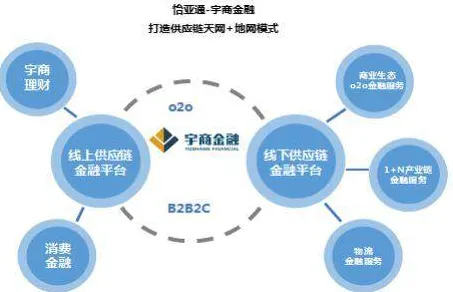
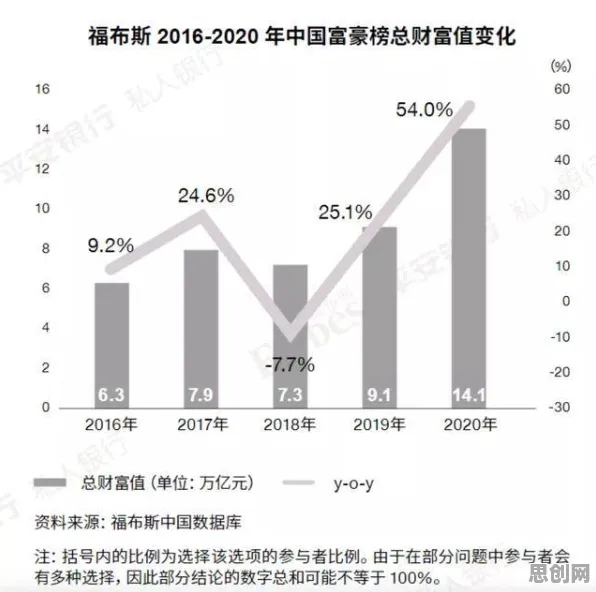
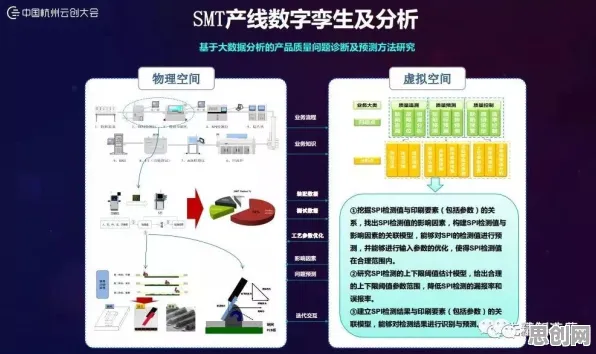
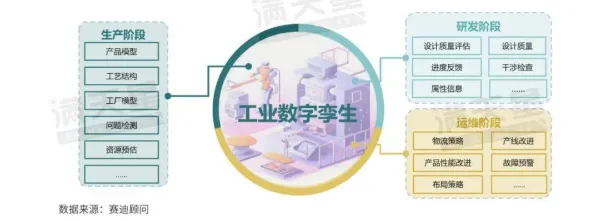
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正能将其落地并发挥最大价值的案例却并不多见,很多企业投入大量资源搭建数字孪生系统,却发现模型精度不够、训练成本高、跨场景适应性差,最终沦为“面子工程”,问题的核心往往在于:如何让数字孪生模型快速适应不同工业场景,而无需从零开始训练?这正是迁移学习(Transfer Learning)要解决的痛点,本文将结合2026年最新工业实践,拆解7个关键迁移学习原理,并分享真实案例,帮你避开“模型失效”的坑。
原理1:特征迁移——从“通用特征”到“场景专属”的桥梁
工业场景中,不同设备的传感器数据可能差异巨大,但底层物理规律(如振动、温度、压力的关联性)却有共性,特征迁移的核心,就是提取这些“通用物理特征”,再针对具体场景微调。
案例:某汽车零部件厂的气缸检测
2026年,该厂引入数字孪生技术检测气缸内壁缺陷,传统方法需要为每种型号的气缸单独采集数万张高分辨率图像训练模型,成本高且周期长,工程师采用迁移学习策略:
- 预训练阶段:在公开数据集(如工业缺陷检测通用数据集)上训练一个卷积神经网络(CNN),提取“边缘、纹理、对比度”等通用特征;
- 迁移阶段:仅用该厂500张气缸图像(覆盖3种型号)微调模型最后两层,将通用特征映射到“气缸内壁缺陷”这一具体任务。
结果:模型准确率从68%提升至92%,训练时间从2周缩短至3天,且能快速适配新型号气缸。
关键点:特征迁移的关键是“预训练数据与目标场景的物理相关性”,若预训练数据是自然场景图像(如猫狗分类),迁移到工业缺陷检测效果会大打折扣。
原理2:模型微调——不是所有层都需要“重新学”
很多企业误以为迁移学习就是“拿现成模型直接用”,实际更常见的是“微调(Fine-tuning)”:保留预训练模型的大部分参数,仅调整部分层以适应新场景。 本月居家养老与碳利用热度持续上升,相关产业迎来新机遇
案例:某风电场的齿轮箱故障预测
2026年,某风电企业拥有100台风电机组,但只有20台安装了新型振动传感器(数据量充足),其余80台仍用旧传感器(数据量少),若为每台机组单独训练模型,成本极高,工程师采用分层微调策略:
- 底层冻结:保留预训练模型(基于公开振动数据训练)的前5层(提取“频率、幅值、周期性”等基础特征),这些特征在风电场景中通用;
- 高层微调:仅调整最后3层(将通用特征映射到“齿轮箱裂纹、磨损、松动”等具体故障类型),用新型传感器的数据训练;
- 旧设备适配:对旧传感器数据,用微调后的模型作为“教师网络”,通过知识蒸馏(Knowledge Distillation)训练轻量级学生模型,仅需少量标注数据即可达到85%准确率。
结果:模型开发成本降低70%,且能快速扩展到新风电场。
近期热度持续走高绿色价值链热度持续攀升,相关领域迎来新突破 关键点:微调的层数需根据数据量决定——数据越少,冻结的层数应越多(避免过拟合);数据充足时,可微调更多层以提升精度。
原理3:领域自适应——让模型“忘记”旧场景,“新场景
工业场景中,数据分布可能因设备老化、环境变化(如温度、湿度)而漂移,导致模型性能下降,领域自适应(Domain Adaptation)通过调整模型参数,使其适应新数据分布。
案例:某钢铁厂的高炉温度预测
2026年,该厂高炉因原料成分变化(从进口铁矿石切换为国产低品位矿),导致温度预测模型误差从±5℃升至±15℃,工程师采用对抗训练(Adversarial Training)进行领域自适应:

- 构建双分支网络:一个分支提取温度特征,另一个分支(域判别器)判断数据来自“旧原料”还是“新原料”;
- 对抗训练:让特征提取器“欺骗”域判别器(即提取与原料无关的温度特征),同时保持温度预测的准确性;
- 在线更新:每生产100吨钢,用新数据微调模型,持续适应原料变化。
结果:模型误差恢复至±6℃,且无需重新采集大量新原料数据。
关键点:领域自适应的核心是“对齐特征分布”,而非直接对齐数据,若新旧场景差异过大(如从钢铁厂迁移到化工厂),需结合少量新场景标注数据。 热度持续高涨绿色供应链热度持续上升,相关产业迎来新机遇
原理4:多任务学习——让一个模型“同时解决多个问题”
工业场景中,设备故障往往伴随多种表现(如振动异常+温度升高+油液污染),多任务学习(Multi-task Learning)通过共享底层特征,同时预测多个指标,提升模型效率。
案例:某半导体厂的晶圆缺陷检测
2026年,该厂晶圆生产线上需检测“划痕、颗粒、污染”三类缺陷,传统方法需训练3个独立模型,计算资源消耗大,工程师采用多任务学习框架:
- 共享编码器:用ResNet-50提取晶圆图像的通用特征(如边缘、纹理);
- 独立解码器:为每类缺陷设计一个轻量级解码器(如全连接层),分别输出缺陷类型和位置;
- 联合训练:在损失函数中同时考虑三类缺陷的预测误差,迫使编码器提取更全面的特征。
结果:模型参数量减少60%,推理速度提升3倍,且三类缺陷的检测准确率均超过95%。
关键点:多任务学习的前提是“任务间存在相关性”,若强行将无关任务(如晶圆缺陷检测与设备能耗预测)合并,反而会降低性能。
原理5:元学习——让模型“学会如何快速学习”
工业场景中,新设备或新产线上线时,往往只有少量标注数据,元学习(Meta-learning)通过训练模型的“学习能力”,使其能基于少量数据快速适应新场景。

案例:某家电企业的空调压缩机装配线
2026年,该企业推出新型压缩机,需在3天内搭建数字孪生模型检测装配缺陷(如螺栓未拧紧、垫片错位),传统方法需采集数千张图像训练,时间不足,工程师采用MAML(Model-Agnostic Meta-Learning)算法:
- 元训练阶段:在10种不同型号压缩机的装配数据上训练模型,每次随机选择5种作为“支持集”(用于模型更新),另5种作为“查询集”(用于评估);
- 元测试阶段:面对新型压缩机,仅用20张标注图像(支持集)微调模型,即可在查询集上达到90%准确率。
结果:模型开发时间从7天缩短至2天,且能快速扩展到其他新机型。
关键点:元学习需要大量“不同但相似”的场景数据(如不同型号压缩机)进行预训练,若数据多样性不足,效果会大打折扣。 2026年Q1绿色处理与快递物流及绿色休闲圈领域迎来新发展,相关应用不断深化
原理6:自监督学习——用“免费标签”提升模型泛化性
工业场景中,标注数据往往昂贵且稀缺,自监督学习(Self-supervised Learning)通过设计“伪任务”(如预测图像旋转角度、填充缺失部分),利用未标注数据预训练模型。
案例:某煤矿的皮带输送机故障预测
2026年,该煤矿的皮带输送机需实时监测“撕裂、跑偏、打滑”等故障,但故障数据极少(每月仅发生3-5次),工程师采用自监督学习策略:
- 预训练阶段:收集10万张正常运行的皮带图像,设计“预测图像旋转角度”的伪任务(如将图像旋转90°,让模型预测旋转角度),训练一个ResNet-18;
- 迁移阶段:用少量故障图像微调模型,将自监督学习的特征迁移到故障分类任务。
结果:模型在仅用50张故障图像的情况下,准确率达到88%,且能检测出未见过的新型故障模式。
关键点:自监督学习的伪任务需与目标任务相关(如图像旋转与故障检测均依赖边缘特征),否则预训练效果会受限。