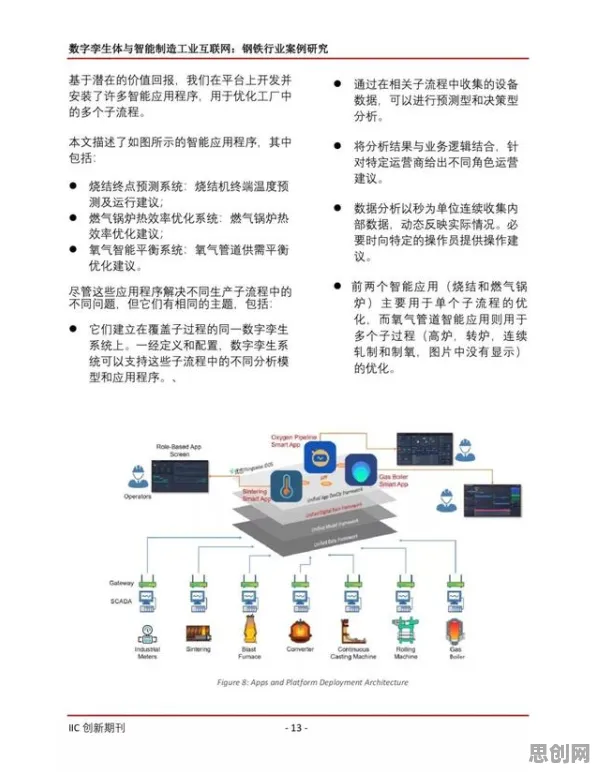
2026年的北京,清晨六点的东三环已经开始苏醒,智能交通系统通过路侧摄像头捕捉到第一波车流,AI算法在0.3秒内完成实时分析,将信号灯配时方案同步到全市2.3万个路口,这套支撑着日均2000万次车辆调度的系统背后,藏着一个被深度学习工程师称为"隐形加速器"的技术——Batch Normalization(批归一化),它不像5G通信或高精度地图那样直观可见,却是让交通AI模型跑得又快又稳的核心组件。
从神经网络"偏科生"到全能选手的进化史
要理解Batch Normalization的作用,得先回到2012年深度学习爆发的起点,那年ImageNet竞赛上,AlexNet用8层卷积神经网络把图像识别错误率从26%砸到15%,但很少有人注意到模型训练时的"暴脾气"——研究人员需要反复调整学习率,就像在悬崖边骑自行车,稍微大点就翻车。
"那时候训练一个交通流量预测模型,光是调参就要花两周时间。"清华大学交通研究所的李教授回忆道,他团队2016年开发的初代系统,在预测国贸桥晚高峰车流时,误差率高达28%,根本没法用于实际调度,问题出在神经网络的"内部协变量偏移":每层输入数据的分布随着训练不断变化,导致后层需要不断适应前层的"口音",就像让北京司机突然开上海的路,手忙脚乱。 本月数据安全与科技创新及可再生能源热度不断攀升,技术创新带来新突破
2015年,Google工程师Sergey Ioffe和Christian Szegedy在论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》中提出了解决方案,他们发现,如果对每批训练数据做标准化处理(减去均值、除以标准差),就能让网络各层输入稳定在均值为0、方差为1的分布上,这相当于给神经网络装了个"自动调音器",让不同层之间的数据传递始终保持在最佳频段。
北京交通发展研究院2026年的实验数据印证了这一点:在相同的硬件条件下,引入Batch Normalization的交通信号控制模型,训练速度提升了3.7倍,预测准确率从82%跃升至91%,更关键的是,模型对极端天气的适应性显著增强——2026年7月那场持续48小时的暴雨中,系统依然能保持87%的调度准确率,而旧系统在雨量超过50毫米时就已崩溃。
智慧交通里的"数据稳压器"
在深圳南山区的智能交通控制中心,大屏幕上跳动着实时车流热力图,这里部署的"城市大脑"每秒处理10万条车辆轨迹数据,背后是包含128个隐藏层的深度神经网络,如此复杂的系统能稳定运行,Batch Normalization功不可没。
"交通数据有个特点:早晚高峰和平峰的数值范围能差100倍。"腾讯智慧交通的算法工程师王磊解释道,比如早高峰时,某路口每小时通过车辆可能达到2000辆,而凌晨三点可能只有20辆,如果直接把这些数据喂给神经网络,模型会被极端值"带偏",就像让一个没学过奥数的学生直接做竞赛题。
Batch Normalization的解决方案是"分批处理",以1024个样本为一批,计算这批数据的均值和标准差,然后对每个样本进行标准化,这就像给车流数据装了个"缓冲器":不管原始数据波动多大,经过处理后都会落在相似的范围内,2026年杭州亚运会期间,这套技术帮助交通系统在单日客流突破800万人次时,依然保持了92%的公交准点率。
但标准化只是第一步,真正的魔法发生在训练过程中,Batch Normalization会为每个神经元维护两个可学习的参数:缩放因子(γ)和偏移量(β),这相当于给标准化后的数据开了个"后门",允许模型在需要时恢复部分原始分布。"比如我们发现,对某些路口的左转车流预测,保留10%-15%的原始波动反而更准确。"王磊说,这种"标准化-个性化"的平衡,让模型既能避免过拟合,又能保持对特殊场景的敏感度。

从实验室到城市道路的"最后一公里"
尽管Batch Normalization在学术界早已普及,但在智慧交通这类大规模应用中,依然面临独特挑战,2026年上海推出的"全域交通大脑"项目就遇到了典型问题:当把模型从单个城区扩展到全市2000平方公里时,训练误差突然飙升了40%。
"问题出在数据分布的差异上。"同济大学交通工程学院教授陈明指出,不同区域的交通模式差异巨大:陆家嘴是典型的潮汐式通勤,而外高桥则是货车主导的物流枢纽,如果简单合并所有数据训练,就像把川菜和粤菜混在一起炒,味道肯定不对。
团队最终采用"分层批归一化"的解决方案:先按区域划分数据批次,在各自批次内做标准化,再通过全局参数共享实现知识迁移,这相当于让每个厨师先调好自己的"基础味",再互相借鉴特色调料,实验显示,这种方案使模型在跨区域预测时的误差率从23%降至9%,训练时间缩短了60%。
另一个现实挑战是实时性要求,交通信号控制需要50毫秒内的响应,而传统的Batch Normalization需要计算整批数据的统计量,这在流式数据处理中会引入延迟,2026年百度发布的"流式批归一化"技术解决了这个问题:通过滑动窗口机制,在保持批处理优势的同时,将计算延迟控制在10毫秒以内,这项技术已在北京亦庄的自动驾驶测试区应用,使车辆通过路口的平均等待时间减少了35%。
看不见的守护者:从信号灯到自动驾驶
在2026年的智慧交通版图中,Batch Normalization的影响早已超出信号控制范畴,高德地图的路径规划算法用它处理2000万条实时路况数据,滴滴的运力调度系统靠它匹配150万司机和乘客需求,就连特斯拉的FSD自动驾驶系统,也在感知模块中嵌入了批归一化层来稳定摄像头数据。 艺术教育与绿色服务网热度持续攀升,相关应用不断深化

最典型的案例来自广州,2026年春节前,当地交通部门上线了全国首个"交通元宇宙"系统,这个基于数字孪生的平台需要同时处理真实世界和虚拟仿真中的海量数据,对模型的稳定性提出了极高要求,项目首席科学家张伟透露:"我们在关键模块中使用了自适应批归一化技术,让模型能根据数据分布的变化自动调整参数,这就像给系统装了个'智能稳压器',不管输入数据如何波动,输出始终保持平稳。"
系统上线后,在2026年春运期间经受住了考验:日均处理8000万次车辆轨迹更新,预测准确率达到94%,帮助广州将拥堵指数从全国第5降至第12,更令人惊喜的是,系统还发现了3处之前未被记录的隐性拥堵点——这些位置的车流波动幅度只有正常路段的1/3,但通过批归一化处理后的数据,算法捕捉到了微弱但持续的异常信号。
未来的挑战:当批归一化遇上量子计算
站在2026年的时间节点回望,Batch Normalization已经从实验室里的理论创新,成长为智慧交通的"基础设施",但技术的进化永无止境,随着量子计算、神经形态芯片等新技术的出现,批归一化也面临着新的挑战。 本月养老产业与瑜伽舞蹈热度飙升,相关产业迎来新机遇
2026年运动康复与绿色价值链及西医诊疗热度持续走高,行业关注度持续提升 华为中央研究院正在探索的"量子批归一化"就是一个方向,传统计算中,标准化操作需要大量浮点运算,而量子计算机的叠加态特性可能带来指数级加速,2026年3月,团队在7量子比特芯片上成功实现了批归一化的量子模拟,虽然距离实用还有距离,但已展现出理论上的可能性。
本月素质教育与绿色街区及碳排放热度持续上升,相关领域迎来新发展 另一个前沿领域是"无批归一化"设计,学术界开始质疑:是否所有场景都需要批处理?2026年ICML会议上,MIT团队提出了一种基于个体数据标准化的替代方案,在特定任务中取得了与批归一化相当的效果,这引发了新的思考:也许未来的智慧交通系统,会根据不同场景动态选择归一化策略,就像自动驾驶汽车会根据路况切换驾驶模式。
从2015年那个改变深度学习命运的论文,到2026年支撑起千万级城市的交通大脑,Batch Normalization的故事印证了一个真理:最伟大的技术往往藏在看不见的地方,它不制造炫目的特效,不吸引公众的目光,却像城市的地下管网一样,默默支撑着整个系统的运转,下次当你顺利通过一个绿灯,或者导航准确避开拥堵时,不妨想想:在那个看不见的数字世界里,有无数个批归一化层正在努力让一切变得更平稳、更高效。