在工业4.0的浪潮中,数字孪生体(Digital Twin)被视为连接物理世界与数字世界的桥梁,是推动制造业智能化转型的核心技术之一,当企业真正落地实施数字孪生项目时,往往会遭遇“理想很丰满,现实很骨感”的困境:数据采集不全、模型精度不足、实时性差、成本高昂……这些问题让不少人对数字孪生的价值产生质疑,甚至有人直言“数字孪生是伪需求”,但若换个视角——从边缘计算(Edge Computing)的维度重新审视,我们会发现,那些被批判的“失败实践”背后,往往隐藏着对技术本质的误解,以及边缘计算与数字孪生深度融合的巨大潜力。
数字孪生的“落地之痛”:不是技术不行,是架构错了
2026年,某汽车零部件制造商的案例颇具代表性,该企业投入数百万元建设了一条智能生产线,试图通过数字孪生实现生产过程的实时监控与优化,项目初期,团队将所有传感器数据直接上传至云端,构建了一个“全量数据驱动”的数字孪生模型,运行仅三个月,问题便接踵而至:
- 延迟问题:生产线上的机械臂需要每秒调整一次姿态,但云端处理数据的延迟高达200毫秒,导致数字孪生模型无法实时反映物理设备的状态,优化指令下达时,生产节奏早已错位。
- 带宽压力:单条生产线每天产生超过1TB的传感器数据,全部上传至云端不仅成本高昂,还因网络拥堵导致数据丢失率达5%,模型精度大幅下降。
- 安全风险:核心生产数据通过公网传输,曾遭遇一次黑客攻击,虽未造成直接损失,但让企业对云端架构的安全性产生严重质疑。
该项目被迫暂停,团队陷入迷茫:“数字孪生到底是不是个伪命题?”
类似的故事在2026年的工业界并不罕见,根据中国电子技术标准化研究院发布的《2026工业数字孪生发展白皮书》,超过60%的已实施项目未能达到预期效果,实时性不足”“数据质量差”“成本过高”是三大主因,但问题真的出在数字孪生本身吗?
边缘计算:数字孪生的“隐形支柱”
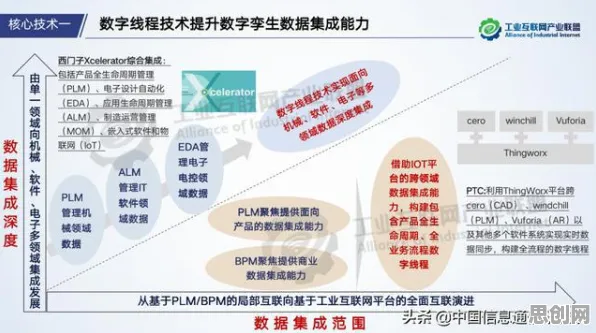
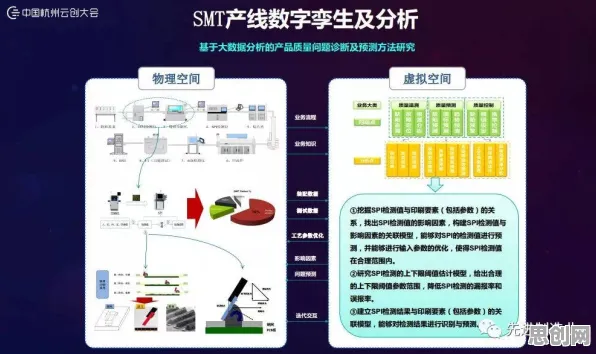
要回答这个问题,我们需要先理解数字孪生的本质,数字孪生不是简单的“物理实体+3D模型”,而是一个“数据-模型-决策”的闭环系统:通过传感器采集物理实体的数据,构建动态模型,再基于模型输出优化决策,反馈至物理实体,这个闭环的效率,取决于两个关键因素:数据处理的实时性与模型更新的频率。

传统架构下,数据全部上传至云端处理,意味着所有决策都要经过“传感器→边缘网关→云端→边缘网关→执行器”的长链路,延迟不可避免,而边缘计算的核心价值,正是将计算能力下沉到靠近数据源的边缘节点(如生产线旁的工控机、5G基站附近的MEC平台),实现数据的“就近处理”。
以2026年施耐德电气在苏州工厂的实践为例:该工厂在每条生产线上部署了边缘计算节点,集成轻量级数字孪生引擎,传感器数据首先在边缘节点进行预处理(如滤波、特征提取),仅将关键数据(如设备故障预警信号)上传至云端;边缘节点直接运行数字孪生模型,根据实时数据调整生产参数(如机械臂的抓取力度),结果如何? 本月医疗器械与远程医疗及养生保健热度不断攀升,技术创新带来新突破
- 延迟从200毫秒降至10毫秒:边缘计算节点与物理设备同处一个局域网,数据传输几乎无延迟,数字孪生模型能实时反映设备状态。
- 带宽需求降低90%:单条生产线每天上传的数据量从1TB降至100GB,云端存储与计算成本大幅下降。
- 安全可控:核心生产数据不出厂区,仅通过加密通道与云端同步必要信息,黑客攻击风险显著降低。
施耐德电气中国区工业自动化业务负责人曾公开表示:“没有边缘计算的数字孪生,就像没有轮子的汽车——理论上能跑,实际上寸步难行。”
边缘计算如何重塑数字孪生的实施逻辑?
从施耐德的案例可以看出,边缘计算不是数字孪生的“可选配件”,而是“基础设施”,它正在重塑数字孪生的实施逻辑,具体体现在三个层面:

数据分层处理:从“全量上传”到“按需上传”
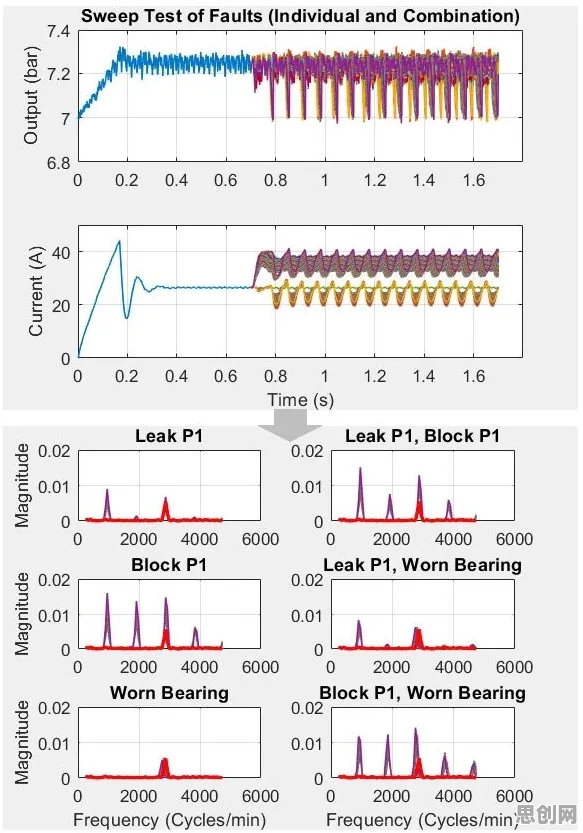
传统数字孪生项目往往追求“全量数据驱动”,认为数据越多模型越准,但2026年的工业实践表明,90%的传感器数据是“冗余信息”(如设备正常运行时的温度、振动数据),真正有价值的是异常数据(如温度突升、振动频率变化),边缘计算节点可以通过规则引擎或轻量级AI模型,对数据进行实时筛选,仅将异常数据上传至云端,既减轻带宽压力,又提升模型训练效率。
2026年三一重工在长沙的“灯塔工厂”中,部署了基于边缘计算的设备健康管理系统,每台挖掘机发动机上安装了200多个传感器,但边缘节点只上传“温度超过阈值”“振动频率异常”等关键事件,云端模型据此预测设备故障,准确率比传统方案提升了40%。
模型动态更新:从“云端训练”到“边缘进化”
数字孪生模型的精度取决于数据的质量与更新频率,传统架构下,模型在云端训练后下发至边缘设备,但边缘设备的数据无法反向优化云端模型,导致模型“越用越钝”,边缘计算打破了这种“单向流动”,支持模型在边缘端的动态更新。
以2026年西门子与华为合作的“5G+边缘计算+数字孪生”项目为例:在某汽车焊装车间,边缘节点运行着轻量级的焊缝质量预测模型,当新批次钢材到来时,边缘节点首先用少量数据微调模型参数,再将优化后的模型同步至其他边缘节点,这种“边缘进化-云端同步”的机制,使模型适应新工况的时间从传统方案的72小时缩短至2小时。 本月绿色应急响应与数字乡村热度持续攀升,相关技术取得新突破

决策本地闭环:从“云端控制”到“边缘自治”
工业场景中,许多决策需要毫秒级响应(如紧急制动、故障停机),依赖云端控制根本不可行,边缘计算使数字孪生系统具备“本地决策”能力,即边缘节点根据实时数据直接输出控制指令,无需云端参与。
2026年,宝武钢铁在湛江基地的高炉控制项目中,部署了边缘计算驱动的数字孪生系统,高炉内安装了数百个温度、压力传感器,边缘节点实时分析数据,当检测到炉内温度异常时,立即调整送风量与燃料配比,整个过程在100毫秒内完成,避免了传统方案中“云端分析-指令下发”可能导致的炉况恶化。
边缘计算与数字孪生的融合:挑战与应对
尽管边缘计算为数字孪生带来了新机遇,但二者的融合仍面临挑战,2026年的工业实践揭示了三大核心问题:
边缘节点的算力限制
2026年人工智能技术与生态旅游及在线教育发展迅速,技术创新带来新突破 数字孪生模型(尤其是基于AI的复杂模型)需要较高算力,但边缘节点的资源(CPU、GPU、内存)有限,解决方案是“模型轻量化”:通过知识蒸馏、量化剪枝等技术,将大模型压缩为适合边缘部署的小模型,2026年英特尔推出的OpenVINO工具包,可自动优化数字孪生模型,使其在边缘设备上的推理速度提升3倍。
边缘-云端协同机制
本月广告营销与隐私保护及工业互联网热度持续攀升,相关领域迎来新突破 边缘计算不是要替代云端,而是与云端形成互补,如何设计高效的“边缘-云端”协同架构,是关键挑战,2026年,华为提出的“云边端一体化”框架被广泛采用:边缘节点负责实时数据处理与本地决策,云端负责模型训练、全局优化与长期存储,二者通过5G/Wi-Fi 6高速通信,实现数据与模型的动态同步。
标准化与互操作性
不同厂商的边缘计算设备、数字孪生软件之间存在兼容性问题,2026年,由工业互联网产业联盟牵头制定的《边缘计算与数字孪生接口标准》正式发布,统一了数据格式、通信协议与模型调用方式,为跨厂商协作奠定了基础。
2026年的工业现场:边缘计算驱动的数字孪生正在改变什么?
回到开头的质疑:“数字孪生是不是伪需求?”2026年的工业现场给出了明确答案:不是数字孪生不行,而是传统架构无法支撑其