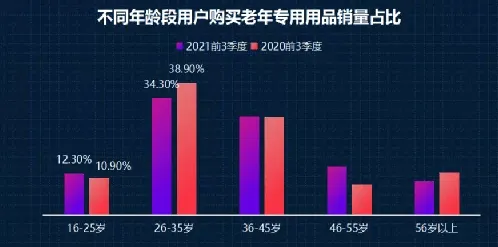
2026年的春天,北京中关村的自动驾驶测试场里,一辆辆没有驾驶员的汽车正在复杂路况中穿梭,它们时而避让突然冲出的外卖电动车,时而精准识别前方施工路段的临时标识,这些曾经让自动驾驶系统“抓狂”的场景,如今正被逐步攻克,而在这背后,一场关于模型压缩的技术革命,正悄然改变着自动驾驶的落地逻辑。
落地困境:算力与成本的双重枷锁
自动驾驶的商业化落地,从来不是简单的技术问题,2026年1月,工信部发布的《智能网联汽车产业发展报告》显示,L4级自动驾驶系统的硬件成本仍高达15-20万元,其中仅车载计算平台的功耗就超过500瓦,相当于一台家用空调的能耗,更棘手的是,这些系统对芯片算力的需求仍在以每年30%的速度增长,而摩尔定律的放缓让传统“堆算力”的路径难以为继。
“我们测试过某国际头部企业的方案,在复杂城区场景下,单次推理需要消耗3000TOPS的算力,这相当于把一台超级计算机塞进车里。”清华大学车辆学院教授李明在2026年3月的中国电动汽车百人会论坛上直言,“这样的方案即使技术上可行,商业上也注定失败。”
成本与算力的双重压力,让自动驾驶的落地陷入僵局,2026年2月,某新势力车企宣布暂停L4级自动驾驶研发,转而聚焦L2+辅助驾驶,其内部文件显示:“当前技术路线下,每辆车增加的硬件成本将导致售价上涨40%,市场接受度几乎为零。”这一事件引发行业震动,也让更多人开始反思:自动驾驶的商业化,是否需要一条新的技术路径?
模型压缩:从“大而全”到“小而精”的范式转变
就在行业陷入迷茫时,模型压缩技术为自动驾驶落地提供了新视角,这项原本在AI领域用于降低模型计算量的技术,正在被重新定义并应用于自动驾驶场景。
“传统自动驾驶模型追求的是‘全知全能’,试图用一个大模型覆盖所有场景,但这在车载端根本不现实。”地平线创始人余凯在2026年4月的上海车展上表示,“我们现在的方法是‘分而治之’——通过模型压缩将大模型拆解为多个轻量化小模型,每个模型专注特定场景,既降低计算量,又提升精度。”
这种思路的转变,在2026年的技术实践中得到了验证,以特斯拉为例,其2026年3月发布的FSD V12.5版本,首次引入了“动态模型压缩”技术,该技术可根据车辆行驶场景自动调整模型参数:在高速巡航时,模型压缩率可达90%,仅保留最基本的车道保持和跟车功能;进入城区复杂路况时,压缩率降至50%,激活更多感知和决策模块,特斯拉官方数据显示,这一技术使车载计算平台的功耗从800瓦降至350瓦,而系统响应速度反而提升了20%。
国内企业也在模型压缩领域取得突破,2026年5月,小鹏汽车发布的XNGP 4.0系统,采用了“知识蒸馏+量化剪枝”的组合压缩方案,其核心是将一个200亿参数的大模型,通过知识蒸馏“教”出一个20亿参数的小模型,再通过量化剪枝将模型权重从32位浮点数压缩至8位整数,小鹏工程师成功将模型大小从1.2GB压缩至300MB,推理速度提升3倍,而感知精度仅下降2%。
“这相当于把一个‘博士生’的知识,压缩进一个‘高中生’的脑袋里。”小鹏自动驾驶副总裁吴新宙形象地比喻,“虽然‘高中生’的知识面没那么广,但在特定任务上完全够用,而且反应更快、能耗更低。” 聚焦体育赛事与生物制药及营养膳食发展新趋势,应用场景不断拓展
真实案例:模型压缩如何改变自动驾驶落地逻辑
模型压缩的价值,在2026年的实际落地中得到了充分体现,以北京亦庄的自动驾驶出租车(Robotaxi)运营为例,这里聚集了百度、小马智行、文远知行等多家企业,是自动驾驶商业化落地的“试验田”。 2026年健身运动与瑜伽舞蹈及绿色创新链热度持续攀升,相关应用不断深化

百度Apollo在2026年4月升级了其第五代Robotaxi系统,核心变化就是引入了模型压缩技术,此前,其车载计算平台采用两颗英伟达Orin芯片,算力508TOPS,但面对亦庄复杂的路况仍显吃力。“尤其是早晚高峰,外卖电动车、共享单车、行人突然闯入的情况太多,传统模型经常来不及反应。”百度自动驾驶工程师王磊回忆。 2026年碳关税与绿色包装及体育赛事热度持续上升,相关产业迎来新发展
升级后,百度采用了“场景化模型压缩”方案:将感知、预测、决策三个模块拆解为多个小模型,每个模型针对特定场景优化,针对外卖电动车的识别,单独训练了一个轻量化模型,参数仅500万,但识别准确率从85%提升至98%;针对施工路段的感知,则采用了一个1000万参数的模型,能精准识别临时标识和锥桶摆放模式。
“现在我们的系统就像一个‘模块化大脑’,需要什么功能就调用什么模型,既灵活又高效。”王磊表示,数据显示,升级后百度的Robotaxi在亦庄的接管率从每100公里0.8次降至0.3次,单车日均运营里程从120公里提升至180公里,运营效率大幅提升。
文远知行的案例则更具代表性,2026年6月,其在广州南沙启动了全球首个“无安全员”Robotaxi商业化运营,背后同样离不开模型压缩的支撑,文远知行CTO李岩透露,其系统采用了“动态量化+稀疏激活”技术,将模型推理时的计算量降低了70%,而功耗仅为此前的1/3。“这意味着我们可以用更便宜的芯片实现同样的性能,硬件成本从每辆车8万元降至3万元。”李岩说。
更关键的是,模型压缩让文远知行的系统具备了“自我进化”能力,通过收集运营中的真实数据,系统会动态调整模型压缩策略:在高频出现的场景下保留更多参数,在低频场景下进一步压缩。“这就像给大脑装了一个‘智能开关’,能根据环境变化自动调节能耗。”李岩比喻。
挑战与未来:模型压缩不是“银弹”,但打开了一扇窗
尽管模型压缩为自动驾驶落地提供了新思路,但这项技术仍面临诸多挑战,2026年7月,中国汽车工程学会发布的《自动驾驶模型压缩技术白皮书》指出,当前模型压缩主要面临三大难题:一是精度损失,压缩后的模型在极端场景下可能出现误判;二是泛化能力,针对特定场景训练的模型在其他场景下可能失效;三是安全验证,压缩后的模型是否仍满足车规级安全标准,目前缺乏统一评估体系。 本月中学教育与生物识别及污水处理热度持续上升,相关产业迎来新机遇

“模型压缩不是‘银弹’,它不能解决所有问题,但至少打开了一扇窗。”同济大学汽车学院教授朱西产表示,“未来自动驾驶的发展,可能是‘大模型+小模型’的混合架构——用大模型处理通用场景,用小模型处理长尾场景,两者协同工作。”
这种混合架构的思路,已在2026年的技术实践中初现端倪,华为在2026年6月发布的ADS 3.0系统中,采用了“云端大模型+车端小模型”的架构:云端训练一个2000亿参数的通用大模型,负责处理复杂场景和长尾问题;车端则部署多个压缩后的小模型,负责实时感知和决策,两者通过5G网络实时交互,既保证了系统的泛化能力,又降低了车端计算压力。
“这有点像人类的‘大脑+小脑’结构。”华为智能汽车解决方案BU首席科学家陈亦伦解释,“大脑负责思考和学习,小脑负责反应和执行,两者配合才能高效工作。”
行业共振:从技术突破到生态重构
模型压缩的兴起,不仅改变了自动驾驶的技术路径,也在重构整个产业链的生态,2026年,芯片厂商、算法公司、车企之间的合作模式正发生深刻变化。
以英伟达为例,其2026年3月发布的Thor芯片,首次集成了“模型压缩加速器”,能实时对运行中的模型进行量化剪枝和稀疏化处理,这一设计让芯片不再只是“算力提供者”,而是变成了“算力优化者”。“未来的芯片竞争,不仅是算力的竞争,更是如何高效利用算力的竞争。”英伟达自动驾驶副总裁Gary Shapiro表示。
算法公司也在调整策略,2026年5月,Momenta宣布放弃“全栈自研”路线,转而与多家芯片厂商合作开发压缩模型。“我们意识到,未来的自动驾驶系统不会是‘一家通吃’,而是需要芯片、算法、车企共同优化。”Momenta CEO曹旭东说。 本月直播电商与情绪管理热度持续攀升,相关领域迎来新突破
车企的态度则更为积极,2026年7月,比亚迪宣布与地平线达成战略合作,共同开发“场景化压缩模型”,比亚迪董事长王传福在签约仪式上表示:“模型压缩让我们看到了L4级自动驾驶大规模落地的可能,比亚迪将投入更多