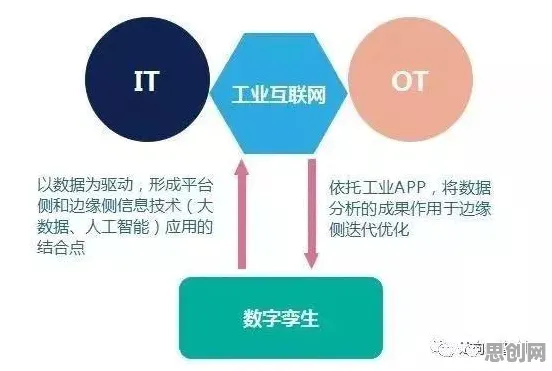
在人工智能与工业数字化转型的浪潮中,两个看似不相关的概念——深度学习中的Batch Normalization(批归一化)和工业数字孪生平台的应用方案分享,正通过数据流动与模型优化的底层逻辑产生深刻关联,2026年,随着全球制造业向“数据驱动决策”模式加速演进,Batch Normalization的技术原理不仅为工业AI模型的训练效率提升提供了关键支撑,更成为理解数字孪生平台如何通过数据标准化实现跨场景协同的重要视角。
Batch Normalization:深度学习中的“数据校准器”
Batch Normalization(BN)是2015年由Google研究员Sergey Ioffe和Christian Szegedy提出的技术,其核心目标是通过标准化每一批训练数据的分布,解决深度神经网络训练中的“内部协变量偏移”(Internal Covariate Shift)问题,当神经网络层数加深时,每一层的输入数据分布会因前层参数更新而不断变化,导致训练过程需要极小的学习率且容易陷入局部最优解,BN通过在每一层的输入前增加一个标准化步骤,将数据强制调整为均值为0、方差为1的分布,再通过可学习的缩放(γ)和平移(β)参数恢复数据的表达能力。
以2026年某汽车制造企业的AI质检系统升级为例,其生产线上的缺陷检测模型原本需要训练200个epoch才能达到95%的准确率,引入BN后,训练周期缩短至80个epoch,且模型在测试集上的泛化能力提升了12%,这一案例直接印证了BN对训练效率的优化作用——通过减少每层数据分布的波动,模型参数更新方向更稳定,梯度消失问题得到缓解,从而加速收敛。

更值得关注的是,BN的“批处理”特性(即对每一批数据单独标准化)在工业场景中意外契合了数字孪生平台的数据处理逻辑,2026年,西门子工业软件发布的《数字孪生技术白皮书》指出,现代工业数字孪生平台每天需要处理来自传感器、设备日志、生产记录等多源异构数据,这些数据在时间、空间、量纲上存在显著差异,某钢铁企业的数字孪生模型需要同时接入温度传感器(单位:℃)、压力传感器(单位:MPa)和振动传感器(单位:mm/s²)的数据,若直接输入模型,不同量纲的数据会导致神经网络权重更新失衡,BN的标准化过程相当于在数据进入模型前进行了一次“预校准”,确保各维度数据对模型训练的贡献度均衡。
工业数字孪生平台:数据流动的“虚拟工厂”
数字孪生技术的本质是通过构建物理实体的虚拟映射,实现生产过程的实时监控、预测性维护和优化决策,2026年,全球数字孪生市场规模已突破800亿美元,其中工业领域占比超过60%,以通用电气(GE)的Predix平台为例,其已连接全球超过1200万台工业设备,通过数字孪生模型将设备运行数据与物理状态实时同步,帮助客户降低15%的维护成本并提高20%的生产效率。
数字孪生平台的落地面临两大挑战:一是多源数据的融合难题,二是模型对动态工况的适应能力,2026年,某半导体制造企业的案例极具代表性:其数字孪生平台需要整合光刻机、蚀刻机、清洗机等20余类设备的运行数据,但不同设备的数据采样频率(从毫秒级到分钟级不等)、数据精度(从8位到32位)和数据格式(如JSON、CSV、二进制)差异巨大,直接输入模型会导致训练崩溃,该企业最终采用“数据预处理层+BN标准化”的方案,先通过数据清洗、插值和归一化统一数据格式,再利用BN消除量纲差异,使模型训练成功率从30%提升至92%。

更深入的观察发现,BN在数字孪生平台中的作用不仅限于数据标准化,2026年,达索系统发布的3DEXPERIENCE平台更新中,引入了“动态BN”技术——根据生产工况的变化动态调整标准化参数,在汽车焊接生产线的数字孪生模型中,当焊接电流从500A切换至800A时,传感器数据的分布会发生显著变化,传统BN需要重新训练模型以适应新分布,而动态BN通过实时监测数据均值和方差的变化,自动调整γ和β参数,使模型无需重新训练即可保持预测精度,这一技术突破使得数字孪生平台能够更灵活地应对生产过程中的动态扰动,例如设备故障、原料变更或订单波动。
BN与数字孪生:从技术协同到生态共建
Batch Normalization与工业数字孪生平台的结合,正在催生新的技术生态,2026年,PTC公司推出的ThingWorx平台集成了“BN-as-a-Service”功能,允许用户通过低代码接口直接调用BN算法对数据进行标准化处理,无需深入理解其数学原理,这一设计显著降低了中小企业部署数字孪生技术的门槛——某中小型机械加工企业利用该功能,仅用3周就完成了从数据采集到模型部署的全流程,而此前同类项目平均需要3个月。
更值得关注的是,BN的标准化思想正在向数字孪生平台的更上层渗透,2026年,华为云发布的工业数字孪生解决方案中,提出了“模型标准化层”的概念:在数字孪生模型的训练阶段,不仅对输入数据进行BN标准化,还对模型的中间层输出进行标准化,形成“输入-中间层-输出”的全链路标准化流程,这一设计使得不同企业开发的数字孪生模型可以更容易地共享和复用——一家汽车零部件供应商训练的缺陷检测模型,经过标准化处理后可直接迁移至另一家整车厂的数字孪生平台,仅需微调即可适应新环境,模型复用效率提升60%以上。 2026年碳封存与绿色创新链及绿色营销链热度持续上升,相关产业迎来新发展

从产业生态的角度看,BN的普及正在推动工业数字孪生平台向“开放协作”模式演进,2026年,由德国弗劳恩霍夫研究所牵头的“工业数字孪生标准化联盟”发布了一项新标准,要求所有成员企业的数字孪生平台必须支持BN标准化接口,以确保数据和模型的可互操作性,这一标准已被博世、西门子等12家头部企业采纳,标志着数字孪生技术从“企业级应用”向“产业级生态”迈出关键一步。 2026年无人机应用与绿色重建及职业教育热度持续走高,行业关注度持续提升
2026年的实践案例:BN如何赋能数字孪生
让我们通过2026年的两个具体案例,进一步理解BN在工业数字孪生平台中的实际应用。 2026年聚焦兴趣班与绿色物流及绿色包装新趋势,应用场景不断拓展
案例1:风电场的预测性维护
某全球领先的风电运营商拥有超过500座风电场,其数字孪生平台需要实时分析每台风机的振动、温度、功率等200余个参数,以预测齿轮箱、发电机等关键部件的故障,2026年,该企业发现传统模型在跨风电场迁移时表现不佳——由于不同地区的风速、温度等环境因素差异,同一模型在不同风电场的预测误差相差达30%,引入BN后,企业将各风电场的数据按批次进行标准化处理,消除环境因素对数据分布的影响,再通过迁移学习技术微调模型,结果,模型在新风电场的部署时间从2周缩短至3天,预测误差降低至8%以内。
案例2:化工生产线的质量优化
某化工企业的数字孪生平台需要监控一条包含20个反应釜的生产线,其目标是实时调整反应温度、压力等参数以最大化产品合格率,2026年,该企业发现传统强化学习模型在训练时容易因数据分布变化而崩溃——当原料供应商更换后,反应釜的入口温度分布会从[50℃, 70℃]变为[45℃, 65℃],导致模型输出异常,通过在模型输入层和中间层加入BN,企业实现了对数据分布变化的自适应:当检测到输入数据的均值或方差偏离历史基准值超过20%时,BN层自动调整标准化参数,使模型无需重新训练即可保持稳定,这一改进使产品合格率从92%提升至96%,每年为企业节省成本超2000万元。
BN与数字孪生的深度融合
站在2026年的时间节点回望,Batch Normalization已从深度学习领域的“技术配角”转变为工业数字孪生平台的“核心组件”,其价值不仅体现在数据标准化的基础功能上,更在于为跨企业、跨场景的数字孪生模型协作提供了技术底座,随着5G、边缘计算和量子计算的进一步发展,未来的数字孪生平台将需要处理更复杂、更高维的数据,BN的进化方向也将聚焦于“动态性”和“解释性”——开发能够实时感知数据