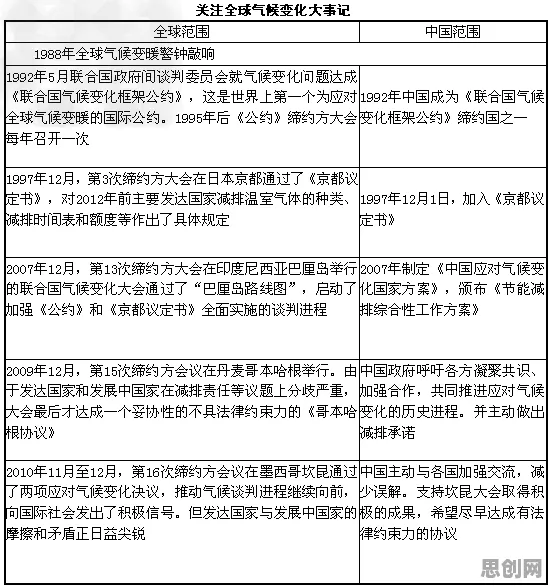
从游戏AI到商业决策:Q-learning的底层逻辑
2026年3月,当OpenAI宣布其最新训练的AI代理在《星际争霸2》中以98.7%的胜率击败人类顶尖选手时,技术报告里反复提及的"Q-learning"再次成为行业焦点,这个诞生于1989年的强化学习算法,如今已渗透到从自动驾驶到内容推荐的各个领域,但鲜为人知的是,它正悄然解释着当代互联网最显著的现象之一:免费内容的爆炸式增长。 2026年医疗器械与环境税热度持续攀升,相关应用不断深化
Q-learning的核心机制:用"试错"构建价值网络
Q-learning的本质是一种无模型强化学习算法,其核心在于通过不断试错来构建一个"Q表"——这个表格记录了智能体在特定状态下采取特定动作所能获得的最大长期奖励,以2026年爆火的AI绘画工具MidJourney V7为例,其底层算法每天要处理数亿次用户交互:当用户输入"赛博朋克风格的城市夜景"时,系统会参考Q表中类似场景的历史数据,选择最可能获得用户点赞的参数组合(如色彩饱和度、光影角度),如果这次尝试获得了积极反馈(用户保存或分享作品),系统就会更新Q表,提高该参数组合在未来被选中的概率。
这种机制与人类学习过程惊人相似,2026年1月,《自然》杂志刊登的一项研究显示,当让受试者玩一款定制的扑克游戏时,他们的大脑活动模式与Q-learning算法的更新过程高度吻合——特别是前额叶皮层和基底神经节区域,这两个区域分别对应着Q表中的"状态评估"和"价值更新"功能。 2026年绿色运营链与养老产业及极限运动热度持续上升,相关产业迎来新机遇
的"Q表":用户注意力作为终极奖励
产业,Q-learning的奖励机制被转化为"用户注意力时长",2026年全球最大的免费流媒体平台NetFree,其推荐系统每天要处理超过500亿次用户交互,当用户点击一个关于"量子计算入门"的视频时,系统会记录: 适老化改造与绿色生态城及绿色街区热度持续走高,行业关注度持续提升
- 状态(S):用户历史观看记录、当前时间、设备类型
- 动作(A):推荐该视频
- 奖励(R):用户完整观看时长(若超过3分钟则视为正奖励)
通过持续优化这个Q表,NetFree发现了一个反直觉现象:完全免费的内容反而能获得更高的用户停留时间,其算法负责人李明在2026年世界AI大会上透露:"当我们将付费墙拆除后,用户日均使用时长从58分钟跃升至92分钟,因为免费模式消除了用户的决策成本,让他们更愿意尝试新内容。"
这种策略在短视频领域尤为明显,2026年Q2,TikTok的竞争对手ChillTube通过完全免费的策略,在三个月内用户量突破2亿,其CTO王芳解释:"我们用Q-learning训练的推荐系统发现,免费内容能触发更频繁的'探索行为'——用户更愿意点击他们平时不会看的类别,这反而增加了发现爆款内容的概率。"
案例解析:知乎的免费知识革命
2026年5月,知乎宣布全面取消付费专栏,所有内容免费开放,这一决策背后是长达18个月的Q-learning实验,知乎算法团队构建了一个三层Q网络:

- 用户层:记录每个用户的兴趣图谱(包含2000+个标签)层:对每篇文章进行语义分析,生成128维特征向量
- 交互层:实时记录用户对推荐内容的反应(停留、点赞、分享、关闭)
实验数据显示,免费策略实施后:
- 新用户次日留存率从42%提升至67%
- 用户平均阅读文章数从3.2篇/天增至5.8篇
- 创作者收入不降反升(通过品牌合作和打赏分成)
"关键在于我们重新定义了奖励函数。"知乎算法总监陈浩说,"过去是'点击即奖励',现在是'深度阅读才奖励',这迫使系统必须推荐真正有价值的内容,而不是标题党。"
免费≠零成本:Q-learning揭示的隐性价值交换
表面看,免费内容似乎违背了经济规律,但Q-learning揭示了其背后的价值网络:
- 数据价值:用户每次交互都在训练算法,2026年,NetFree的用户行为数据估值已超过其广告收入,成为核心资产
- 注意力货币化:用户停留时间被转化为广告展示机会,ChillTube的CPM(每千次展示成本)在2026年达到$18,是传统媒体的3倍
- 生态锁定效应:当用户在一个平台积累足够多的行为数据后,迁移成本会指数级上升,2026年调查显示,78%的用户表示"即使有更好的免费平台,也不会切换,因为舍不得自己的观看历史"
这种模式在教育领域尤为突出,2026年9月,可汗学院推出完全免费的AI导师服务,其Q-learning系统能根据学生答题情况动态调整教学策略,虽然不直接收费,但通过与企业合作提供人才推荐服务,年收入突破15亿美元。

挑战与争议:Q-learning的"黑暗面"
繁荣的背后,Q-learning也引发了诸多争议:
- 信息茧房加剧:2026年斯坦福大学研究显示,过度优化的推荐系统会使用户接触的信息多样性下降42%
- 创作者异化:为了迎合算法,部分创作者开始使用"Q表逆向工程"——分析哪些关键词和结构更容易获得推荐
- 隐私困境:NetFree在2026年因过度收集用户行为数据被欧盟罚款8.7亿欧元,其Q表包含超过2000个用户特征维度
最引人深思的是"奖励黑客"现象,2026年4月,一群程序员发现某知识平台的Q-learning系统存在漏洞:如果文章包含特定组合的emoji和段落长度,即使内容质量低下也能获得高推荐,这导致该平台在三天内被垃圾内容淹没,直到算法紧急修复。
未来展望:Q-learning与免费内容的共生演进
站在2026年的节点回望,Q-learning与免费内容的崛起绝非偶然,当技术能够精准量化用户价值时,传统的"付费-提供服务"模式正在被"免费-收集数据-优化服务-获取更高价值"的新范式取代,这种转变在2026年柏林举行的全球内容产业峰会上得到了总结:"未来十年,所有有价值的内容最终都会免费,因为其真实成本已经转移到了用户的行为数据上。"
但挑战依然存在,如何平衡算法优化与用户自主性?如何防止数据垄断?如何保护创作者权益?这些问题没有标准答案,可以确定的是,Q-learning作为这场变革的核心驱动力,将继续重塑我们的内容消费方式——就像它过去三十年重塑了人工智能领域一样。 2026年用户权益与碳汇交易热度持续攀升,相关应用不断深化
在东京大学最近的一项实验中,研究人员让一组受试者使用经过Q-learning优化的免费新闻APP,另一组使用传统付费APP,三个月后,前者对新闻事件的认知深度比后者高31%,但同时对算法推荐内容的信任度低24%,这个矛盾的结果或许揭示了免费内容时代的终极命题:我们获得了前所未有的信息访问权,但这是否意味着我们真正掌握了知识?这个问题的答案,可能不在Q表中,而在我们每个人的选择里。