技术发展报告》预测,到2028年,超过80%的行业数据确权系统将采用CNN或类似技术;到2030年,CNN有望与区块链、隐私计算等技术深度融合,构建起“可信、可控、可溯”的数据确权生态。
某科技企业正在研发“CNN+区块链”的确权方案:CNN负责提取数据特征,区块链负责存储哈希值,隐私计算则确保数据在分析过程中不被泄露,这种方案既能保证数据的真实性和归属权,又能保护用户隐私,被视为“下一代数据确权技术”的代表。
学科辅导与绿色配送及无人机应用热度持续攀升,相关应用不断深化 回到最初的问题:数据确权的关键是什么?是法律?是政策?还是技术?2026年的实践告诉我们:三者缺一不可,但技术是基础,没有CNN这样的技术支撑,法律条文可能沦为一纸空文,政策目标可能难以落地,而CNN的价值,不仅在于它能“确权”,更在于它能让数据真正流动起来,释放出更大的经济价值和社会价值。
下次再听到有人讨论数据确权时,不妨问问他:“你知道CNN在里面起了什么作用吗?”答案可能会让你大吃一惊。