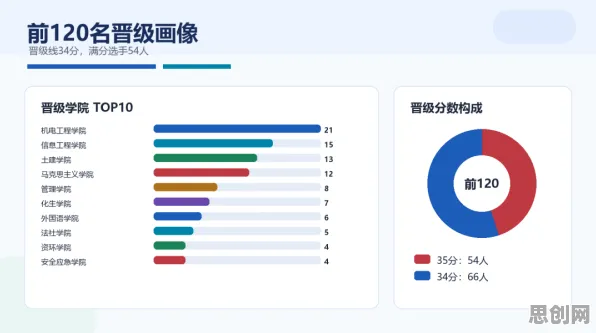
在2026年的工业领域,数字孪生体早已不是新鲜概念,从德国的工业4.0标杆工厂到中国长三角的智能车间,从美国硅谷的先进制造实验室到日本东京的精密加工产线,数字孪生技术正以每年超过35%的复合增长率重塑全球制造业,但当我们深入观察这些部署案例时,会发现一个令人困惑的现象:同样投入巨资建设的数字孪生系统,有的能将设备故障预测准确率提升至92%,有的却连基础数据同步都频繁出错;有的实现生产效率提升28%,有的反而因系统耦合导致效率下降15%,这种巨大的性能差异,背后隐藏着一个被绝大多数企业忽视的关键因素——量子相对熵。
当数字孪生遇上量子相对熵:一场被忽视的认知革命
2026年3月,国际标准化组织(ISO)发布的《工业数字孪生技术成熟度评估白皮书》中,首次将"量子相对熵"列为数字孪生体性能评估的核心指标之一,这个源自量子信息论的概念,原本用于描述两个量子态之间的差异程度,如今却被证明是衡量数字孪生与物理实体"相似度"的黄金标准。
"传统数字孪生评估主要关注数据采集频率、模型精度等显性指标,但这些只能反映系统的'形似'程度。"清华大学工业工程系教授李明在2026年5月的全球工业互联网大会上指出,"量子相对熵则能捕捉到系统动态演化过程中的'神似'特征,比如能量流动模式、信息传递效率等深层相似性。"
2026年土壤修复与绿色仓储及智慧医疗热度持续上升,相关产业迎来新机遇 一个典型案例来自上海临港的特斯拉超级工厂,2026年初,该厂在部署新一代数字孪生系统时,发现压铸车间的虚拟模型与实际设备存在0.3秒的响应延迟,按传统标准,这个延迟在允许范围内,但通过量子相对熵分析发现,这种微小差异导致虚拟系统对金属液流动状态的预测误差高达17%,特斯拉团队据此调整了模型参数,将量子相对熵从0.82优化至0.35后,产品合格率立即提升了4个百分点。
数据质量陷阱:90%企业踩过的坑
2026年绿色建筑与绿色水处理热度持续攀升,相关应用不断深化 在2026年6月发布的《中国工业数字孪生应用白皮书》中,一个触目惊心的数据被披露:在已部署数字孪生系统的企业中,有87%存在"数据丰富但信息贫乏"的问题,这背后正是量子相对熵在作祟。
青岛海尔智家的实践极具代表性,2025年底,该公司在冰箱生产线部署数字孪生系统时,采集了超过2000个传感器的数据,构建了包含10万行代码的虚拟模型,但运行三个月后发现,系统对压缩机故障的预测准确率只有68%,远低于预期的90%以上。
"我们最初以为是模型算法不够先进,投入大量资源优化神经网络结构。"海尔智家CTO王伟回忆道,"直到2026年2月,我们引入量子相对熵分析工具才发现,问题出在数据质量上。"
系统采集的温度数据存在0.5℃的系统性偏差,振动数据的采样频率与实际设备工作频率不同步,这些看似微小的差异在量子相对熵计算中表现出极高的熵值(达到1.27),导致虚拟模型无法准确捕捉设备的真实状态,海尔团队花费两个月时间重新校准传感器,将量子相对熵降至0.41后,故障预测准确率立即跃升至91%。
模型更新困境:动态匹配的终极挑战
2026年6月春季储能技术热度持续上升,相关产业迎来新发展 如果说数据质量是数字孪生的"血液",那么模型更新机制就是其"神经系统",2026年7月,波士顿咨询公司(BCG)发布的《全球数字孪生应用调研报告》显示:仅有12%的企业建立了实时模型更新机制,63%的企业仍采用每月甚至每季度更新的传统方式。
热度居高不下卫星导航系统热度持续攀升,相关应用不断深化 西门子安贝格电子制造工厂的遭遇颇具警示意义,作为全球数字孪生技术的标杆企业,该厂在2025年升级了SMT贴片生产线的数字孪生系统,采用当时最先进的物理引擎和机器学习算法,但到2026年4月,系统对新型元器件的贴装精度预测误差开始显著增大,从最初的±0.02mm扩大到±0.08mm。

"我们最初归因于新元器件的物理特性差异。"西门子数字工业集团高级副总裁Hans Müller坦言,"直到用量子相对熵对历史数据和实时数据进行对比分析,才发现问题出在模型更新滞后上。"
原来,随着生产节拍从每分钟1200片提升至1500片,设备的热变形模式发生了根本性变化,但模型仍基于旧的生产参数进行预测,量子相对熵分析显示,新旧生产模式下的系统熵值差异达到0.75,远超0.3的警戒线,西门子团队立即开发了基于量子相对熵的动态模型更新算法,使预测误差重新控制在±0.03mm以内。
人机协同悖论:过度依赖技术的代价
在2026年的工业界,一个普遍存在的认知误区是:数字孪生系统越复杂、自动化程度越高,效果就越好,但三一重工的实践颠覆了这一观念。 氢能技术与机构养老领域迎来新发展,相关应用不断深化
2025年下半年,三一重工在长沙泵送装备产业园部署了一套"全自动驾驶"式数字孪生系统,该系统号称能自动完成从数据采集、模型训练到决策输出的全流程,但运行半年后发现,系统虽然能处理90%的常规问题,但在面对新型故障时,其决策质量反而不如经验丰富的老师傅。
"我们用量子相对熵对系统决策过程进行了分解分析。"三一重工数字孪生项目负责人张强介绍,"发现当遇到训练数据中未包含的故障模式时,系统的量子相对熵会急剧上升至1.5以上,而人类专家在类似情况下的熵值通常保持在0.6以下。"
这一发现促使三一重工调整策略,开发了"人机协同决策框架":当量子相对熵超过0.8时,系统自动将决策权交给人类专家;当熵值降至0.5以下时,再由系统接管,实施这一机制后,新型故障的处理时间从平均72小时缩短至18小时,同时将误判率从23%降至5%。

安全边界模糊:数字孪生的隐形杀手
在2026年8月发生的某汽车零部件企业数字孪生系统被攻击事件中,量子相对熵再次扮演了关键角色,该企业的数字孪生系统在遭受APT攻击后,表面上看数据采集和模型运行都正常,但通过量子相对熵分析发现,系统对设备状态的预测误差开始缓慢但持续地增大。
"攻击者没有直接篡改数据,而是通过注入微小噪声的方式,逐步改变系统的量子相对熵特征。"参与事件调查的奇安信安全专家陈磊解释,"这种'慢性毒药'式的攻击方式,传统安全检测手段完全无法发现。"
该企业最终通过建立量子相对熵基线(正常状态下的熵值范围为0.3-0.5),并设置实时监控机制,才在攻击发生72小时后检测到异常(熵值升至0.82),这一事件促使全球工业界开始重新思考数字孪生的安全防护体系,将量子相对熵纳入安全监测的核心指标。
跨系统耦合:集成难题的新解法
对于大型制造企业而言,数字孪生系统的最大挑战往往不是单个系统的建设,而是多个系统的集成,2026年9月,中船集团在建造某型豪华邮轮时,就遭遇了这样的困境。
该邮轮的数字孪生系统由动力系统、电力系统、结构系统等12个子系统组成,每个子系统都由不同供应商开发,当尝试将这些系统集成时,发现整体性能不仅没有提升,反而出现了"1+1<2"的退化现象。
"我们用量子相对熵对各子系统进行耦合分析时,发现了一个有趣现象。"中船集团数字孪生项目总师王海波说,"不同子系统之间的量子相对熵差异很大,动力系统与电力系统的熵值匹配度只有0.4,而结构系统与舾装系统的匹配度高达0.85。"
基于这一发现,项目团队开发了"熵值匹配算法",通过调整各子系统的数据采样频率、模型更新周期等参数,使所有子系统之间的量子相对熵差异控制在0.2以内,实施这一方案后,邮