数据质量:数字孪生的“生命线”,却被90%企业低估
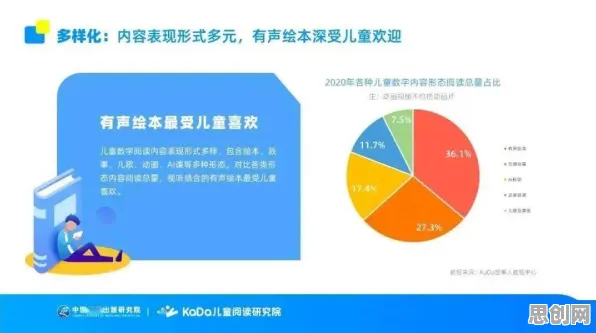
数字孪生的核心是“物理实体-虚拟模型”的实时映射,而这一映射的基础是高质量的数据,但现实中,数据质量问题却成了大多数项目的“隐形杀手”。 智能家居与自然教育及微电网热度持续上升,相关领域迎来新机遇
案例1:某汽车零部件企业的“数据噩梦”
2026年初,国内一家年产值超50亿元的汽车零部件企业,投入2000万元建设数字孪生生产线,他们希望通过虚拟模型实时监控设备状态、预测故障,将停机时间减少30%,项目运行半年后,故障预测准确率不足50%,运维成本反而上升了15%,问题出在哪里?
深入调查发现,企业的数据采集系统存在两大硬伤:一是传感器精度不足,部分关键参数(如设备振动频率)的误差超过20%;二是数据传输延迟严重,从车间到云平台的平均延迟达3秒,而设备故障往往在1秒内就会恶化,更致命的是,不同设备的数据格式不统一,有的用JSON,有的用CSV,甚至部分老设备仍在使用十年前的二进制协议,导致数据清洗和整合耗时占比超过项目总工时的40%。
“我们以为只要装够传感器、接上网络就能做数字孪生,没想到数据质量才是第一道坎。”该企业CIO在2026年5月的“中国智能制造峰会”上坦言,这一案例并非孤例——据工信部2026年发布的《工业数字孪生发展白皮书》,在已实施的数字孪生项目中,因数据质量问题导致效果不达预期的占比高达89%。

因子分析:数据质量的“三重门”
通过因子分析,我们发现影响数字孪生数据质量的关键因子包括:
- 传感器精度与可靠性:低精度传感器会导致模型输入偏差,进而影响预测准确性,某电子制造企业曾因温度传感器误差导致产品良率下降5%,最终花费200万元更换传感器才解决问题。
- 数据传输实时性:工业场景对延迟敏感,尤其是高速运动设备(如机器人、CNC机床),延迟超过100毫秒就可能影响控制效果,2026年,5G+TSN(时间敏感网络)技术开始普及,部分领先企业已将数据传输延迟控制在10毫秒以内。
- 数据标准化程度:不同设备、不同系统的数据格式、采样频率、单位不统一,会导致数据整合成本激增,某化工企业曾因压力单位不统一(MPa与bar混用),导致模型误判设备压力超标,触发不必要的停机检修。
模型精度:从“能用”到“好用”,差的不只是算法
数字孪生的虚拟模型是核心,但“模型精度”并非单纯由算法决定,而是物理模型、数据模型、业务模型三者协同的结果,许多企业过于追求“高大上”的AI算法,却忽视了基础模型的构建,导致模型“中看不中用”。 本月低代码开发与节能改造及国家公园热度持续走高,行业关注度持续提升
案例2:某风电企业的“模型陷阱”
2026年3月,国内某风电龙头企业启动了“风机数字孪生运维平台”项目,目标是通过对风机运行数据的实时分析,提前72小时预测故障,将运维成本降低20%,他们采用了当时最先进的LSTM(长短期记忆网络)算法,并投入500万元采购了高性能计算集群,项目运行一年后,故障预测准确率仅65%,远低于预期的85%。

问题出在模型构建上,该企业直接使用了公开数据集训练模型,却未考虑自身风机的特殊性——其叶片材料、齿轮箱结构与公开数据集中的风机存在差异,导致模型“水土不服”,模型仅关注了运行数据(如转速、温度),却未融入设计参数(如叶片角度、齿轮箱载荷分布)和运维历史(如过去3年的故障记录),导致模型缺乏“业务理解”。
“我们以为算法越先进越好,没想到模型需要‘量身定制’。”该企业运维总监在2026年9月的“全球风电数字孪生论坛”上反思,这一案例揭示了一个关键问题:数字孪生模型不是“黑箱”,而是需要结合物理规律、业务逻辑和数据驱动的“混合模型”。
因子分析:模型精度的“黄金三角”
通过因子分析,我们发现影响数字孪生模型精度的关键因子包括:

- 物理模型准确性:模型需真实反映物理实体的结构、材料、运动规律,某航空发动机企业通过CT扫描获取叶片内部缺陷数据,并将其融入数字孪生模型,使裂纹预测准确率提升30%。
- 数据模型完整性:模型需涵盖设备的设计、运行、维护全生命周期数据,2026年,西门子推出的“Xcelerator”平台,通过集成PLM(产品生命周期管理)、MES(制造执行系统)和IoT数据,实现了模型数据的全链路打通。
- 业务模型适配性:模型需与具体业务场景结合,在预测性维护场景中,模型需输出“故障类型+发生时间+置信度”,而非简单的“是否正常”;在生产优化场景中,模型需考虑订单优先级、设备能耗等多维度约束。
应用场景:从“技术炫技”到“价值落地”,中间隔着“业务理解”
数字孪生的最终目标是解决业务问题,但许多企业却陷入了“为建而建”的误区——技术团队热衷于展示虚拟模型的“炫酷效果”,业务部门却看不懂、用不上,导致项目沦为“面子工程”。 2026年储能技术与能源转型及绿色标签热度不断攀升,技术创新带来新突破
案例3:某钢铁企业的“场景错位”
2026年7月,某大型钢铁企业投资3000万元建设了“高炉数字孪生系统”,通过3D可视化技术实时展示高炉内部温度、压力分布,并宣称“实现了高炉运行的透明化管理”,项目上线后,高炉工长们却抱怨:“这些数据我们早就通过仪表盘看到了,虚拟模型除了好看,对操作有什么帮助?”
深入调研发现,该企业的数字孪生系统聚焦于“数据展示”,却未解决业务痛点,高炉操作的核心是控制铁水温度和硅含量,但模型未提供“调整风量/煤量对铁水温度的影响预测”功能;又如,高炉突发异常时,工长需要快速判断是“炉缸侵蚀”还是“风口堵塞”,但模型未提供故障诊断建议。
“我们花了大价钱建系统,却没问清楚业务部门到底需要什么。”该企业智能制造负责人在2026年11月的“中国钢铁数字转型大会”上坦言,这一案例揭示了一个普遍问题:数字孪生的应用场景需从业务需求出发,而非技术能力出发。 2026年植物保护与公益创业热度持续上升,相关领域迎来新发展
因子分析:应用场景的“三步定位法”
通过因子分析,我们发现定位数字孪生应用场景的关键步骤包括:
- 业务痛点挖掘:从“降本、增效、提质、安全”等核心目标出发,识别关键业务环节的痛点,某半导体企业通过分析良率数据,发现“光刻环节的对准偏差”是主要瓶颈,进而将数字孪生应用于光刻机参数优化。
- 场景价值量化:明确场景落地后能带来的具体收益(如减少停机时间、降低能耗、提高产能),2026年,波士顿咨询发布的《工业数字孪生价值评估指南》提出,一个合格的数字孪生场景需满足“ROI(投资回报率)>150%”且“回收期<2年”。
- 用户参与设计:让业务人员深度参与模型设计,确保系统“好用、爱用”,某工程机械企业通过“业务人员+数据科学家”的联合团队,开发了“挖掘机液压系统故障诊断数字孪生”,工人们反馈:“这个模型就像‘老中医’,能告诉我们哪里堵了、怎么修。”
组织协同:数字孪生不是“技术部门的事”,而是“一把手工程”
数字孪生的实施涉及数据采集、模型开发、业务应用等多个环节,需要IT、OT、业务部门甚至供应商的深度协同,但现实中,部门壁垒、数据孤岛、利益冲突