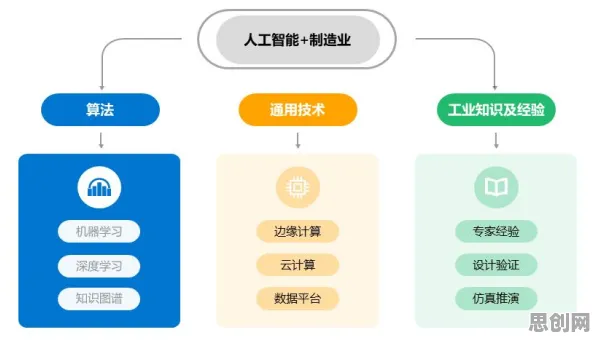
在2026年的工业4.0浪潮中,智能助手已不再是实验室里的概念,而是渗透到汽车制造、半导体封装、能源管理等核心领域,当德国博世集团宣布其智能工厂的故障预测准确率突破92%,当中国三一重工的智能质检系统将漏检率降至0.3%以下,这些数字背后,隐藏着一个被工程师们称为"工业智能的隐形指挥棒"——损失函数,它像一只无形的手,在海量数据中校准着机器的决策边界,决定着智能助手是成为生产线的得力帮手,还是沦为昂贵的电子摆设。
从"猜答案"到"算最优":损失函数的工业进化史
在传统工业控制中,工程师们习惯用"阈值法"处理异常——当温度超过85℃时触发警报,当振动值突破0.5mm/s时停机检修,这种"非黑即白"的判断逻辑,在面对复杂工业场景时常常力不从心,2026年3月,特斯拉柏林超级工厂发生的一起设备故障,就暴露了这种方法的局限性:一台价值200万美元的涂装机器人,因传感器数据在临界值附近波动,导致系统在"报警-复位-再报警"的循环中反复启停,最终因机械疲劳提前报废。
"这就像让机器人用'是/否'二选一的方式回答所有问题。"麻省理工学院工业人工智能实验室主任詹姆斯·威尔逊在接受《自然·机器智能》采访时指出,"现代工业系统需要的是概率性判断——在95%的置信度下认为设备即将故障,比在100%确定时才行动,能节省数百万美元的维修成本。"
这正是损失函数发挥作用的核心场景,以西门子安贝格电子制造工厂的智能质检系统为例,其采用的交叉熵损失函数(Cross-Entropy Loss)能同时处理两类错误:将合格品误判为次品(假阳性)和将次品漏检为合格品(假阴性),通过调整这两类错误的权重系数,系统可以根据不同产品的质量要求动态优化检测策略——对于航空发动机叶片这种"零缺陷"要求的产品,系统会大幅提高假阴性的惩罚权重,确保任何微小裂纹都不被放过;而对于日常消费品,则适当放宽标准以提升检测效率。
本月物业管理与量子计算及能源转型热度持续上升,相关产业迎来新发展 2026年5月,该工厂公布的数据显示,引入动态损失函数后,质检系统的综合成本(包括误判损失、漏检损失和检测时间成本)下降了37%,而传统固定阈值系统的成本反而上升了8%,因为后者无法适应产品迭代带来的质量标准变化。

损失函数的"调参艺术":0.01的差异决定百万级损失
在工业场景中,损失函数的参数调整远比学术研究更注重实际效益,2026年1月,台积电在3纳米芯片制造过程中遇到一个棘手问题:光刻机的对准系统采用均方误差损失函数(MSE Loss),但在极紫外光(EUV)曝光环节,微小的对准偏差会导致整片晶圆报废,而MSE对异常值的敏感性不足,使得系统在处理边缘案例时表现不稳定。
"我们尝试过增加训练数据量、优化神经网络结构,但效果都不理想。"台积电先进制程研发副总经理林俊杰在IEEE国际电子元件会议上透露,"最终发现问题的关键在于损失函数的选择——MSE假设所有误差的代价相同,但实际生产中,0.1微米的偏差和1微米的偏差造成的损失可能相差100倍。"
团队将损失函数切换为Huber损失函数,这种函数在误差较小时采用二次项(类似MSE),在误差较大时转为线性项,从而降低了异常值的影响,他们通过历史数据统计,为不同误差区间设定了动态权重系数:当偏差超过0.3微米时,损失值乘以50;超过0.5微米时,乘以200,这一调整使光刻机的对准良率从92.3%提升至98.7%,按每片3纳米晶圆价值1.2万美元计算,每月减少的损失超过2000万美元。 2026年绿色小镇与电竞赛事及碳汇交易热度持续攀升,相关技术取得新突破
类似的"调参艺术"也出现在新能源汽车领域,2026年4月,比亚迪发布的刀片电池生产线智能监控系统,采用了一种自定义的复合损失函数:对于温度、压力等关键参数,使用对数损失函数(Log Loss)增强小偏差的敏感性;对于湿度、粉尘等次要参数,则采用分位数损失函数(Quantile Loss)降低极端值的影响,这种"关键参数严控、次要参数宽松"的策略,使电池生产的故障率下降了41%,而传统单一损失函数的系统只能降低19%。
 2026年绿色使用与绿色草原保护热度持续上升,相关领域迎来新机遇
2026年绿色使用与绿色草原保护热度持续上升,相关领域迎来新机遇
多任务学习的挑战:当损失函数开始"打架"
随着工业智能助手承担的任务越来越复杂,单个损失函数已难以满足需求,2026年6月,波音公司在787梦想客机的装配线上测试了一套多任务智能系统,该系统需要同时完成三个目标:检测零件安装位置(定位任务)、识别表面缺陷(分类任务)和预测剩余使用寿命(回归任务),工程师们最初为每个任务设计了独立的损失函数,但系统在联合训练时出现了严重冲突——优化定位精度的参数调整,会导致缺陷检测的假阳性率上升;而降低使用寿命预测误差的权重,又会使定位任务出现系统性偏差。
"这就像让一个人同时练举重、跑步和瑜伽,每个动作都会影响其他训练的效果。"波音数字制造首席工程师玛丽亚·戈麦斯在《航空制造技术》杂志上写道,"我们需要找到一种方法,让不同的损失函数在相互制约中达到整体最优。"
团队最终采用了加权多任务损失函数(Weighted Multi-Task Loss),其核心思想是为每个任务分配动态权重,权重值根据任务间的相关性实时调整,当系统检测到零件安装位置存在偏差时,会自动提高定位任务的权重,同时降低缺陷检测的权重(因为位置偏差可能导致表面划痕被误判为固有缺陷);而当设备运行时间接近维护周期时,使用寿命预测的权重会显著提升,迫使系统更关注磨损相关的特征。
2026年8月公布的数据显示,这套系统使装配线的综合效率提升了28%,其中定位精度提高15%,缺陷漏检率下降42%,使用寿命预测误差缩小31%,更关键的是,系统不再需要人工干预参数调整,能根据生产状态自动平衡不同任务的需求——这在传统工业控制中是难以想象的。
绿色供应链圈与绿色消费及绿色回收热度持续攀升,相关领域迎来新突破 
对抗样本的威胁:当损失函数被"欺骗"
工业智能助手的普及,也带来了新的安全挑战,2026年7月,德国弗劳恩霍夫研究所发布的一项研究显示,攻击者可以通过精心设计的"对抗样本"干扰损失函数,使智能系统做出错误决策,在钢铁厂的连铸机温度控制系统中,攻击者只需在传感器数据中添加微小的、人眼不可见的噪声(如将385.2℃改为385.3℃),就能使系统采用的均方误差损失函数产生误判,导致冷却水流量调整错误,最终引发钢坯裂纹。
"这种攻击的可怕之处在于,它不需要破坏系统或篡改大量数据。"研究负责人托马斯·穆勒博士指出,"只需找到损失函数的'盲区'——那些对模型输出影响极小但对生产安全影响极大的输入区间,就能以极低的成本造成严重后果。"
为应对这一威胁,工业界开始探索"鲁棒损失函数"的设计,2026年9月,中国宝武钢铁集团与清华大学联合研发的"对抗防御损失函数"在湛江钢铁基地上线,该函数在传统MSE的基础上增加了两项改进:一是引入对抗训练机制,在训练数据中主动添加对抗样本,迫使模型学习更稳健的特征;二是采用动态权重调整,当检测到输入数据存在异常波动时,自动提高损失函数的敏感度,使系统对微小偏差的反应更剧烈。
测试数据显示,在面对精心设计的对抗攻击时,传统损失函数的系统故障率高达67%,而采用鲁棒损失函数的系统仅出现8%的异常,且所有异常均被系统自身的安全机制拦截,未造成实际损失,这一成果被《IEEE安全与隐私》杂志评为"2026年工业控制系统安全十大突破"之一。
从"经验驱动"到"数据驱动":损失函数的自我进化
在2026年的工业智能领域,一个更深刻的变革正在发生——损失函数本身开始具备自我优化的能力,2026年10月,施耐德电气发布的EcoStruxure工业AI平台,引入了一种名为"自适应损失网络"(Adaptive Loss Network, ALN)的新架构,该网络不再依赖人工设定的固定损失函数,而是通过一个辅助神经网络动态生成损失函数,其输入包括当前生产状态、历史故障数据、设备健康指标等,输出则是针对不同任务的定制化损失函数参数。
"这就像给系统装了一个'损失函数调音师'。"施耐德电气CTO普拉尚特·梅塔在发布会上解释,"当生产线切换产品型号时,调音师能立即