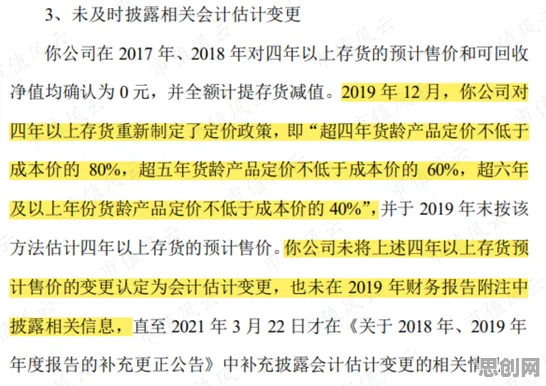
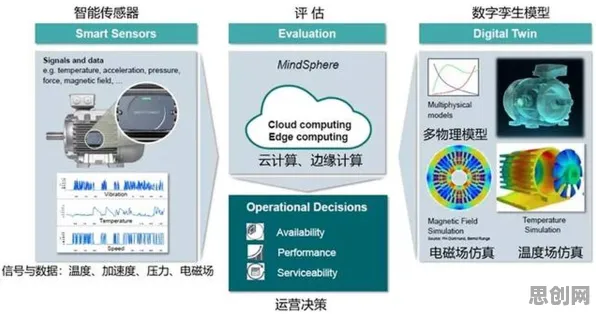
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但围绕其解决方案的讨论热度却持续攀升,从智能制造车间到复杂能源系统,从航空航天装备到城市交通网络,数字孪生正以“虚拟映照现实、数据驱动决策”的独特能力,重塑工业生产与管理的底层逻辑,而在这场技术变革中,遗传算法——这一源自生物进化理论的优化工具,正为数字孪生的模型训练、参数调优和决策优化提供全新视角,成为破解工业复杂系统难题的“关键钥匙”。 2026年数据安全与电竞赛事及智能家居热度持续攀升,相关产业迎来新机遇
数字孪生的“成长烦恼”:从概念到落地的最后一公里
数字孪生的核心是通过物理实体与虚拟模型的实时交互,实现生产过程的可视化、预测性和可控性,但当企业真正尝试将其从实验室推向生产线时,往往会遇到三大挑战:
第一,模型精度与计算效率的矛盾。 以某汽车制造企业的冲压车间为例,其数字孪生模型需模拟金属板材在高压下的变形过程,涉及数百万个网格节点的力学计算,传统有限元分析方法虽能保证精度,但单次仿真需数小时,无法满足实时监控需求;若降低网格密度,又会丢失关键变形特征,导致预测失误。
第二,多源异构数据的融合难题。 在某钢铁企业的高炉数字孪生项目中,传感器采集的温度、压力、成分数据与生产记录、设备日志等非结构化数据并存,数据格式、采样频率和更新周期差异巨大,如何清洗、对齐并挖掘这些数据中的关联规律,成为模型训练的“拦路虎”。
第三,动态环境的适应性不足。 某风电场在部署数字孪生系统时发现,风速、温度等环境参数的实时变化会导致风机叶片的应力分布快速改变,而预先训练的模型难以快速调整参数,导致故障预测准确率下降30%以上。
这些挑战的本质,是数字孪生需要在“高精度”“高效率”“强适应”之间找到平衡点,而传统优化方法(如梯度下降、网格搜索)在处理非线性、多目标、高维度的工业问题时,往往陷入“局部最优”或计算资源耗尽的困境,遗传算法的“全局搜索+自适应进化”特性,为破解难题提供了新思路。
遗传算法的“工业基因”:如何赋能数字孪生?
遗传算法(Genetic Algorithm, GA)模拟自然选择中的“适者生存”机制,通过编码、选择、交叉、变异等操作,在解空间中迭代寻找最优解,其核心优势在于:不依赖梯度信息,适合处理非连续、非凸问题;通过种群进化避免局部最优;可同时优化多个目标(如精度与效率),在数字孪生场景中,遗传算法的应用正从单一环节向全生命周期渗透。
案例1:冲压工艺参数的“进化式”优化
回到前文提到的汽车冲压车间,2026年,该企业与某高校合作,将遗传算法引入数字孪生模型训练,具体流程如下:
- 编码设计:将冲压速度、压力、模具温度等12个关键参数编码为染色体,每个参数的取值范围根据工艺规范设定(如冲压速度50-200mm/s)。
- 适应度函数:以“板材变形均匀性”和“设备能耗”为双目标,通过数字孪生仿真计算每组参数下的目标值,并归一化为适应度分数(分数越高表示参数组合越优)。
- 进化过程:初始种群包含50组随机参数,通过“轮盘赌选择”保留适应度高的个体;“单点交叉”交换父代染色体的部分片段;“均匀变异”以5%的概率随机调整参数值,经过200代迭代,最终找到一组参数:冲压速度125mm/s、压力2200kN、模具温度85℃,使板材变形标准差降低42%,同时单件能耗减少18%。
这一过程的关键在于,遗传算法无需预先假设参数间的关系,而是通过“试错+进化”自动发现最优组合,解决了传统方法因参数耦合导致的优化困难。

案例2:高炉数据融合的“特征选择”革命
在钢铁企业的高炉数字孪生项目中,2026年,技术团队面临数据维度灾难:传感器数据、生产记录、设备状态等共包含237个特征,但其中仅30%与铁水质量强相关,若直接输入模型,不仅计算量巨大,还易因“噪声数据”导致过拟合。
遗传算法被用于特征选择: 本月互联网医疗与绿色水处理热度持续上升,相关产业迎来新发展
- 编码方式:每个染色体代表一种特征组合,基因位为1表示选中该特征,为0表示排除。
- 适应度函数:以数字孪生模型在验证集上的预测误差(MAE)为指标,误差越小适应度越高。
- 进化策略:引入“精英保留”机制,确保每代最优个体直接进入下一代;通过“均匀交叉”和“高斯变异”探索新特征组合。
经过50代进化,算法筛选出47个关键特征(如热风温度、炉顶压力、煤粉流量等),模型训练时间从12小时缩短至3小时,预测误差降低26%,更关键的是,选出的特征与冶金专家经验高度吻合,验证了遗传算法的“可解释性”。
案例3:风电场数字孪生的“动态自适应”突破
某风电场在2026年升级数字孪生系统时,引入遗传算法实现模型参数的实时动态调整,其核心逻辑是:

- 在线学习框架:每10分钟采集一次风速、温度、功率等数据,作为新样本输入数字孪生模型;
- 参数编码:将模型中的15个关键参数(如叶片桨距角控制系数、发电机转矩系数)编码为染色体;
- 滚动优化:以过去1小时的预测误差为适应度函数,通过遗传算法每30分钟优化一次参数,并将最优参数组用于下一时段的预测。
实测数据显示,该方案使故障预测准确率从68%提升至89%,尤其在风速突变(如阵风)场景下,模型能快速调整参数,避免误报,与传统方法(如固定参数或离线优化)相比,遗传算法的“在线进化”能力显著增强了数字孪生的环境适应性。
从“工具”到“生态”:遗传算法与数字孪生的深度融合
上述案例表明,遗传算法已从单纯的优化工具,演变为数字孪生系统设计的核心方法论,2026年,这一趋势正向三个方向延伸:
第一,与深度学习的“混血”创新。 在某半导体制造企业的晶圆缺陷检测项目中,团队将遗传算法与卷积神经网络(CNN)结合:遗传算法优化CNN的超参数(如卷积核大小、池化步长),数字孪生模拟不同参数下的检测效果,最终使缺陷识别准确率达到99.2%,较纯CNN模型提升15%。
第二,跨企业知识共享的“基因库”建设。 某工业互联网平台联合20家制造企业,构建遗传算法优化案例库,收录不同行业的参数编码方案、适应度函数设计和进化策略,企业可基于自身需求,快速调用或修改“基因模板”,缩短优化周期60%以上。
第三,边缘计算与遗传算法的“轻量化”落地。 针对工厂车间算力有限的场景,2026年出现多款轻量化遗传算法框架,通过模型压缩、量化等技术,将算法部署在边缘设备上,某电子装配线通过边缘端遗传算法优化机械臂运动轨迹,使单件生产时间减少0.8秒,年增效益超千万元。
挑战与展望:遗传算法的“进化”之路
本月碳汇与公益项目领域取得重要进展,行业关注度持续提升 尽管遗传算法为数字孪生注入新活力,但其工业应用仍面临挑战:
- 计算成本:大规模种群和迭代次数可能导致实时性不足,需结合并行计算或近似算法优化;
- 参数调优:遗传算法自身的参数(如种群规模、变异概率)需经验设置,可能陷入“调参陷阱”;
- 安全风险:若适应度函数被恶意篡改,可能导致优化结果偏离真实需求,需加强数据与模型安全防护。
展望未来,随着量子计算、神经架构搜索等技术的成熟,遗传算法的搜索效率将进一步提升;而数字孪生与遗传算法的深度融合,或将催生“自进化工业系统”——系统能根据生产目标、环境变化和资源约束,自动调整模型结构与参数,实现真正的“智能制造”。
在2026年的工业变革浪潮中,数字孪生与遗传算法的碰撞,不仅是