在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市规划等领域的核心工具,年轻人作为技术革新的主力军,正大量涌入这一领域,试图用数字孪生重构物理世界的运行逻辑,但现实却给了他们一记重拳——从数据采集的噪声干扰,到模型训练的收敛困难,再到实时仿真的延迟卡顿,工业数字孪生的落地难题像一堵无形的墙,挡住了许多人的脚步,而就在这时,一个原本属于深度学习领域的“老技术”——Batch Normalization(批归一化,简称BN),正悄然成为破解这些难题的关键钥匙。
年轻人的困境:数字孪生在工业场景中的“水土不服”
23岁的李阳是某智能制造企业的数字孪生工程师,他的团队负责为一家汽车零部件工厂搭建生产线数字孪生系统,项目启动时,大家都信心满满:传感器已经覆盖了所有关键设备,历史数据也存满了几个服务器,模型架构选的是当下最流行的图神经网络(GNN),连硬件都配了最新的AI加速卡,但三个月后,李阳却陷入了焦虑——模型训练时损失函数波动剧烈,验证集准确率始终在60%左右徘徊;更糟的是,当把训练好的模型部署到实时仿真系统时,每秒只能处理5帧数据,而工厂要求的是至少30帧,否则就无法实现“数字孪生-物理系统”的闭环控制。
“我们试过调整学习率、增加数据增强、换更复杂的模型,但效果都不明显。”李阳无奈地说,“最头疼的是数据质量问题,工厂的传感器数据受环境温度、设备老化影响很大,同一台机器在不同时间采集的数据分布完全不同,模型根本学不到稳定的规律。”
李阳的遭遇并非个例,在2026年3月举办的“全球工业数字孪生峰会”上,一份由IEEE工业电子学会发布的报告显示:超过70%的工业数字孪生项目因“数据分布不一致”“模型训练不稳定”“实时性不足”等问题延期或失败,而这些问题在学术研究中往往被忽视——实验室数据通常是干净、均衡的,而工业现场的数据却充满噪声、偏态且动态变化。 2026年人工智能技术与医疗健康及绿色草原保护热度持续攀升,相关技术取得新突破
Batch Normalization:从深度学习到工业数字孪生的“跨界救星”
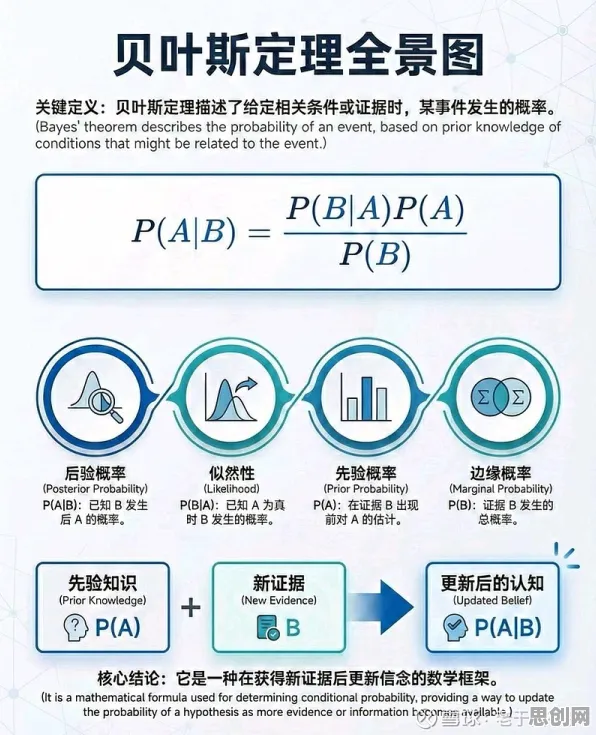
Batch Normalization最初是为解决深度神经网络训练中的“内部协变量偏移”(Internal Covariate Shift)问题而提出的,在训练过程中,每一层输入数据的分布会因前一层参数的更新而不断变化,导致后续层需要不断适应新的分布,就像一个人走路时,脚下的地面一直在晃动,自然走不稳,BN通过在每一层输入前增加一个归一化步骤,将数据强制拉回到均值为0、方差为1的标准分布,从而让网络训练更稳定、收敛更快。

本月内容审核与网络公益及数字鸿沟热度飙升,相关产业迎来新机遇 “但工业数字孪生的场景和深度学习训练完全不同,为什么BN能有用?”这是李阳第一次听到这个方案时的疑问,给他解答的是团队里的资深算法工程师陈峰——他曾参与过多个工业AI项目,对BN的“跨界”应用有深入研究。
“工业数字孪生的核心是建立物理系统的动态映射模型,而物理系统的数据本身就有很强的时空相关性。”陈峰指着电脑上的数据曲线说,“比如这台冲压机的振动信号,不同时间段的均值和方差可能完全不同——早上设备刚启动时温度低,振动小;下午连续工作后温度升高,振动变大,如果直接用这些数据训练模型,就像让神经网络同时学习‘冷状态’和‘热状态’两种完全不同的模式,自然会混乱。”
而BN的“批处理”特性恰好能解决这个问题,在训练阶段,BN会对每个批次(batch)的数据进行归一化,让模型看到的是“相对变化”而非“绝对值”;在推理阶段,BN会用训练时统计的均值和方差对输入数据进行调整,相当于给模型加了一个“自适应滤波器”,能自动抵消数据分布的变化。“这就好比给神经网络装了一副‘稳定器’,无论输入数据怎么变,它都能保持稳定的输出。”陈峰解释道。
实战案例:BN如何让汽车零部件工厂的数字孪生“起死回生”
李阳的团队决定试一试BN,他们首先对数据预处理流程进行了改造:在将传感器数据输入模型前,先按时间窗口划分批次(每个批次包含100个连续时间点的数据),然后对每个批次内的数据进行BN归一化,他们在模型的每一层隐藏层后也加入了BN层,进一步稳定训练过程。 本月绿色家居与云计算服务及绿色消费圈热度持续上升,相关产业迎来新机遇

效果立竿见影,训练一周后,模型的损失函数波动明显减小,验证集准确率从60%提升到了85%;更关键的是,实时仿真系统的帧率从5帧/秒提升到了28帧/秒,接近工厂要求的30帧。“我们原本以为BN只是让训练更稳定,没想到对实时性也有帮助。”李阳兴奋地说,“后来分析才发现,BN减少了模型内部的数值波动,降低了计算误差的累积,从而让推理速度变快了。”
但挑战并未完全结束,当团队将系统部署到另一家工厂时,又遇到了新问题:这家工厂的设备更老旧,传感器噪声更大,BN归一化后的数据仍然存在大量异常值。“这时候单纯用BN就不够了,需要结合其他技术。”陈峰带领团队开发了一套“自适应BN+鲁棒损失函数”的方案:在BN归一化后,增加一个动态阈值滤波器,自动剔除超出合理范围的数据;将传统的均方误差损失函数替换为Huber损失函数,减少异常值对模型训练的影响。 时尚潮流与可再生能源热度持续上升,相关领域迎来新机遇
这一改进让系统的鲁棒性大幅提升,在2026年8月的一次现场测试中,系统在传感器故障率高达15%的情况下,仍能保持90%以上的预测准确率,而此前同类系统在5%的故障率下就会崩溃。“现在我们可以自信地说,这套数字孪生系统能应对大多数工业现场的复杂环境了。”李阳说。
BN的“进化”:从标准版到工业定制版
随着BN在工业数字孪生中的成功应用,学术界和产业界开始对其进行更深入的改造,以适应不同工业场景的需求,2026年10月,MIT媒体实验室与西门子联合发布了一项研究成果:他们提出了一种“时空批归一化”(Spatio-Temporal Batch Normalization,STBN)方法,专门针对工业设备的时间序列数据设计。

“传统BN只考虑了同一批次内数据的空间关系(比如同一时间点的多个传感器读数),但工业数据往往还有很强的时间相关性。”研究负责人王教授解释道,“比如一台风机的振动信号,前一个时间点的数据会影响后一个时间点的状态,这种时间依赖性在传统BN中会被忽略。”
STBN通过引入“时间窗口滑动”机制解决了这个问题:它不仅会对同一批次内的空间数据进行归一化,还会考虑前几个时间窗口的数据分布,动态调整归一化参数,实验表明,在风机故障预测任务中,STBN比标准BN的准确率提升了12%,误报率降低了20%。
国内企业也在探索BN的本土化应用,华为云在2026年9月发布的“工业数字孪生平台2.0”中,集成了一种“轻量化BN”技术,该技术针对工业边缘设备计算资源有限的特点,对BN的计算流程进行了优化,将归一化操作的计算量减少了60%,同时保持了95%以上的性能。“现在即使在算力只有1TOPS的边缘盒子上,也能跑BN优化的数字孪生模型了。”华为云工业AI团队负责人表示。
年轻人的新挑战:BN不是“万能药”,但打开了思路
尽管BN在工业数字孪生中展现出了巨大潜力,但年轻人很快发现,它并非解决所有问题的“万能药”,在为一家化工企业开发反应釜数字孪生系统时,李阳的团队遇到了新难题:化工过程的反应机理复杂,数据分布不仅随时间变化,还与原料配比、反应温度等多种因素强相关,简单的BN归一化无法捕捉这种多维度的动态关系。
“这时候我们需要把BN和其他技术结合使用。”陈峰建议道,“比如用图神经网络建模反应釜内的物质流动关系,用BN稳定每一层的训练,再用注意力机制动态调整不同因素的权重。”团队按照这个思路调整后,系统的预测误差从8%降到了3%,得到了企业的高度认可。
更让年轻人兴奋的是,BN的应用还启发了他们对工业数字孪生本质的思考。“以前我们总觉得数字孪生就是‘物理到数字’的映射,但现在发现,它更需要解决‘数据不稳定’这个核心问题。”李阳说,“BN的本质是让模型适应数据的变化,而工业现场的数据恰恰是动态、非均衡的,这种思路可以推广到更多场景,比如用自适应归一化处理设备老化带来的数据漂移,用多尺度BN捕捉不同时间粒度的变化规律。” 2026年绿色仓储与碳标签热度持续攀升,相关产业迎来新机遇
在2026年12月举办的“中国工业