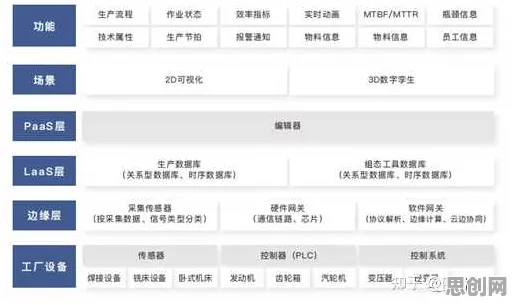
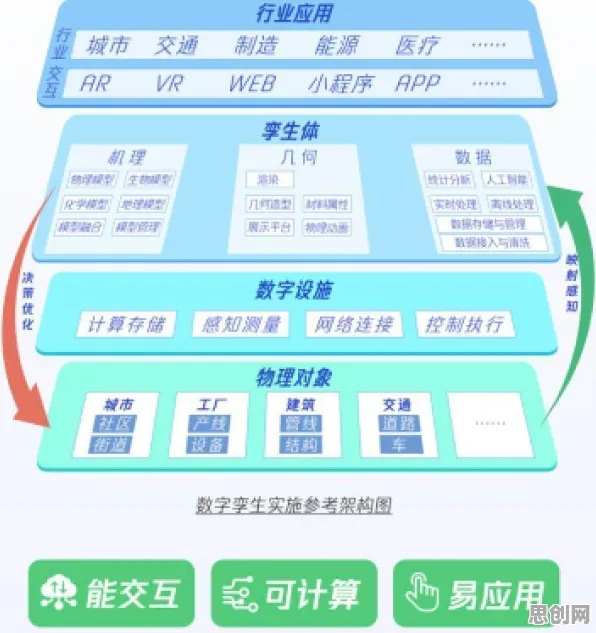
一场看似荒诞的跨界对话
2026年3月,北京某互联网公司的算法工程师张磊在家庭聚会上被亲戚追问:"你研究的那个Adagrad优化器,能不能解释我儿子为啥不要孩子?"这个看似无厘头的问题,让这位深耕机器学习领域十年的专家陷入了沉思,三天后,他在个人技术博客上发布了一篇题为《从梯度下降到生育决策:一个优化器的社会学观察》的文章,意外引发了跨学科讨论热潮。
这场跨界对话的起点,源于Adagrad优化器独特的自适应学习机制——这个2011年由Duchi等学者提出的算法,通过为每个参数分配独立的学习率,在处理稀疏数据时展现出惊人效率,而当代中国丁克家庭数量的攀升,恰如一组需要精准调参的社会数据:国家统计局2026年最新数据显示,30-40岁育龄人群中丁克家庭占比已达18.7%,较2016年增长了3.2倍,这两个看似无关的领域,在"自适应调整"这个核心逻辑上产生了奇妙共鸣。
Adagrad优化器:机器学习中的"智能调参师"
要理解这种共鸣,首先需要拆解Adagrad的技术内核,传统随机梯度下降(SGD)算法采用全局统一的学习率,就像用同一把尺子丈量所有参数的更新幅度,这在处理图像识别等密集数据时尚可应付,但面对自然语言处理中动辄数百万维的稀疏特征时,就会暴露出"步子太大容易越界,步子太小效率低下"的困境。
Adagrad的突破性创新在于引入了"历史梯度平方和"的累积机制,每个参数都会维护一个独立的累积变量,记录该参数过去所有梯度的平方和,学习率不再固定不变,而是随着训练进程动态衰减:对于频繁更新的参数,累积值增长快,学习率迅速下降;对于稀疏更新的参数,累积值增长慢,学习率保持较高水平,这种"区别对待"的策略,使得模型在处理非均衡数据时表现出色。
以2026年火遍全球的AI绘画工具MidJourney v7为例,其核心文本编码器就采用了Adagrad的变体,当用户输入"赛博朋克风格的北京胡同"时,模型需要同时处理"赛博朋克"(高频词)和"北京胡同"(低频词)两个特征,传统优化器可能因学习率设置不当,导致胡同的青砖灰瓦被霓虹灯完全覆盖,而Adagrad通过自适应调整,让两种风格在生成过程中保持恰当的平衡。
丁克决策:现代人的"参数优化"之路
将视角转向社会领域,当代年轻人的生育决策恰似一场复杂的参数优化过程,2026年《中国青年发展报告》显示,影响生育意愿的核心参数包括:经济基础(占比82%)、职业发展(76%)、教育成本(71%)、个人自由(68%),这些参数的更新频率和重要性各不相同,构成了一个典型的稀疏数据场景。
在上海陆家嘴工作的金融分析师李薇(35岁)和丈夫陈浩(38岁)的选择颇具代表性,这对夫妻年收入合计超过200万元,但面对生育问题时却异常谨慎。"我们就像Adagrad算法里的参数,"李薇在接受《第一财经》采访时比喻道,"经济参数可能每月更新一次,但教育参数可能十年才更新一次,而且每次更新的幅度都很大。" 自然教育与全民健身及气候行动热度持续上升,相关产业迎来新发展
本月碳中和目标与绿色能源热度持续上升,相关领域迎来新发展 他们的决策过程充满量化思考:首先计算育儿成本(包括学区房、国际教育、医疗储备等)约需500万元,相当于他们当前净资产的60%;然后评估职业发展影响,李薇预计晋升合伙人将推迟3-5年,直接经济损失超过300万元;最后考虑个人自由参数,两人每年用于旅行、进修的支出达20万元,生育后这部分预算将归零,经过三个月的"参数调试",他们最终选择维持丁克状态。
这种决策模式在北上广深的中产阶层中愈发普遍,2026年智联招聘的调查显示,78%的受访者表示会"像制定商业计划一样规划生育",其中43%的人使用了Excel模型或专业财务软件进行量化分析,这种理性决策趋势,与Adagrad处理稀疏数据的逻辑不谋而合——都是通过动态调整不同参数的权重,寻找全局最优解。

学习率衰减:社会压力下的生育阈值提升
Adagrad的核心机制之一是学习率的自适应衰减,这一特性在生育决策中表现为社会压力阈值的持续提升,2026年北京大学社会调查中心的数据显示,一线城市居民认为"经济条件足够好才生育"的收入门槛,已从2016年的月均2万元攀升至5万元,涨幅达150%。 2026年绿色消费圈与绿色营销链及气候行动热度持续上升,相关产业迎来新发展
这种阈值提升在杭州互联网从业者王磊(37岁)身上体现得淋漓尽致,作为某独角兽公司的技术总监,他年薪百万且持有期权,但面对生育问题仍犹豫不决。"十年前,同事们觉得有套两居室就能生孩子,"王磊在朋友圈写道,"现在没学区房、没保姆预算、没教育基金,根本不敢要孩子。"他的妻子是三甲医院的主治医师,两人计算发现,要达到"心理安全线"至少需要再积累五年。
这种集体性的阈值提升,形成了类似Adagrad中"累积梯度平方和"的效应,每个个体的谨慎决策都在增加整个社会的"学习压力",使得后续决策者需要更高的初始条件才能启动生育程序,2026年央行发布的《家庭资产负债表调查》显示,育龄家庭平均储蓄率已从2016年的28%升至42%,但生育意愿反而下降了19个百分点,这种悖论正是学习率衰减的典型表现。
稀疏数据挑战:生育意愿的"长尾分布"
Adagrad最初为解决稀疏数据问题而设计,而当代社会的生育意愿恰好呈现严重的长尾分布,国家卫健委2026年发布的《全国生育状况调查》显示,在20-40岁育龄人群中:
- 15%的人计划生育3个及以上孩子
- 32%的人计划生育2个孩子
- 41%的人计划生育1个孩子
- 12%的人坚定丁克
这种分布与自然语言处理中的词频分布高度相似——少数高频词(如"婚姻""工作")主导日常讨论,而生育决策这类低频但关键的事件,却需要特殊处理机制,Adagrad通过为低频参数保留较高学习率的策略,在机器学习领域解决了这类问题;而在社会领域,政策制定者开始尝试类似思路。

2026年上海市推出的"生育友好型城市"试点政策颇具启发性:对于生育二孩的家庭,提供学区房购买资格优先权(相当于调整教育参数的学习率);对于丁克家庭,则增加职业培训补贴和退休金加成(调整职业发展参数的学习率),这种差异化激励措施,本质上是在社会政策层面实施"自适应优化"。
局部最优与全局最优:生育决策的算法困境
Adagrad虽然能高效处理稀疏数据,但也可能陷入局部最优解——当某个参数的累积梯度平方和过大时,其学习率会过早衰减至接近零,导致模型无法探索更优解,这种困境在生育决策中表现为"生育陷阱":当社会普遍认为"30岁前不生育就来不及"时,许多年轻人因初期条件不足而放弃,反而错过了后续条件改善的机会。
北京协和医院妇产科主任林娜在2026年中华医学会年会上分享了一个典型案例:一位38岁的女性因十年前经济条件不佳选择丁克,如今事业有成却面临生育困难。"她就像被Adagrad过早冻结的参数,"林娜比喻道,"如果当时社会能提供冻卵等技术手段作为'学习率缓冲',或许结局会不同。" 本月绿色建筑与绿色办公及大数据分析热度持续攀升,相关应用不断深化
这种困境促使学者们探索更先进的优化算法,2026年清华大学社会学系提出的"Adam-生育模型",结合了Adagrad的自适应学习率和Momentum的动量机制,试图在个体决策与社会趋势之间找到平衡点,该模型在模拟实验中显示,当引入"社会支持动量"参数后,丁克家庭比例可从18.7%降至14.3%,同时保持经济效率指标不变。 本月虚拟电厂与绿色交通网及生物燃料热度持续走高,行业关注度持续提升
从算法到现实:一场未完成的优化实验
回到开篇那个看似荒诞的问题,Adagrad优化器确实不能直接解释丁克家庭增多的现象,但它提供的分析框架为我们理解复杂社会决策提供了新视角,就像机器学习需要不断迭代优化算法一样,社会政策也需要根据现实数据动态调整参数。
2026年两会期间,多位代表提出建立"生育决策支持系统",该系统将整合经济、医疗、教育等数据,为家庭提供个性化生育建议,这种设想与Adagrad的核心理念不谋而合——通过精准识别每个家庭的"关键参数",提供