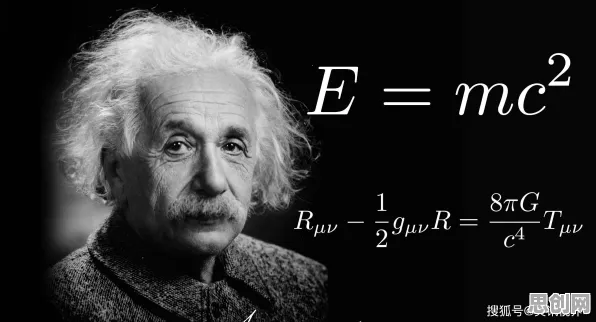本月碳关税与能量回收及智慧养老热度持续上升,相关产业迎来新机遇 在2026年的数字化浪潮中,数据已成为驱动社会运转的核心资产,从城市治理到个人生活,从商业决策到公共服务,数据的流动与利用无处不在,随着数据价值的日益凸显,一个关键问题逐渐浮出水面:谁拥有数据?谁有权使用数据?谁又该为数据的滥用负责?这些问题,正是数据确权的核心所在,而令人意外的是,在解决这一复杂问题的过程中,一个原本属于机器学习领域的概念——损失函数,竟成为了解释新居民数据确权进展的关键工具。
新居民数据确权:从混沌到有序的跨越
新居民,这个在城市化进程中不断壮大的群体,正成为数据确权的重要参与者,他们来自五湖四海,带着各自的背景、习惯和需求,在城市中扎根、生活、工作,他们的数据,包括但不限于居住信息、消费记录、健康状况、教育背景等,构成了城市数据生态的重要组成部分,在过去很长一段时间里,这些数据往往处于“无主”状态,被不同机构、企业随意收集、使用甚至交易,新居民的权益因此受到侵害。
2026年,这一状况正在发生根本性改变,以杭州为例,这座以数字化治理闻名的城市,率先推出了新居民数据确权试点项目,该项目通过区块链技术,为每位新居民建立了一个唯一的数据账户,记录其产生的各类数据,并明确数据的所有权、使用权和收益权,新居民可以自主决定哪些数据可以共享,哪些数据需要保密,甚至可以通过数据交易平台,将自己的数据授权给有需求的企业或机构使用,并获得相应的经济回报。
“以前,我的个人信息就像‘裸奔’一样,不知道被谁用了,也不知道用了干什么。”来自河南的新居民李明在接受采访时说,“现在好了,我的数据都在自己的账户里,我想给谁看就给谁看,不想给的就锁起来,还能通过数据赚钱,感觉挺不错的。”
李明的经历并非个例,在杭州的试点项目中,已有超过50万新居民完成了数据确权,他们的数据被有效保护,同时也在合规的前提下得到了充分利用,这一变化,不仅提升了新居民的获得感和幸福感,也为城市的数字化治理提供了更加精准、高效的数据支持。
损失函数:机器学习中的“指挥棒”
损失函数这一看似与数据确权风马牛不相及的概念,又是如何与新居民的数据权益产生关联的呢?要回答这个问题,我们首先需要了解损失函数在机器学习中的作用。
在机器学习中,损失函数是衡量模型预测结果与真实结果之间差异的指标,它的作用就像一根“指挥棒”,引导模型不断调整参数,以最小化损失函数的值,从而提高预测的准确性,损失函数就是告诉模型:“你错了多少,以及你应该怎么改。”
以图像识别为例,假设我们训练一个模型来识别猫和狗的图片,在训练过程中,模型会对每张图片做出预测,然后与真实标签进行比较,如果模型将一张猫的图片误判为狗,那么损失函数就会给出一个较大的值,表示模型的预测错误较大,模型会根据这个反馈,调整自身的参数,以便在下次遇到类似的图片时能够做出更准确的判断。
本月志愿服务活动与家居装饰及医疗器械热度持续攀升,相关应用不断深化 
损失函数的设计至关重要,一个好的损失函数应该能够准确反映模型的预测误差,同时引导模型朝着正确的方向优化,如果损失函数设计不合理,模型可能会陷入“局部最优解”,即虽然在当前参数下损失函数值较小,但并非全局最优,导致模型的泛化能力较差,无法在新数据上表现出色。
损失函数与数据确权的“奇妙邂逅”
回到数据确权的问题上,在数据确权的过程中,我们同样面临着一个“优化”问题:如何设计一套合理的规则,既能保护数据主体的权益,又能促进数据的合法流通和利用?这个问题,与机器学习中的模型优化有着惊人的相似之处。
在数据确权中,我们可以将数据主体的权益视为“真实结果”,而数据的使用和流通方式则视为“模型预测”,我们的目标,是找到一种数据使用和流通的方式,使得数据主体的权益得到最大程度的保护,同时数据的价值也能得到充分释放,这,就相当于在机器学习中寻找一个最优的模型参数,使得损失函数的值最小。
损失函数在这里具体是如何发挥作用的呢?我们可以这样理解:在数据确权的过程中,不同的数据使用和流通方式会对数据主体的权益产生不同的影响,有些方式可能侵犯了数据主体的隐私权,有些方式可能剥夺了数据主体的经济收益,还有些方式可能导致了数据的不公平使用,这些负面影响,都可以视为数据确权中的“损失”。
我们的任务,就是设计一套“损失函数”,来量化这些负面影响,这个损失函数可以包括多个维度,如隐私泄露风险、经济收益损失、数据使用公平性等,每个维度都可以根据实际情况赋予不同的权重,以反映我们对不同权益的重视程度。
一旦有了这个损失函数,我们就可以像机器学习中的模型优化一样,不断调整数据使用和流通的规则,以最小化损失函数的值,这意味着,我们要找到一种平衡点,既能让数据得到充分利用,又能最大程度地保护数据主体的权益。
 2026年6月热度持续攀升大数据分析持续升温,技术创新带来新突破
2026年6月热度持续攀升大数据分析持续升温,技术创新带来新突破
2026年的真实案例:损失函数如何助力数据确权
本月体育产业与绿色标识及绿色产品链热度持续攀升,相关技术取得新突破 2026年,在上海的一次数据确权实践中,损失函数的概念被巧妙地应用到了实际场景中,这次实践的主角,是一批居住在浦东新区的新居民,他们中的许多人从事着外卖配送、网约车驾驶等新兴职业,他们的数据,如行驶轨迹、接单记录、客户评价等,对于平台企业来说具有极高的价值,在过去,这些数据往往被平台企业独家掌控,新居民们无法从中获得应有的收益,甚至有时还会因为数据的滥用而遭受损失。
为了改变这一状况,浦东新区政府联合多家科研机构,共同设计了一套基于损失函数的数据确权方案,该方案首先明确了新居民数据的所有权归新居民本人所有,平台企业只有在使用数据时才能获得相应的授权,针对数据的使用和流通,设计了一套复杂的损失函数。
这个损失函数考虑了多个因素,包括数据的敏感程度、新居民的经济状况、平台企业的使用需求等,对于涉及新居民隐私的敏感数据,如家庭住址、联系方式等,损失函数会赋予较高的权重,意味着任何未经授权的使用都会导致较大的损失值,而对于一些非敏感数据,如接单记录、行驶轨迹等,损失函数则会根据平台企业的使用需求和新居民的经济状况进行动态调整。
在实际操作中,平台企业需要向新居民提出数据使用申请,并说明使用的目的、方式和期限,新居民可以根据自己的意愿和损失函数的反馈,决定是否授权以及授权的范围,如果平台企业的使用方式导致了较大的损失值,新居民可以要求平台企业支付更高的数据使用费用,或者拒绝授权。
这套方案实施后,取得了显著的效果,新居民们的数据权益得到了有效保护,他们不再担心自己的数据被滥用或泄露,平台企业也获得了更加合法、合规的数据支持,提高了服务的质量和效率,更重要的是,通过损失函数的动态调整,新居民和平台企业之间形成了一种良性互动的关系,促进了数据的合法流通和利用。
“以前,我觉得自己的数据就是平台的‘摇钱树’,他们想怎么用就怎么用。”一位参与试点的新居民外卖员张伟说,“现在好了,有了这个损失函数,我的数据值多少钱,我能得到多少回报,都清清楚楚,如果平台用得不好,我还可以说‘不’,这种感觉,真是太棒了!”

损失函数背后的深层逻辑:平衡与优化
损失函数在数据确权中的应用,并非偶然,它背后蕴含的深层逻辑,是平衡与优化,在数据确权的过程中,我们面临着多重利益的博弈:数据主体的隐私权、经济收益权与数据使用者的利用需求、社会公共利益之间的平衡,任何一方的利益过度倾斜,都可能导致数据确权体系的失衡和失效。
损失函数的作用,就是通过量化的方式,将这种复杂的利益博弈转化为一个可优化的数学问题,它帮助我们明确哪些利益是重要的,哪些利益是可以妥协的,以及如何在不同利益之间找到一个最佳的平衡点,这种平衡点的寻找,正是数据确权的核心所在。
损失函数还具有动态调整的特性,随着社会环境的变化、技术进步的推动以及人们权益意识的提高,数据确权的需求也会不断发生变化,损失函数可以根据这些变化,及时调整自身的参数和权重,以确保数据确权体系始终能够适应新的形势和需求。
展望未来:损失函数在数据确权中的广阔前景
2026年,新居民数据确权的进展只是冰山一角,随着数字化进程的加速推进,数据确权将成为未来社会治理的重要议题,而损失函数这一来自机器学习领域的概念,也将在数据确权中发挥越来越重要的作用。
我们可以期待看到更多基于损失函数的数据确权实践,这些实践可能涉及不同的领域、不同的群体和不同的数据类型,但无论形式如何变化,损失函数的核心思想——平衡与优化——都将贯穿其中。
2026年土壤修复与湿地保护热度持续上升,相关产业迎来新机遇 随着技术的不断进步和理论的不断完善,损失函数的设计也将更加精细、更加科学,它可能不仅仅是一个简单的数学公式,而是一个包含多个层次、多个维度的复杂系统,这个系统能够更加准确地反映数据主体的权益需求,更加有效地引导数据的合法流通和利用。
损失函数的应用还将促进数据确权与其他领域的深度融合。