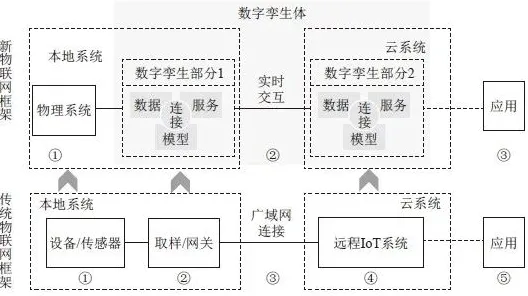
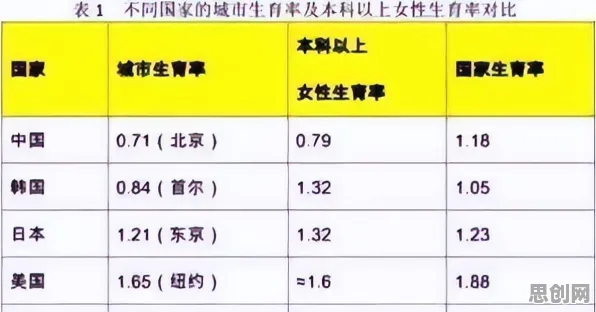
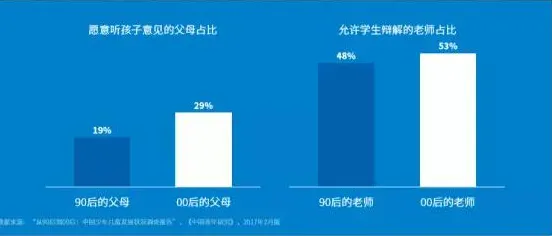
你有没有过这样的经历?晚上躺在床上,原本只想刷几条短视频放松一下,结果一抬头,发现已经过去了两三个小时,手机屏幕上的时间显示早已跳过了你设定的“再刷最后一条”的界限,这种“根本停不下来”的魔力,让短视频平台成了当代人最上瘾的“时间黑洞”,但你知道吗?这种让人欲罢不能的行为背后,其实藏着一个机器学习领域的经典算法——Q-learning,它原本是用来训练智能体在环境中做出最优决策的,但当我们把短视频平台看作一个“虚拟环境”,把用户当作“智能体”,把每一次滑动、点赞、停留当作“动作”,一切就都说得通了。 健身运动与污水处理热度不断攀升,技术创新带来新突破
Q-learning是什么?它是个“奖励猎人”
Q-learning的核心逻辑可以用一句话概括:通过不断尝试和反馈,找到能获得最大累积奖励的动作序列,它最早由克里斯·沃特金斯(Chris Watkins)在1989年提出,属于强化学习的一种,核心思想是让智能体(比如机器人、算法模型)在一个环境中,通过“试错”学习哪些动作能带来更高的“奖励”,从而在未来遇到类似情况时,优先选择这些动作。
举个现实中的例子,假设你养了一只小狗,想教它“握手”,一开始,小狗可能完全不懂你的意图,随便乱动爪子,但每次它偶然把爪子伸向你时,你立刻给它一块零食(奖励),几次之后,小狗会发现“伸爪子=有吃的”,于是开始主动伸爪子,这就是Q-learning的雏形——通过“动作-奖励”的关联,让智能体(小狗)学会最优行为。
在短视频场景中,用户就是那只“小狗”,而平台就是“训练师”,每一次滑动、点赞、评论、停留,都是用户向平台发出的“动作”;平台则通过算法,根据这些动作给出“奖励”——可能是更符合你兴趣的内容、更刺激的视觉效果,或者更强烈的情绪共鸣,而Q-learning的作用,就是让平台不断优化“奖励机制”,让用户越来越“上瘾”。

短视频平台的“奖励设计”:比养狗复杂100倍
如果说教小狗握手是“简单模式”,那短视频平台的“奖励设计”地狱难度”,它需要同时考虑用户的兴趣偏好、情绪状态、时间成本,甚至社交需求,通过算法实时调整“奖励”的强度和频率,让用户始终处于“差一点就满足”的兴奋状态。
2026年,某头部短视频平台的技术团队曾公开过一组数据(来源:平台官方技术白皮书):他们的推荐算法每天要处理超过10亿次用户互动,根据用户的每一次滑动、点赞、停留时长,实时更新“用户兴趣模型”,这个模型就像一个超级复杂的“奖励地图”,记录着用户对不同类型内容的偏好程度——你昨天刷了一条宠物视频,停留了30秒,还点了赞,算法就会认为“你对宠物内容感兴趣”,下次给你推送更多类似视频;如果你连续刷了5条宠物视频都没点赞,算法又会调整,减少宠物内容的推送,转而尝试其他类型。
但光有“兴趣匹配”还不够,平台还需要设计“奖励的节奏”,就像游戏里的“任务系统”,如果每次完成任务都立刻给奖励,玩家很快会失去兴趣;但如果奖励来得太慢,玩家又会觉得无聊,短视频平台的算法深谙此道——它会根据用户的“沉浸状态”动态调整推送频率,当你连续刷了10条视频都没点赞时,算法会判断你“可能有点无聊”,于是推送一条“爆款”视频(可能是搞笑段子、热点新闻,或者你之前点赞过的类似内容),用更强烈的刺激把你“拉回来”;而当你连续点赞了3条视频时,算法又会适当“克制”,推送一些“中等质量”的内容,避免你过早“满足”,从而延长你的使用时间。
2026年3月,一位名叫小林的25岁用户曾在社交媒体上分享过自己的“刷视频日记”,他记录了自己连续3天刷短视频的行为数据,发现了一个有趣的现象:第一天,他刷了2小时,其中前30分钟点赞了8条视频,后90分钟只点赞了2条;第二天,平台在他刷到第40分钟时推送了一条“宠物搞笑合集”(他之前点赞过宠物内容),他立刻点赞并停留了5分钟;第三天,他发现平台在他连续刷了5条“低质量”视频后,突然推送了一条“高赞神作”,让他忍不住又刷了半小时,小林说:“感觉平台像有读心术,总能在我快放弃的时候,给我一颗‘糖’。”

“即时奖励”与“延迟满足”的博弈:为什么我们总被“拿捏”?
Q-learning中有一个关键概念叫“Q值”(Q-value),它代表智能体在某个状态下执行某个动作后,能获得的未来累积奖励的预期值,Q值越高,说明这个动作越“值得做”,在短视频场景中,用户的每一次滑动、点赞,都在无形中更新自己的“Q值表”——“刷宠物视频”的Q值是8分(因为能带来快乐),“刷新闻视频”的Q值是5分(因为需要思考,不太轻松),“刷广告视频”的Q值是1分(因为无聊且浪费时间),平台的任务,就是通过算法,让用户认为“继续刷短视频”的Q值永远高于“做其他事”(比如看书、运动、睡觉)。
但这里有个矛盾:从长期来看,过度刷短视频可能带来时间浪费、注意力分散等负面影响,这些属于“延迟惩罚”;而短视频带来的即时快乐(比如搞笑内容、视觉刺激)属于“即时奖励”,人类的大脑天生更倾向于追求即时奖励,尤其是当“延迟惩罚”不明显时(刷1小时视频不会立刻变笨”),我们很容易被“即时奖励”牵着走。
2026年5月,某神经科学实验室曾做过一项实验(来源:《自然·人类行为》期刊),他们招募了50名志愿者,让他们分别在“刷短视频”和“阅读书籍”两种状态下接受脑部扫描,结果显示,刷短视频时,志愿者的“多巴胺分泌区”(负责快乐和奖励的脑区)活跃度比阅读时高40%;而“前额叶皮层”(负责理性决策和延迟满足的脑区)活跃度则低30%,这意味着,短视频带来的即时快乐会抑制我们的理性思考,让我们更倾向于“继续刷”,而不是“停下来”。 游戏产业与绿色防洪抗旱及绿色制造热度持续攀升,相关应用不断深化
本月关注清洁能源与绿色处理及旅游休闲发展动态,技术创新推动产业升级 更“狡猾”的是,平台还会利用“间歇性强化”来强化这种行为,就像赌场里的老虎机,偶尔吐一次硬币,比每次都吐硬币更让人上瘾——因为“不确定的奖励”会刺激大脑分泌更多多巴胺,短视频平台深谙此道:它不会让你每次刷都遇到“神作”,而是偶尔推送一条“爆款”,让你觉得“下次可能还有更好的”,从而不断滑动、等待。

2026年7月,一位名叫李女士的35岁用户曾在接受采访时说:“我明明知道刷短视频浪费时间,但就是控制不住,每次想退出时,总会刷到一条特别搞笑的,或者特别感人的,然后就想‘再刷一条就睡’,结果一刷就是半小时。”李女士的经历,正是“间歇性强化”的典型表现——平台通过不确定的“高奖励”内容,让她始终处于“期待-满足-再期待”的循环中,无法自拔。
打破“Q-learning陷阱”:我们该如何自救?
既然短视频平台的“上瘾机制”是基于Q-learning设计的,那我们能不能用同样的逻辑“反制”它?答案是肯定的——关键在于重新训练自己的“Q值表”,让“做其他事”的Q值高于“刷短视频”。
第一步是“意识到奖励的存在”,就像教小狗握手前,你需要先明确“伸爪子=有吃的”,我们也需要先意识到:短视频带来的快乐是“人工设计”的,它的目的是让你停留更久,而不是真正让你幸福,2026年,某心理机构曾推出过“21天戒短视频挑战”,参与者需要每天记录自己刷视频的动机(无聊”“逃避压力”“单纯喜欢”),并分析这些动机是否合理,很多参与者反馈,当他们意识到“我刷视频是因为无聊,而不是因为视频本身有趣”时,戒断的难度就降低了一半。
第二步是“设计自己的奖励机制”,既然平台用“即时奖励”吸引我们,我们也可以给自己设计“更健康的即时奖励”,如果你想培养阅读习惯,可以规定“每读10页书,就允许自己刷5分钟视频”;或者“连续3天每天读书1小时,就奖励自己看一场电影”,这种“以小换大”的策略,能让大脑逐渐接受“延迟满足”也能带来快乐。
本月绿色社区与绿色救援热度持续上升,相关产业迎来新发展 第三步是“打破间歇性强化的循环”,平台用“偶尔的高奖励”让我们上瘾,那我们就可以主动减少“刷视频”的随机性,设定固定的刷视频时间(比如每天晚上8-8:30),其他时间完全不碰;或者只关注固定的几个优质创作者,避免被算法“投喂”大量低质量内容,2026年,一位名叫张先生的40岁用户曾分享过自己的经验:他卸载了所有短视频APP,只在周末用