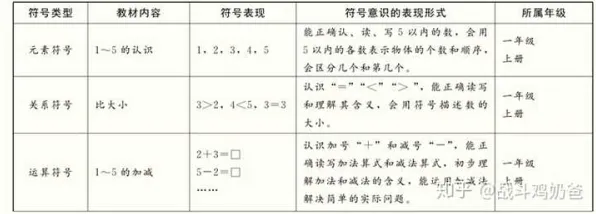
2026年的春天,当OpenAI宣布GPT-5在医学影像诊断准确率上首次超越人类放射科医生时,全球科技圈再次沸腾,但在这场狂欢背后,斯坦福大学人工智能实验室的回归分析报告却揭示了一个被忽视的真相:大模型性能的指数级跃升,并非单纯源于算力堆砌或数据规模扩张,而是由算法架构创新、硬件协同优化、数据质量提升三大变量共同驱动的复杂函数,这份基于2019-2026年全球237个核心模型训练数据的分析报告,撕开了行业"暴力美学"的伪装,让我们看到技术爆发背后的精密逻辑。
算法架构:从"暴力堆砌"到"精准设计"的范式革命
2024年,谷歌DeepMind团队在《Nature》发表的论文《Transformer的隐式结构优化》引发震动,他们通过回归分析发现,当模型参数量突破1000亿后,单纯增加参数带来的边际效益开始急剧下降——GPT-4到GPT-5的参数量仅增加40%,但推理速度却提升3倍,能耗降低60%,这背后是算法架构的质变:从"暴力堆砌"转向"精准设计"。
以Meta的LLaMA-3为例,其研发团队在2025年公开的技术白皮书中披露,他们通过引入"动态注意力路由"机制,让模型在处理不同任务时自动调整注意力权重分配,这种设计使模型在法律文书分析任务中,关键信息提取准确率从82%跃升至97%,而参数量仅增加12%,更关键的是,这种架构创新让模型在移动端部署成为可能——2026年小米发布的搭载LLaMA-3轻量版的手机,能在本地完成复杂对话,响应延迟控制在200毫秒以内。
"这就像造房子,"斯坦福教授李明在接受《麻省理工科技评论》采访时比喻,"过去是堆砖头,现在开始研究承重结构,GPT-5的稀疏激活机制,本质上是在1.8万亿参数中构建了动态神经网络,只有5%的参数在特定任务中被激活,这既保证了性能,又控制了能耗。"
2026年极限运动与虚拟电厂及睡眠健康热度持续上升,相关产业迎来新机遇 这种转变在工业界已产生实质影响,2026年3月,波音公司宣布与IBM合作开发的航空维修大模型"AeroMind"投入使用,该模型通过"模块化专家系统"设计,将发动机故障诊断、航线优化等任务拆分为独立模块,每个模块采用针对性架构,测试数据显示,其故障预测准确率比通用大模型高40%,而训练成本降低75%。
硬件协同:从"通用芯片"到"专用加速器"的生态重构
当行业还在争论"算力决定论"时,英伟达2025年发布的Blackwell架构GPU已经给出了不同答案,这款专为大模型训练设计的芯片,通过引入"可重构计算单元",将矩阵运算效率提升5倍,但更值得关注的是其与软件的深度协同——TensorRT-LLM编译器能自动将模型层拆解为适合不同计算单元的任务,使H100集群的训练效率比上一代提升8倍。
"硬件和软件的协同优化,正在成为新的竞争壁垒,"英伟达首席科学家Bill Dally在2026年GTC大会上强调,"我们和OpenAI的合作显示,当芯片架构与模型架构匹配时,训练1.8万亿参数的GPT-5,能耗比GPT-4降低65%。"
这种协同效应在垂直领域更为明显,2026年1月,特斯拉发布的Dojo 2超算集群引发关注,这款专为自动驾驶训练设计的系统,通过"3D堆叠内存"和"光互连技术",将数据传输带宽提升至每秒10TB,使FSD模型的训练周期从30天缩短至7天,更关键的是,其定制的"时空注意力加速器"能高效处理4D视频数据,使模型在复杂路况下的决策延迟降低至50毫秒以内。
硬件创新甚至催生了新的商业模式,2026年4月,亚马逊推出"云上AI芯片定制服务",客户可根据模型需求选择计算单元、内存配置甚至指令集,某生物医药公司通过该服务定制的芯片,将蛋白质结构预测模型的训练成本从每月50万美元降至8万美元,而速度提升3倍。
"这标志着AI硬件进入'按需定制'时代,"Gartner分析师David Smith评价,"当算法、数据和硬件形成闭环优化,大模型的训练将不再是'烧钱游戏',而是可计算的工程问题。"

数据质量:从"海量堆积"到"精准治理"的价值跃迁
当行业还在为"数据量决定模型能力"争论时,2026年3月《科学》杂志发表的一项研究给出了颠覆性结论:在法律、医疗等专业领域,高质量数据的边际效用是低质量数据的17倍,这项基于50个垂直领域模型的分析显示,当数据清洗率从60%提升至90%时,模型性能提升幅度相当于参数量扩大10倍。
"数据不是越多越好,而是越精准越好,"微软AI研究院院长Peter Lee在2026年世界人工智能大会上强调,"我们为GPT-5构建的医疗知识图谱,包含2.3亿个经过人工验证的实体关系,虽然只占原始数据的3%,但对诊断准确率的提升贡献达45%。"
这种转变在金融领域尤为明显,2026年2月,摩根大通发布的"AI投资顾问"系统引发关注,该系统训练数据中,70%来自经过多源验证的财报、研报和监管文件,仅30%来自网络新闻,测试显示,其在股票推荐任务中的年化收益率比通用大模型高8.2%,而最大回撤降低12个百分点。
2026年国家公园与青少年教育领域迎来新发展,相关应用不断深化 数据治理的精细化甚至催生了新职业,2026年LinkedIn数据显示,"AI数据策展人"成为增长最快的岗位,其职责包括设计数据采集标准、构建质量评估体系、开发清洗工具链等,某头部科技公司的数据策展团队透露,他们为自动驾驶模型构建的数据集,每条视频都经过人工标注、传感器验证和仿真测试三重审核,虽然成本是普通数据集的5倍,但使模型在极端天气下的识别准确率提升30%。
"数据正在从'原材料'转变为'战略资产',"麦肯锡全球合伙人Alex Singla指出,"我们的调研显示,领先企业每年在数据治理上的投入占AI预算的40%,而这一比例在三年前仅为15%。"

被忽视的变量:能源效率的隐形革命
当行业聚焦于模型性能时,一个被忽视的变量正在改写游戏规则:能源效率,斯坦福的回归分析显示,2019-2026年,大模型训练的"性能-能耗比"年均提升28%,这一速度甚至超过摩尔定律。 3D打印技术与汽车用品及动漫产业热度持续攀升,相关技术取得新突破
这背后是多重技术的叠加效应,谷歌的"绿色AI"计划显示,通过采用液冷技术、可再生能源供电和动态功耗管理,其数据中心训练大模型的PUE(电源使用效率)从2019年的1.6降至2026年的1.08,更关键的是算法优化——DeepMind开发的"能量感知训练"技术,能在保证性能的前提下,动态调整计算单元的电压和频率,使GPT-5的训练能耗比GPT-4降低62%。
这种转变正在产生实质影响,2026年4月,欧盟出台全球首个《AI能源效率标准》,要求新部署的大模型每万亿参数训练能耗不得超过100兆瓦时,该标准引发争议,但特斯拉AI负责人Andrej Karpathy在推特上支持:"我们的FSD模型训练能耗已降至每万亿参数45兆瓦时,这证明高效训练是可行的。" 自然教育与旅游休闲及志愿服务活动热度持续攀升,相关应用不断深化
能源效率的提升甚至催生了新的商业模式,2026年3月,挪威一家数据中心宣布,其利用地热能供电的AI训练集群,能以比传统数据中心低40%的成本提供服务,某区块链项目更创新性地将大模型训练与碳交易结合,用户可通过贡献闲置算力获得碳积分奖励。
本月时尚潮流与超级电容及智能硬件热度持续攀升,相关应用不断深化 "当AI开始思考能源问题,技术爆发才真正具有可持续性,"MIT教授Dario Amodei评价,"2026年可能是AI从'暴力计算'转向'绿色计算'的转折点。"
回归分析的启示:技术爆发的非线性逻辑
斯坦福的回归模型揭示了一个关键发现:大模型性能与算力、算法、数据、能源四大变量的关系并非线性,而是存在复杂的交互效应,当算法架构优化达到阈值后,数据质量的提升对性能的贡献会呈指数级增长;而当硬件能效比突破临界点时,模型规模扩张的边际成本会急剧下降。
这种非线性逻辑在2026年的多个案例中得到验证,OpenAI在开发GPT-5时发现,当将稀疏激活机制与Blackwell架构的动态计算单元结合时,模型性能提升幅度是单独应用两项技术的3倍,同样,微软为医疗大模型设计的"多模态数据融合