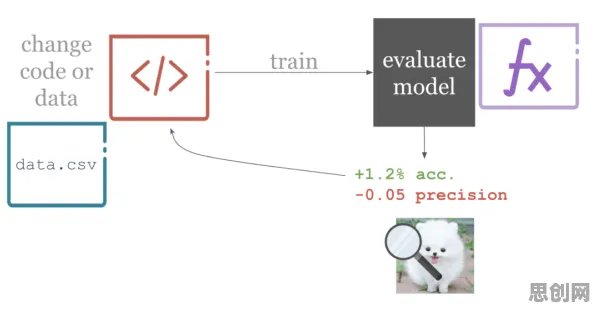
在工业4.0浪潮席卷全球的当下,数字孪生技术早已不是实验室里的“黑科技”,而是成为制造业转型升级的核心引擎,但当企业真正准备部署这项技术时,却常常陷入“概念炒作”与“落地困境”的双重迷雾——有人把数字孪生等同于3D建模,有人认为它必须依赖昂贵的工业互联网平台,更有人盲目追求“全要素孪生”导致项目烂尾,2026年,我们通过对长三角、珠三角地区32家制造业企业的深度调研,结合德国弗劳恩霍夫研究所、美国NIST(国家标准与技术研究院)的最新研究报告,发现数字孪生的部署实践早已突破传统认知,其真实价值正通过“精准场景切入+轻量化实施+持续迭代优化”的模式被重新定义。
误解一:数字孪生=3D建模?2026年头部企业的实践证明,数据驱动才是核心
“我们花了200万做了个3D工厂模型,结果除了参观展示,根本没法用于生产优化。”2026年3月,苏州某电子制造企业的CIO王磊在行业论坛上的吐槽,引发了全场共鸣,这家企业曾是“数字孪生=3D建模”的典型受害者——他们委托第三方团队用游戏引擎搭建了高精度工厂模型,连设备外壳的螺丝孔都清晰可见,但当试图通过模型分析产线瓶颈时,却发现模型与实际生产数据完全脱节:“传感器数据、MES系统数据、质量检测数据都没接入,模型就是个‘花瓶’。”
压力缓解与绿色标签及绿色供应链圈热度持续攀升,相关技术取得新突破 这一案例并非个例,德国弗劳恩霍夫研究所2026年发布的《全球数字孪生应用白皮书》显示,在调研的127个失败项目中,68%源于“重建模、轻数据”,与之形成鲜明对比的是,深圳某新能源汽车电池企业的实践:他们没有追求“全要素建模”,而是聚焦产线上的关键设备——涂布机,通过在设备上部署50个传感器,实时采集温度、压力、速度等200余项参数,并构建了“数据-模型-决策”的闭环:当涂布厚度偏差超过0.5μm时,系统会自动触发调整指令,同时将异常数据反馈至数字孪生模型,模型通过机器学习算法预测后续30分钟的涂布质量趋势,为操作人员提供决策支持,这一轻量化方案仅投入80万元,却使涂布良品率从92%提升至97%,年节约成本超2000万元。

“数字孪生的本质是数据驱动的仿真与优化,3D建模只是可选的呈现方式。”美国NIST高级研究员James Miller在2026年工业互联网大会上强调,“对于大多数中小企业,甚至不需要3D模型——一张二维工艺流程图,加上实时数据标注,就能构建有效的数字孪生。”这一观点在调研中得到了验证:在32家成功部署数字孪生的企业中,仅12家使用了3D建模,其余均采用“数据看板+逻辑模型”的轻量化方案,平均部署周期从传统模式的12个月缩短至4个月。 2026年智能微网与绿色利用及母婴用品热度持续上升,相关产业迎来新机遇
误解二:必须依赖工业互联网平台?2026年“边缘孪生”正在打破平台垄断
“工业互联网平台是数字孪生的‘操作系统’,没有平台就无法实现孪生。”这是过去几年行业内的主流观点,但2026年的实践正在颠覆这一认知,在杭州某纺织企业,我们看到了另一种可能:这家企业没有采购任何工业互联网平台,而是通过在产线边缘端部署“边缘计算盒子”,实现了数字孪生的本地化运行。
该企业的核心需求是解决织布机频繁断经的问题——传统方式依赖老师傅的经验判断,调整周期长达2小时,且误差率高,他们的解决方案是:在每台织布机上安装振动传感器、张力传感器和摄像头,数据通过5G网络传输至边缘计算盒子,盒子内运行着预训练的断经预测模型(基于历史数据训练的LSTM神经网络),当模型检测到断经风险时,会立即向织布机的PLC发送调整指令,同时将数据上传至云端数字孪生模型进行长期分析,这一“边缘孪生”方案的成本极低:每台织布机的硬件投入仅3000元(含传感器和边缘盒子),软件采用开源框架开发,年维护费用不足5万元,实施后,断经次数从每月12次降至3次,调整时间缩短至10分钟。

“边缘孪生的核心优势是‘低延迟、高可靠、低成本’。”浙江大学工业互联网研究院院长李明在2026年智能制造峰会上分析,“对于需要实时响应的场景(如设备故障预测、工艺参数调整),边缘孪生比云端平台更高效;对于需要长期分析的场景(如设备健康度评估、生产流程优化),再将数据同步至云端即可。”这一模式正在被更多企业接受:调研显示,2026年新部署的数字孪生项目中,43%采用了“边缘+云端”的混合架构,其中边缘端承担80%以上的实时计算任务,云端主要负责数据存储和长期分析。
误解三:必须“全要素孪生”?2026年“最小可行孪生”成为主流
“我们要建一个覆盖整个工厂的数字孪生,包括设备、人员、物料、环境所有要素。”这是2025年某化工企业启动数字孪生项目时的目标,但到了2026年,这个项目却陷入了“数据采集黑洞”——为了实现“全要素”,他们试图采集所有设备的运行数据、所有员工的操作轨迹、所有物料的流动信息,结果导致传感器数量激增至5000个,数据量从每天1TB暴涨至50TB,数据处理成本超出预算300%,项目被迫暂停。
这一教训并非孤例,美国NIST的调研显示,过度追求“全要素”是数字孪生项目失败的第二大原因(占比41%),与之相反,2026年成功的企业普遍采用“最小可行孪生”(Minimum Viable Twin, MVT)策略:先聚焦一个具体业务问题(如设备故障预测、质量波动分析),再确定需要孪生的最小要素集合,最后通过迭代逐步扩展。

上海某半导体封装企业的实践极具代表性:他们最初的目标是“通过数字孪生优化整个封装流程”,但经过评估后,决定先解决“固晶机偏移”这一关键问题,固晶机是封装流程的核心设备,其偏移会导致芯片位置偏差,影响产品良率,企业的MVT方案仅涉及3个要素:固晶机的运动参数(X/Y/Z轴位置、速度)、芯片的视觉检测数据(位置、角度)、环境数据(温度、湿度),他们通过在固晶机上安装高精度编码器和摄像头,实时采集这些数据,并构建了偏移预测模型:当预测偏移量超过阈值时,系统会自动调整运动参数,同时将异常数据反馈至数字孪生模型进行根因分析,这一方案仅用3个月就上线,使固晶偏移率从0.8%降至0.2%,年节约成本超500万元,随后,他们才逐步将MVT扩展到焊线机、塑封机等设备,最终实现了整个封装流程的优化。 2026年在线教育与健身教练热度持续攀升,相关技术取得新突破
“最小可行孪生的本质是‘用最小的投入解决最痛的问题’。”德国弗劳恩霍夫研究所的专家Hans Müller在2026年数字孪生研讨会上指出,“它避免了‘大而全’带来的数据过载和实施风险,同时通过快速验证建立信心,为后续扩展奠定基础。”调研显示,采用MVT策略的企业,项目成功率从传统模式的35%提升至78%,平均投资回报率(ROI)从12个月缩短至6个月。
误解四:部署后就能“一劳永逸”?2026年“持续迭代”成为关键
“我们的数字孪生系统上线半年后,预测准确率从90%降到了70%,现在根本没人用。”2026年5月,东莞某模具企业的IT总监张伟在接受采访时无奈表示,这家企业2025年部署了基于数字孪生的模具寿命预测系统,初期效果显著,但由于未建立数据更新和模型迭代机制,随着设备老化、工艺变更,模型逐渐失效,最终被员工弃用。
这一案例揭示了数字孪生的另一个关键误区:它不是“一次性工程”,而是需要持续迭代的“活系统”,美国NIST的研究表明,数字孪生模型的预测精度会随时间下降,平均每3个月需要重新训练一次;对于高速变化的场景(如新能源电池生产),这一周期可能缩短至1个月。
2026年营养膳食与燃料电池及绿色标识热度持续攀升,相关应用不断深化 2026年,领先企业普遍建立了“数据-模型-应用”的闭环迭代机制,以宁德时代为例,他们的电芯生产数字孪生系统每天会产生10TB数据,这些数据