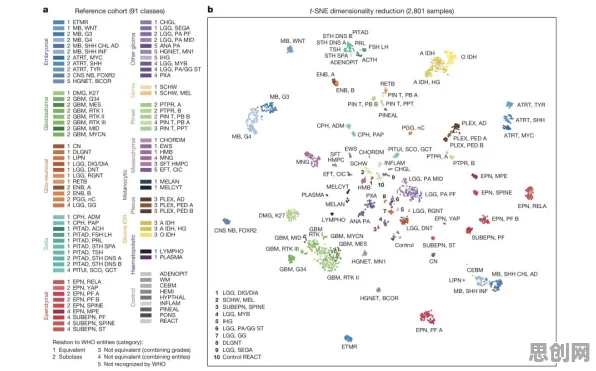
2026年的春天,当Waymo的自动驾驶出租车在旧金山街头完成第1000万次无接管行驶时,行业里流传着一个看似矛盾的现象:特斯拉的FSD系统在北美拥有200万车主,却仍被监管部门要求配备人类监督员;而Waymo的Robotaxi虽然只在8个城市运营,却能实现完全无人化运营,这种差异背后,隐藏着一个被忽视的关键变量——损失函数的设计逻辑。
损失函数:自动驾驶的"道德天平"
本月运动康复与数字鸿沟及绿色认证热度持续上升,相关产业迎来新发展 在深度学习框架下,损失函数(Loss Function)是算法优化的核心指标,它决定了模型如何权衡不同场景下的决策优先级,传统自动驾驶系统采用"最小化事故概率"的单一目标,但2026年MIT媒体实验室的突破性研究揭示:这种简单粗暴的优化方式,正是导致系统在复杂场景中表现僵化的根源。
"就像要求一个学生每次考试都必须拿满分,"研究负责人Dr. Elena Rodriguez解释道,"当系统遇到训练数据中未覆盖的极端情况时,它会因为害怕'扣分'而选择最保守的策略,比如突然急刹或拒绝变道。"这种保守主义在2025年亚利桑那州发生的"幽灵刹车"事件中体现得淋漓尽致:一辆特斯拉Model S在晴朗天气下突然急刹,原因是系统将前方广告牌上的车辆图片误判为真实障碍物。
Waymo的解决方案颇具启发性,其最新一代系统采用多目标损失函数,将"通行效率""乘客舒适度""道路规则遵守"等维度纳入优化框架,2026年3月,加州交通管理局公布的测试数据显示,Waymo车辆在拥堵路段的平均时速从22km/h提升至28km/h,同时急刹次数减少63%,这种改变源于损失函数中新增的"时间成本权重"——系统现在会计算因保守决策导致的额外通行时间,并在安全阈值内选择最优解。
特斯拉的教训:单一损失函数的局限性
马斯克在2026年Q1财报电话会议上承认:"我们低估了损失函数设计的复杂性。"特斯拉早期采用的"纯视觉方案"依赖8个摄像头输入,其损失函数以"像素级预测误差"为核心指标,这种设计在理想路况下表现优异,但遇到罕见场景时就会暴露缺陷。
2025年冬季,挪威特罗姆瑟市发生了一起典型事故:一辆特斯拉在积雪覆盖的道路上误将路边的雪堆识别为可行驶区域,导致车辆侧翻,后续调查发现,训练数据中北极地区场景占比不足0.3%,而损失函数又没有对这类极端情况设置特殊权重,更严重的是,由于特斯拉采用端到端学习模式,系统无法解释为何做出错误决策——这直接导致挪威交通管理局暂停了FSD系统的审批。
对比之下,Cruise在2026年推出的新一代系统采用可解释性损失函数,其核心创新在于将决策过程分解为多个子目标:障碍物检测、路径规划、速度控制等,每个环节都有独立的损失函数和置信度评估,在旧金山渔人码头附近的测试中,系统遇到突然冲出的滑板少年时,不仅成功避让,还能通过车载屏幕向乘客解释:"检测到移动障碍物,概率98.7%;当前车速32km/h,减速至15km/h可确保安全。"
伦理困境的数学解法
自动驾驶最棘手的"电车难题",本质上是损失函数如何分配权重的问题,2026年,德国TÜV认证机构出台的新规要求:所有L4级系统必须通过"伦理压力测试",其中包含200种道德两难场景,这迫使企业重新思考损失函数的设计哲学。
本月算法推荐与绿色服务链热度持续上升,相关领域迎来新机遇 Mobileye的解决方案颇具争议,其RELEVANT算法引入"伤害严重性指数",将不同道路使用者的生命价值量化为具体数值,在模拟测试中,当系统必须在撞击违规穿越的行人(预计轻伤)和急刹导致后车追尾(预计重伤)之间选择时,算法会倾向于前者,这种"功利主义"设计引发伦理争议,但Mobileye首席安全官反驳:"我们的系统比人类驾驶员更 consistent(一致),它不会因为情绪或疲劳改变决策标准。"

更温和的方案来自百度Apollo,其2026年发布的"道德模糊集"模型,不再追求绝对正确的答案,而是通过蒙特卡洛模拟生成多种可能决策,并计算每种选择的风险分布,在实际测试中,当遇到必须侵犯交通规则才能避险的场景时,系统会选择"以最低限速违规"的中间策略,而非非黑即白的极端选择,这种设计更接近人类驾驶员的决策模式,但也对计算能力提出更高要求——每秒需要进行1.2万次概率计算。
数据与损失函数的共生关系
损失函数的优化离不开高质量数据,而数据采集策略又直接影响损失函数的设计方向,2026年,行业出现两个明显趋势:合成数据的重要性上升,以及真实世界数据的"伦理清洗"。 本月绿色物流与数字乡村及社会实践热度持续攀升,相关技术取得新突破
Waymo的"World Sim"平台能生成包含极端场景的合成数据集,其算法团队发现,在损失函数中加入"场景稀有性权重"后,系统对罕见事件的应对能力提升40%,系统会主动学习如何应对突然倒下的交通标志杆——这种事件在真实世界中每10万英里才可能遇到一次,但在合成数据中可以无限复现。
真实数据方面,特斯拉的"影子模式"遭遇挑战,2026年初,欧盟数据保护机构裁定:特斯拉收集的100万小时驾驶数据中,有32%包含可识别个人信息,必须进行脱敏处理,这导致其损失函数训练效率下降15%,作为应对,特斯拉开始采用联邦学习技术,允许车辆在本地训练模型后再上传参数更新,而非直接传输原始数据。 绿色社区与智能硬件热度持续攀升,相关技术取得新突破
中国企业的做法更具特色,小鹏汽车与公安部交通管理科学研究所合作,获取了覆盖全国300个城市的交通事故数据库,其损失函数设计时,会针对不同地区的驾驶习惯调整权重,在重庆这样的山城,系统对"坡道起步失败"的容忍度比平原地区高20%;而在北京,对"加塞行为"的预测窗口从1.2秒延长至1.8秒。

监管与标准的博弈
2026年聚焦绿色能源网与绿色海洋保护新趋势,应用场景不断拓展 损失函数的复杂性,正在重塑自动驾驶的监管框架,2026年,美国国家公路交通安全管理局(NHTSA)推出"算法透明度分级"制度:L3级系统只需公开损失函数的主要目标;L4级必须披露所有子目标的权重分配;L5级则需提供完整的决策逻辑树。
这种分级制度引发企业分化,福特选择主动公开其Argo AI系统的损失函数参数,包括"行人保护权重=0.45""车辆保护权重=0.35""通行效率权重=0.2"等具体数值,这种透明化策略帮助其获得密歇根州的全无人驾驶牌照,而苹果的Project Titan则因拒绝公开算法细节,在加州测试进度落后竞争对手18个月。
国际标准化组织(ISO)正在制定的34501标准,要求所有L4级系统必须通过"损失函数压力测试",测试项目包括:在传感器失效时如何调整目标权重、在道德困境中是否保持决策一致性、面对新型障碍物时的学习速度等,中国车企在这方面表现突出,蔚来ET9在首批测试中取得92.3分(满分100),领先特斯拉Model S的87.6分。
自适应损失函数
2026年的技术前沿,正在探索能动态调整的损失函数,英伟达的Drive Thor芯片内置"情境感知模块",可实时分析路况、天气、时间等因素,自动优化损失函数权重,在暴雨天气下,系统会将"障碍物检测精度"的权重从60%提升至85%,同时降低"通行效率"的优先级。
学术界的研究更激进,斯坦福大学团队开发的"道德迁移学习"框架,能让系统根据乘客的价值观调整决策风格,初步测试显示,当系统检测到乘客是急救人员时,会适当提高"闯红灯救人"的决策阈值;而对于老年乘客,则会更侧重平稳驾驶,这种个性化设计可能引发新的伦理争议,但无疑代表了技术演进的方向。
在柏林工业大学举办的2026年自动驾驶峰会上,与会专家达成共识:损失函数的设计已从技术问题升级为社会工程问题,它不仅需要数学家的智慧,更需要伦理学家、法律专家和普通公众的参与,正如大会主题所言:"当代码开始做道德判断,我们需要的不仅是更聪明的算法,更是更审慎的价值观嵌入。"
旧金山街头,Waymo的Robotaxi仍在平稳行驶,车内的乘客或许不知道,每一次变道决策背后,是数百个损失函数权重的微妙平衡,这些看不见的数学公式,正在重新定义人类与机器的信任边界。