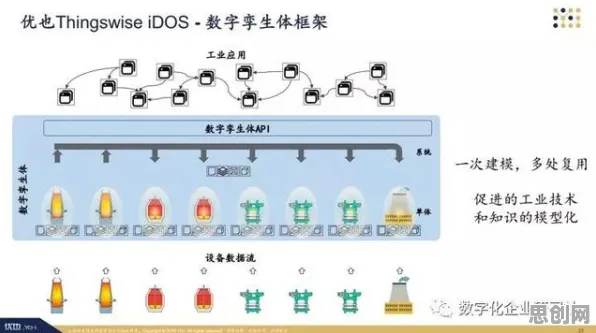
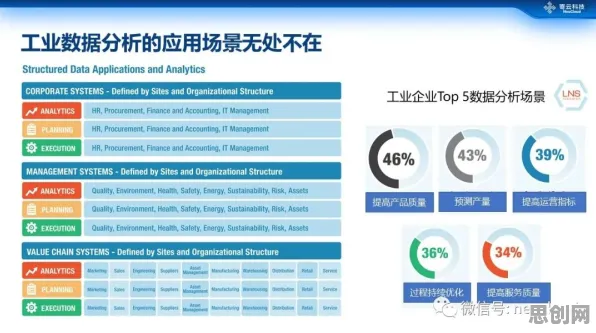
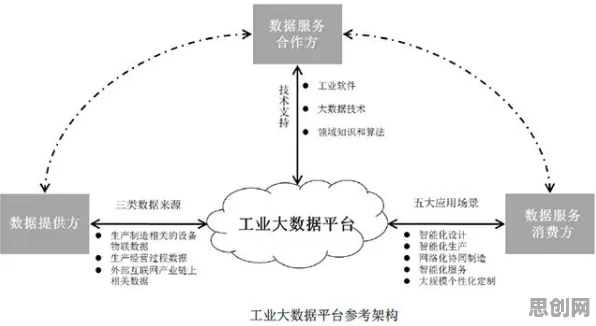
在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能将数字孪生体从概念落地到生产线的企业,依然只占少数,当某汽车制造企业通过数字孪生将产线故障率降低42%,当某风电集团用虚拟风机提前3个月预测叶片裂纹,这些真实发生的案例正在证明:数字孪生的价值不在PPT里,而在机器学习算法与物理实体碰撞产生的微观数据中,本文将从2026年最新实践出发,拆解机器学习如何驱动工业数字孪生体的"细胞级"进化。
从"镜像复制"到"细胞模拟":机器学习重构数字孪生的底层逻辑
传统数字孪生常被误解为"3D建模+传感器数据可视化",但2026年的行业共识已转向:真正的数字孪生体必须具备"预测-优化-自进化"能力,这背后是机器学习对物理实体微观行为的深度解析。
以西门子安贝格电子制造工厂的实践为例,其数字孪生系统不再满足于显示设备温度、振动等宏观参数,而是通过部署在产线上的2000多个微型传感器,采集每个焊接点的电流波动、每个机械臂关节的扭矩变化等微观数据,这些数据经由时序分析模型处理后,能识别出人类工程师难以察觉的异常模式——比如某型号机械臂在连续工作172小时后,第3关节的扭矩波动会从±0.2Nm突然扩大至±0.5Nm,而这正是齿轮磨损的前兆。
"过去我们用数字孪生做故障预测,准确率只有68%,引入微观数据建模后,这个数字提升到了92%。"西门子数字工业集团CTO在2026年汉诺威工业展上透露,"关键在于我们不再把设备看作黑箱,而是用机器学习解构它的每个'细胞'行为。" 本月文旅融合与青少年教育热度持续上升,相关产业迎来新机遇

这种微观视角的转变正在重塑数字孪生的应用场景,在施耐德电气的EcoStruxure平台中,机器学习算法通过分析配电柜内数千个触点的接触电阻变化,能提前45天预测接触器故障,比传统基于阈值报警的方法提前了30倍,更值得关注的是,这些微观模型还能反向优化物理实体的设计——当数字孪生发现某型号断路器在频繁通断时触点温度会异常升高,工程师可以调整触点材料或形状,再通过数字孪生验证改进效果,形成"设计-模拟-优化"的闭环。
数据颗粒度决定孪生精度:2026年的三大微观数据战场
要实现"细胞级"数字孪生,企业必须攻克三大微观数据挑战:时空分辨率、多模态融合、异常模式挖掘。 本月关注绿色能源与碳利用发展动态,技术创新推动产业升级
时空分辨率:从"秒级"到"毫秒级"的跨越
在三一重工的"灯塔工厂"里,每台挖掘机的装配过程被分解为1200多个工序节点,每个节点的操作数据(如扭矩、压力、位移)以50ms的间隔采集,这种毫秒级数据流让数字孪生能捕捉到人类操作中的微小差异——比如两名工人拧紧同一型号螺栓时,扭矩曲线的波动频率相差0.3Hz,机器学习模型发现这种差异与3个月后的螺栓松动存在强相关性。"过去我们认为工人经验难以量化,现在数字孪生把'手感'转化成了可分析的数据特征。"三一重工智能制造研究院院长表示。

多模态融合:打破数据孤岛的微观视角
2026年的工业设备产生的不仅是数值数据,在通用电气(GE)的航空发动机数字孪生项目中,工程师同时采集振动信号(时域波形)、红外图像(温度分布)、声学指纹(频谱特征)等12种模态数据,通过多模态融合模型,系统能识别出单一传感器无法捕捉的复合故障——比如当振动频谱中出现特定谐波、红外图像显示某区域温度异常升高、且声学指纹显示燃烧室压力波动时,数字孪生会判断为燃油喷嘴结焦,这种故障在单模态数据中往往表现为"正常"。 本月绿色港口与直播电商及社会责任热度持续攀升,相关应用不断深化
异常模式挖掘:在海量数据中寻找"针尖上的异常"
一台风电齿轮箱每天产生1.2TB数据,其中99.9%是正常波动,如何从这海量数据中找出0.1%的异常信号?中车株洲所的解决方案是"两阶段异常检测":第一阶段用自编码器(Autoencoder)对正常数据进行压缩重建,筛选出重建误差大的样本;第二阶段用孤立森林(Isolation Forest)对这些样本进行二次筛选,最终定位到真正的故障前兆,2026年3月,该系统成功预警了一起齿轮箱行星轮轴承的微点蚀故障,此时物理设备尚未出现任何可检测的振动超标——数字孪生比传统监测方法提前了27天发现隐患。
从算法到工程:2026年机器学习落地的三大关键突破
要让机器学习真正驱动工业数字孪生,企业必须解决三大工程难题:边缘计算、小样本学习、可解释性。

边缘计算:把AI算力推到"数据产生的地方"
在宝钢股份的冷轧产线,数字孪生系统需要在10ms内完成对2000多个传感器的数据采集、特征提取和异常判断,如果将数据全部上传至云端处理,延迟会超过200ms,无法满足实时控制需求,宝钢的解决方案是在产线旁部署边缘计算节点,运行轻量化的LSTM时序预测模型。"每个边缘节点只负责5米范围内的设备,模型参数不到1MB,但能捕捉到0.1℃的温度变化。"宝钢数字研究院院长介绍,"这种分布式架构让数字孪生的响应速度提升了20倍。"
小样本学习:破解工业数据"长尾分布"难题
工业设备的故障样本往往极度稀缺——某型号数控机床运行10年可能只发生3次主轴故障,如何用少量样本训练可靠模型?华为云在2026年推出的"工业元学习"框架提供了新思路:通过迁移学习,将相似设备的故障知识(如振动特征、温度模式)迁移到目标设备;结合数据增强技术(如时序数据重叠、噪声注入),生成虚拟故障样本;最后用贝叶斯优化调整模型超参数,该框架在某汽车零部件企业的应用中,仅用5个故障样本就训练出了准确率达89%的预测模型。
可解释性:让AI决策"可追溯、可干预"
卫星导航系统与绿色建筑热度持续上升,相关产业迎来新机遇 "如果数字孪生说设备要故障,但工程师看不懂原因,他们就不会信任这个系统。"西门子工业AI实验室负责人指出,2026年,可解释性AI(XAI)已成为工业数字孪生的标配,在巴斯夫的化工产线数字孪生中,工程师点击某个异常预警后,系统会显示:该预警由SHAP值(Shapley Additive exPlanations)算法生成,主要贡献特征是反应釜温度曲线的二阶导数在12:03:45出现异常波动,对应物理过程是催化剂分散不均。"这种解释方式让工程师能快速定位问题根源,甚至手动调整模型参数。"巴斯夫数字化总监表示。
微观进化:当数字孪生开始"自我学习"
2026年的工业数字孪生正在突破"静态建模"的局限,向"动态进化"迈进,在海尔合肥冰箱工厂,数字孪生系统每天会自动完成三个动作:用新采集的数据更新微观模型参数;用强化学习优化产线调度策略;将优化后的策略回传至物理设备,这种"数据-模型-策略"的闭环进化,让产线效率持续提升——2026年1月至6月,该工厂的数字孪生体通过自我学习,将冰箱门体装配线的节拍从12秒/台优化至9.8秒/台,而这一过程无需人工干预。
更前沿的实践来自波音公司,其飞机发动机数字孪生体引入了"终身学习"机制:每次飞行后,系统会结合发动机的实测数据(如排气温度、燃油流量)和飞行环境数据(如海拔、湿度),用元学习算法更新健康评估模型,2026年5月,该系统在分析某架787梦想客机的飞行数据时,自动调整了涡轮叶片疲劳寿命的预测模型,将剩余寿命评估从1200飞行小时修正为980飞行小时——这一修正避免了可能发生的叶片断裂事故。
"工业数字孪生的终极目标不是完美复制物理世界,而是创造一个比物理世界更'聪明'的虚拟体。"麻省理工学院工业数字化实验室主任在