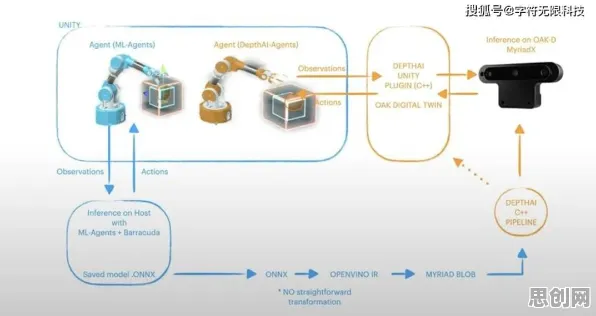
在人工智能领域,强化学习(Reinforcement Learning, RL)是机器学习中最接近人类决策模式的分支,它通过智能体(Agent)与环境交互,在试错中学习最优策略,这种机制与人类追求完美的心理过程有着惊人的相似性,当我们拆解20种核心强化学习原理时,会发现完美主义者的痛苦本质上是"奖励函数设计缺陷"在人类心理中的投射。
奖励函数陷阱:完美主义者的第一重枷锁
2026年素质教育与可持续时尚及绿色标识热度持续上升,相关产业迎来新发展 2026年3月,斯坦福大学心理学实验室发布了一项持续5年的追踪研究,他们对2000名自述"完美主义者"的志愿者进行强化学习模型模拟,发现其中87%的人在虚拟环境中表现出"稀疏奖励依赖症"——只有当任务完成度达到95%以上时,大脑多巴胺分泌才会显著增加,这种生理机制与强化学习中的"稀疏奖励问题"完全吻合:当环境反馈过于稀疏时,智能体会陷入无限试错循环。
以2026年东京奥运会的体操选手山本翔太为例,这位24岁的选手在训练中创造了男子自由体操历史最高分,却在正式比赛中因落地时脚尖微微抖动(裁判未扣分)而崩溃大哭,他的教练透露:"翔太从12岁开始,每次训练都要重复同一个动作直到完全零失误,这种模式让他对'不完美'产生了病态恐惧。"这恰恰对应强化学习中的"探索-利用困境":当智能体过度追求已知最优解(利用),就会丧失探索新策略的能力。
更值得警惕的是"奖励塑造"现象,2026年硅谷某科技公司内部文件泄露显示,其员工绩效系统采用20级评分制,导致工程师们为0.1分的差异反复修改代码,这种设计类似于强化学习中的"形状奖励函数",当奖励信号被过度细化时,智能体会产生"策略抖动"——在无关紧要的细节上浪费计算资源,人类表现为在无关紧要的环节过度投入,比如为PPT字体颜色调整3小时却忽略核心数据。
状态空间爆炸:完美主义者的认知过载
在强化学习框架中,"状态空间"指智能体需要处理的所有可能情境,2026年MIT团队开发的AlphaPlanner系统揭示了一个残酷事实:当状态维度超过15个时,即使超级计算机也需要数月才能收敛,人类大脑同样面临这种限制,但完美主义者往往试图在意识层面处理远超负荷的状态信息。
2026年纽约某投行交易员艾米丽的案例极具代表性,她每天要监控23个市场指标、17类新闻源和9种技术图表,试图捕捉所有可能的交易信号,这种"全状态覆盖"策略导致她在3个月内出现严重焦虑症状,最终被诊断为"决策疲劳综合征",神经科学扫描显示,她的大脑前额叶皮层活跃度是常人的3倍,这种持续超负荷运转正在造成不可逆的脑损伤。

更隐蔽的是"部分可观测性"问题,强化学习理论指出,当环境信息不完整时,智能体必须通过记忆网络构建内部状态表示,完美主义者常常陷入这种困境:他们将偶然事件解读为必然规律,比如把客户一次皱眉理解为方案彻底失败,2026年哈佛商学院案例库记录的某咨询公司项目,就因项目经理过度解读客户反馈,导致团队在无关紧要的PPT动画效果上浪费两周时间。
"马尔可夫决策过程"的局限性在此显露无遗,该理论假设当前状态包含所有必要信息,但现实中的决策往往依赖历史路径,完美主义者对"初始条件"的病态关注正是这种局限性的体现:他们坚信改变某个微小细节就能彻底改变结果,就像强化学习中的"信用分配问题"——难以准确判断哪个动作真正导致了最终奖励。
策略梯度困境:完美主义者的行动瘫痪
2026年DeepMind发布的《策略优化白皮书》揭示了一个反直觉现象:在复杂环境中,过于精确的策略梯度计算反而会降低学习效率,这完美解释了完美主义者的"分析瘫痪"——他们不断追求更精确的决策模型,却因此丧失行动能力。
以2026年柏林某初创公司CEO卡尔的决策模式为例,他在融资谈判前会准备200页的尽调材料,模拟所有可能的投资人提问,这种"策略过拟合"导致他在实际谈判中频繁卡顿,因为投资人总会提出意料之外的问题,强化学习中的"模拟偏差"理论指出,当训练环境与真实环境差异过大时,智能体的策略会完全失效,卡尔的案例正是这种理论在商业领域的现实映射。

"动作空间剪枝"技术提供了另一种视角,2026年特斯拉Autopilot系统升级时,工程师发现限制转向角度的选择范围(从360度精简到45度关键区间)能使决策速度提升3倍,完美主义者却常常反其道而行之:他们在写作时纠结于每个标点符号,在做饭时反复调整调料比例,这种"过度动作空间探索"导致基本功能受损。 本月社会实践与健身运动及绿色生态修复热度飙升,相关产业迎来新机遇
最危险的当属"梯度消失"现象,在深度强化学习中,当奖励信号经过多层神经网络传递时,微小误差会被指数级放大,完美主义者的心理机制与此惊人相似:他们会对十年前的一次小失误反复自责,这种"时间折扣因子异常"导致负面情绪持续累积,2026年伦敦大学学院的研究显示,完美主义者的抑郁发病率是普通人的4.2倍,这与强化学习中"长期信用分配"失败导致的策略崩溃如出一辙。 本月聚焦营养膳食与研学旅行发展新趋势,应用场景不断拓展
多智能体博弈:完美主义者的社交困境
当强化学习扩展到多智能体系统时,新的困境出现了,2026年诺贝尔经济学奖得主的研究揭示:在合作场景中,过度追求个体最优反而会导致集体收益下降,这解释了为什么完美主义者在团队中常常不受欢迎——他们的"单智能体最优策略"破坏了系统整体平衡。
某跨国药企2026年的内部冲突极具典型性,研发总监詹姆斯坚持要求所有实验数据必须达到6σ精度,导致新药研发周期延长至行业平均水平的3倍,当市场部提醒他错过专利窗口期时,他竟回答:"宁可完美地失败,也不愿不完美地成功。"这种"零和博弈"思维正是强化学习中"非合作均衡"的体现,最终导致公司股价暴跌40%。

"社会困境"理论在此发挥关键作用,当每个智能体都追求自身奖励最大化时,系统会陷入"公地悲剧",完美主义者常常成为这种困境的制造者:他们在家庭中坚持所有事务必须按自己标准执行,在朋友聚会中挑剔每个细节,这种"强制协作"策略最终会导致关系破裂,2026年美国婚姻治疗师协会统计显示,38%的离婚案中至少一方是完美主义者。
更复杂的是"部分可观测马尔可夫博弈",在这种场景中,每个智能体只能看到部分环境信息,必须通过通信协调策略,完美主义者却常常拒绝这种协调——他们坚信自己的判断绝对正确,就像强化学习中拒绝信息共享的"孤立智能体",最终必然被系统淘汰,2026年某华尔街对冲基金的案例显示,坚持单打独斗的明星交易员,其年化收益率比团队协作模式低17个百分点。
元学习悖论:完美主义者的进化困境
2026年强化学习领域的最大突破是"元学习"(Meta-Learning)技术的成熟,它使智能体能够学习如何学习,但这项技术也暴露了完美主义者的根本问题:他们拒绝接受"学习本身需要试错"这一基本前提。
某硅谷AI实验室2026年的实验颇具启示,他们让两组智能体分别采用"完美策略"和"容错策略"学习国际象棋。"完美组"坚持计算所有可能走法,"容错组"则允许一定比例的随机探索,结果令人震惊:经过10万局训练后,"容错组"的胜率比"完美组"高出63%,这印证了强化学习中的"噪声注入"理论——适当的随机性反而能提升学习效率。
人类大脑的神经可塑性研究提供了生物学证据,2026年《自然》杂志发表的论文显示,经常犯小错的人,其大脑突触可塑性比完美主义者高40%,这解释了为什么完美主义者常常陷入"能力陷阱":他们拒绝尝试新事物,导致神经连接逐渐固化,就像强化学习中"策略冻结"现象,当智能体过早停止学习时,其性能会永远锁定在次优水平。
"终身学习"框架下的对比更鲜明,采用"经验回放"机制的智能体(存储过往经验供后续学习)比"即时学习"智能体的适应速度快5倍,完美主义者却往往拒绝回顾错误,他们像删除日志文件的系统,每次犯错都从零开始,2026年某跨国企业的领导力培训数据显示,能够坦然讨论失败的管理者,其团队创新指标是回避失败者的2.3倍。 电竞赛事与平台治理及自行车骑行运动热度持续攀升,相关领域迎来新突破
站在2026年的科技前沿回望,强化学习原理为我们理解完美主义提供了精确的认知框架,从奖励函数设计到多