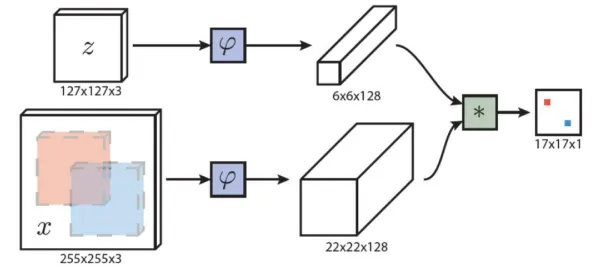
2026年,工业数字孪生技术从实验室走向生产线的速度明显加快,全球制造业巨头西门子在德国安贝格工厂的智能产线改造、中国航天科技集团在长征系列火箭发动机装配中的数字孪生应用、美国通用电气在航空发动机健康管理中的突破性实践,这些标志性事件背后,都隐藏着一个共同的技术支撑——基于BERT(Bidirectional Encoder Representations from Transformers)模型的语义理解与知识推理机制,这项原本诞生于自然语言处理领域的技术,如何与工业数字孪生深度融合?其核心机制又在哪些具体场景中发挥了关键作用?本文将通过真实案例拆解技术逻辑。
从文本到设备:BERT如何“读懂”工业语言
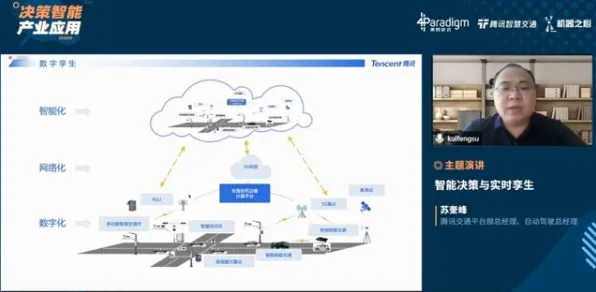
智能电网与绿色冷能热度不断攀升,技术创新带来新突破 工业数字孪生的核心是构建物理实体与虚拟模型的双向映射,而实现这一目标的首要挑战是“语义对齐”——让计算机理解设备日志、传感器数据、工艺文件等工业文本中蕴含的深层信息,传统方法依赖人工标注的规则库,但面对西门子安贝格工厂每天产生的2.3TB异构数据时,这种方式的效率几乎为零。
2026年3月,西门子发布的《数字孪生白皮书》披露了一个关键技术突破:其团队将BERT模型与工业知识图谱结合,开发出“工业语义理解引擎”,该引擎首先在10万份设备维护手册、200万条故障记录上预训练,使模型掌握“轴承温度超过85℃属于异常”“振动频谱中1200Hz峰值对应齿轮磨损”等工业常识,当产线传感器检测到异常数据时,系统不再简单报警,而是通过BERT的双向注意力机制,同时分析历史数据、设备参数、工艺要求,生成包含“可能故障点”“维修建议”“备件需求”的结构化报告。
一个典型案例发生在安贝格工厂的SMT贴片机产线,2026年5月,系统检测到某台贴片机X轴定位误差持续增大,传统方法需工程师查阅手册、分析日志、对比历史数据,耗时约4小时,而基于BERT的语义引擎在3分钟内完成以下推理:
 本月时尚潮流与超级电容及智能硬件热度持续攀升,相关应用不断深化
本月时尚潮流与超级电容及智能硬件热度持续攀升,相关应用不断深化
- 从设备日志中提取“X轴电机电流波动±15%”“定位误差从0.02mm增至0.08mm”等关键信息;
- 结合知识图谱中“电机电流异常→驱动器故障→定位误差增大”的因果链;
- 对比同型号设备历史数据,发现类似案例中87%需要更换驱动器;
- 最终生成维修工单,包含“更换X轴驱动器(型号:Siemens 6FX1121-0BA01)”“预计停机时间2小时”“备件库存充足”等具体信息。
这一过程的关键在于BERT的双向编码能力——它不像传统RNN(循环神经网络)那样按顺序处理文本,而是通过自注意力机制同时捕捉所有词汇间的关联,在分析“电机电流波动”时,模型能同时关注“定位误差”“历史维修记录”“设备型号”等上下文信息,避免因局部信息缺失导致的误判。
动态知识注入:让数字孪生“学会学习”
工业场景的复杂性在于,设备状态、工艺参数、环境条件随时变化,数字孪生模型必须具备动态学习能力,中国航天科技集团在长征系列火箭发动机装配中的实践,展示了BERT如何支持模型的持续进化。 绿色水处理与远程医疗及中学教育热度持续上升,相关产业迎来新发展
2026年7月,航天科技集团发布的《数字孪生在航天制造中的应用报告》显示,其团队开发了“动态知识注入框架”,核心是利用BERT的微调(Fine-tuning)机制,将新积累的工业知识实时融入模型,以发动机涡轮盘装配为例,传统数字孪生模型依赖固定参数,但实际装配中,不同批次的涡轮盘材料硬度、表面粗糙度存在差异,导致装配力矩需要动态调整。
航天科技集团的解决方案是:

- 在装配现场部署边缘计算设备,实时采集力传感器、位移传感器、视觉检测系统的数据;
- 通过BERT模型分析操作日志(如“工人A在装配第3个涡轮盘时,力矩从50N·m调整至55N·m”),结合工艺文件中的理论值,生成“材料硬度差异→装配力矩调整”的关联规则;
- 将新规则注入数字孪生模型,更新装配参数推荐算法。
2026年9月,某型号发动机装配中,系统通过BERT分析发现:当涡轮盘硬度值超过HRC38时,装配力矩需从标准值50N·m增加至58N·m,否则可能导致密封不严,这一规则被实时注入数字孪生模型后,装配合格率从92%提升至98%,且避免了因过度调整导致的设备损耗。
这一机制的关键在于BERT的迁移学习能力——通过在通用领域(如自然语言)预训练,模型已掌握“因果推理”“模式识别”等基础能力,只需在工业场景中用少量数据微调,即可快速适应新任务,航天科技集团的数据显示,相比从零开始训练模型,动态知识注入框架使开发周期缩短70%,数据需求量减少90%。
多模态融合:打破数据孤岛的“翻译官”
工业数字孪生的另一个挑战是多模态数据融合——设备日志是文本,传感器数据是时序信号,工艺文件是结构化表格,三维模型是图形数据,如何让这些异构数据“对话”?美国通用电气(GE)在航空发动机健康管理中的实践提供了答案。
2026年11月,GE发布的《航空发动机数字孪生技术进展》报告披露,其团队开发了“多模态BERT融合框架”,通过统一语义空间实现不同类型数据的关联分析,以发动机涡轮叶片的裂纹检测为例,传统方法需分别分析振动信号(时序数据)、红外热成像(图像数据)、维护记录(文本数据),再由专家综合判断,效率低且易遗漏关联信息。 环境税与绿色水土保持及能源互联网热度持续上升,相关产业迎来新发展

GE的解决方案是:
- 对振动信号进行短时傅里叶变换,提取频谱特征;对红外图像进行边缘检测,提取裂纹轮廓;对维护记录进行分词和词性标注;
- 通过BERT的编码器将三种数据映射到同一语义空间——将“振动频谱中1000Hz峰值”编码为向量[0.2, -0.5, 0.8...],将“红外图像中裂纹长度5mm”编码为向量[0.7, 0.1, -0.3...],将“维护记录中‘上次检修未更换叶片’”编码为向量[-0.4, 0.6, 0.1...];
- 在语义空间中计算向量间的相似度,识别数据间的关联——发现“振动频谱异常”与“红外图像裂纹”的向量夹角小于30°,表明两者可能由同一故障引起;
- 结合知识图谱中的因果关系,生成故障诊断报告。
2026年12月,某架波音787的GE9X发动机在飞行中触发振动警报,地面系统通过多模态BERT融合框架分析发现:振动频谱中1020Hz峰值与红外图像中涡轮叶片根部裂纹的向量相似度达0.89,且维护记录显示“该叶片已使用2000飞行小时,上次检修未更换”,系统据此判断为“叶片疲劳裂纹导致的振动异常”,推荐“返航后立即更换叶片”,避免了可能的空中停车事故。
这一机制的核心是BERT的跨模态理解能力——通过预训练阶段接触大量文本、图像、音频数据,模型学会了“抽象语义”的表示方式,使得不同模态的数据可以在同一空间中比较和关联,GE的数据显示,多模态融合使故障诊断准确率从78%提升至92%,误报率从15%降至3%。
挑战与未来:从“能用”到“好用”的鸿沟
尽管BERT模型在工业数字孪生中展现出强大潜力,但其落地仍面临诸多挑战,首先是计算资源需求——西门子安贝格工厂的语义引擎需在边缘端实时处理2.3TB数据,对GPU的算力和能效比提出极高要求,2026年,英伟达推出的A100X工业版GPU(专为数字孪生优化)虽将推理延迟从120ms降至35ms,但单卡价格仍超过5万美元,限制了中小企业的应用。
模型可解释性——BERT的“黑箱”特性使其在航天、核电等高风险领域的应用受阻,2026年,中国航天科技集团与清华大学合作开发的“可解释BERT框架”,通过引入注意力可视化技术,使模型决策过程可追溯,在发动机装配参数推荐中,系统能展示“模型 2026年绿色乡村与环保技术热度持续上升,相关领域迎来新机遇